Abstract
- Self-Attentive Sequential Recommendation(SASRec)를 통해 사용자의 마지막 행동을 통해 예측하는 Markov Chains(MCs)와 장기적인 정보를 예측하는 RNN의 균형을 이루고자 합니다.
- Transformer의 self-attention 매커니즘을 sequential recommender systems에 적용합니다.
- 제안된 모델은 기촌 추천시스템에서 좋은 성능을 보여주던 MC/CNN/RNN based model을 뛰어넘는 실험 결과를 보여주었습니다.
INTRODUCTION
- sequential recommender systems의 목표와 어려운 점
순차적 추천 시스템은 사용자의 행동에 대한 맥락을 고려하여 새로운 제품을 추천합니다. 하지만 사용자의 과거 행동들은 기하급수적으로 늘어나기 때문에 입력 공간의 크기가 매우 커지기에 개발하기에 어려움이 있습니다.
- Markov Chains(MCs)
사용자의 이전 행동만 가지고 다음 행동을 예측합니다. 강력한 단순화를 가정함으로써 높은 희소성 환경에서 잘 수행되지만 복잡하거나 고밀도 환경에서는 성능이 떨어집니다.
- Recurrent Neural Networks(RNNs)
hidden state를 활용하여 이전의 모든 행동들을 고려해 다음 행동을 예측합니다. RNN은 표현적이기는 하나 고밀도의 많은 데이터가 요구됩니다.
저자는 이 둘의 단점을 보완하고자 새로운 모델을 추천 시스템에 적용하게 됩니다.
- 새로운 순차적 모델, Transformer
새로운 순차적 모델 Transformer는 self-attention을 사용하여 의미 있는 패턴을 효율적으로 발견할 수 있습니다. 아래 그림은 저자가 제시한 Self Attentive Sequential 추천 시스템(SASRec)의 학습 과정입니다.
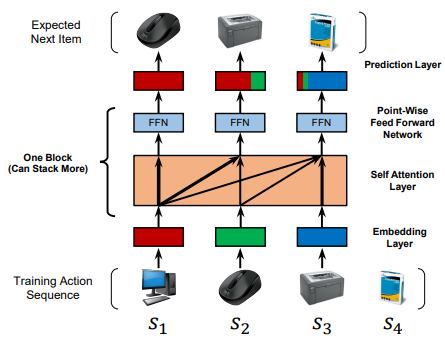
Transformer
Attention is all you need에서 발표된 Transformer 참고자료
Methodolgy
- A. Embedding Layer
고정 길이 시퀀스 :
학습을 위해 action set의 사이즈 : 으로 고정
아이템 임베딩 매트릭스 :
input 임베딩 메트릭스 :
Positional Embedding :
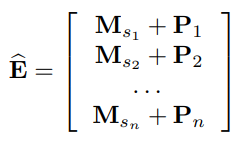
B. Self-Attention Block
다음으로 Self-Attention Block을 거치게 되는데 이는 Attention Is All You Need에서 등장한 Trasformer의 구조와 거의 유사합니다.
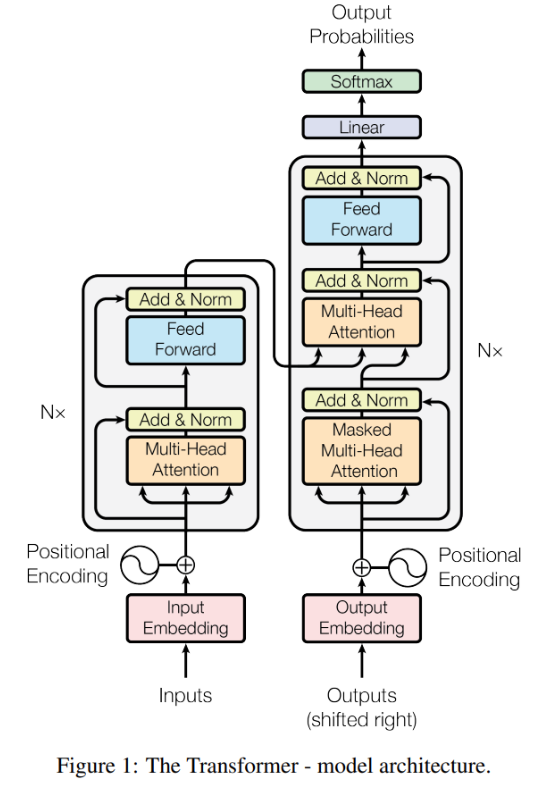
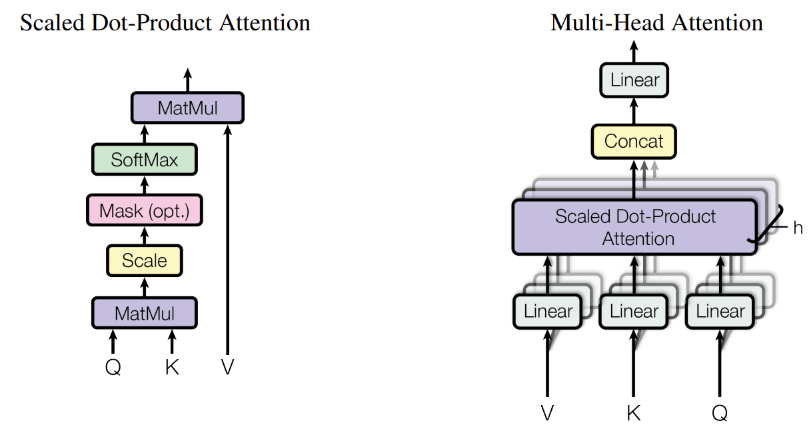

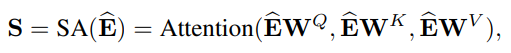
Causality : 실제 추천 알고리즘이 작동할 때는 미래의 유저 행동을 볼 수 없기 때문에, 저자는 미래의 유저 행동을 사용하는 것은 모순적이라고 생각해, 현재 이후 시점에 대해서는 masking을 진행했습니다.
D. Prediction Layer
다음에 올 유저 행동을 예측하기 위해 적절한 item의 score를 최종적으로 예측하게 됩니다. 따라서 block의 출력 값 에 사이즈가 인 과 연산해줍니다.
Shared Item Embedding : 모델의 사이즈와 오버피팅을 예방하고자 Shared Item Embedding 매트릭스 을 사용합니다.
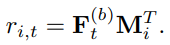
E. Network Training
모델의 loss의 경우 사용자가 관심 있는 항목(positive sampling)과 관심 없는 항목(negative sampling)을 통해 binary cross entropy를 계산하고, Adam 옵티마이저를 사용하여 모델을 최적화합니다.
아래 loss의 식에서 좌측의 항은 positive samples과 우측 항은 negative samples를 의미합니다.
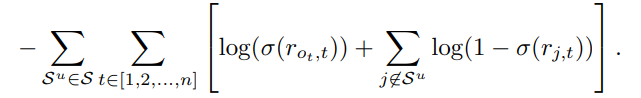
EXPERIMENTS
RQ1: Does SASRec outperform state-of-the-art models including CNN/RNN based methods?
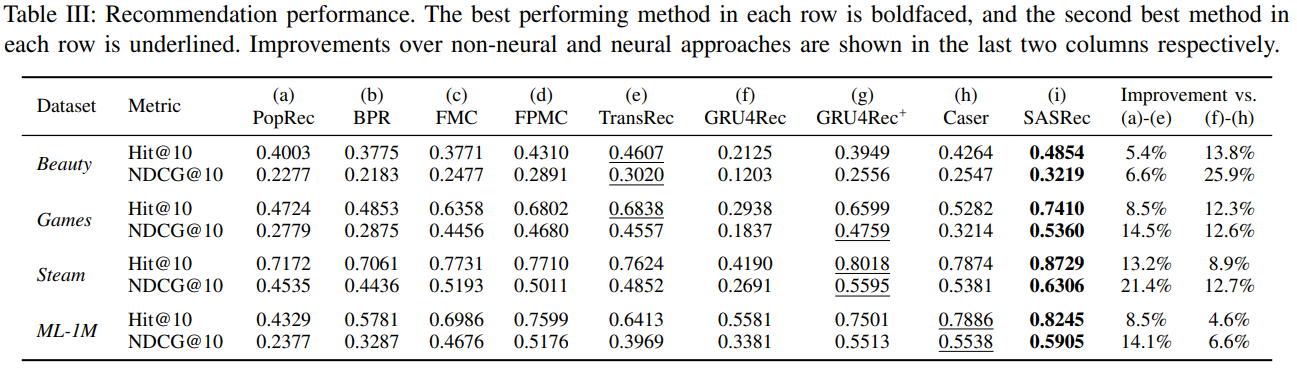
모델 성능 비교 결과 저자가 제안한 SASRec 모델이 모든 데이터셋에서 가장 우수한 성능을 보였으며, 특히 기존의 신경망 기반의 추천시스템(f-h)에서 좋은 성능 개선을 이뤘습니다.
모델이 다양한 데이터셋의 다양한 범위 내의 항목에 적응적으로 참여하기에 희소한 데이터셋과 고밀도 데이터셋 모두에서 모든 기준선을 능가합니다.
RQ2: What is the influence of various components in the SASRec architecture?
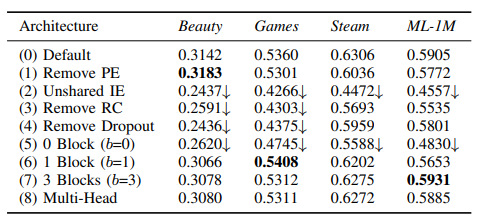
(1) PE 제거(Positional Embedding) : positional embedding P가 없으면 각 항목에 대한 attention weight는 항목 임베딩에만 의존합니다.
(6) 1 block : 하나의 블록이 있는 변형은 특히 고밀도 데이터 세트에서 성능을 향상시키지만, 계층적 self-attention 구조는 더 복잡한 항목 전환을 학습하는 데 도움이 됩니다.
RQ3: What is the training efficiency and scalability (regarding n) of SASRec?
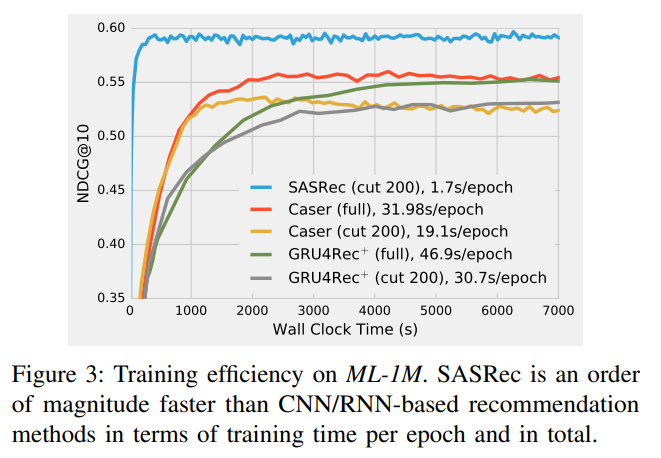
Training Efficiency : SASRec는 1 Epoch 모델 업데이트에 1.7초밖에 걸리지 않습니다. 이는 Caser(19.1s/epoch)보다 11배, GRU4Rec+(30.7s/epoch)보다 18배 빠른 속도입니다. 또한 SASRec은 ML-1M에서 약 350초 이내에 최적의 퍼포먼스로 수렴되지만 다른 모델에서는 훨씬 더 오랜 시간이 소요됩니다.
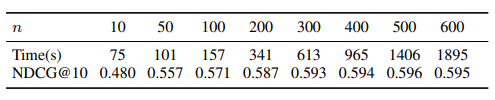
Scalability : 표준 MF 방식과 마찬가지로 SASRec은 총 사용자 수, 항목 및 작업에 따라 선형적으로 확장됩니다. 이 클수록 성능이 향상됩니다.(최대 까지) 이때 성능이 포화됩니다.(행동의 99.8%가 적용되었기 때문에 더욱 향상됨) 그러나 인 경우에도 Caser 및 GRU4Rec+보다 빠른 2,000초 만에 모델을 훈련시킬 수 있습니다. 따라서 저자의 모델은 사용자 sequence로 쉽게 확장할 수 있으며, 이는 일반적인 리뷰 및 구매 데이터셋에 적합합니다.
RQ4: Are the attention weights able to learn meaningful patterns related to positions or items’ attributes?
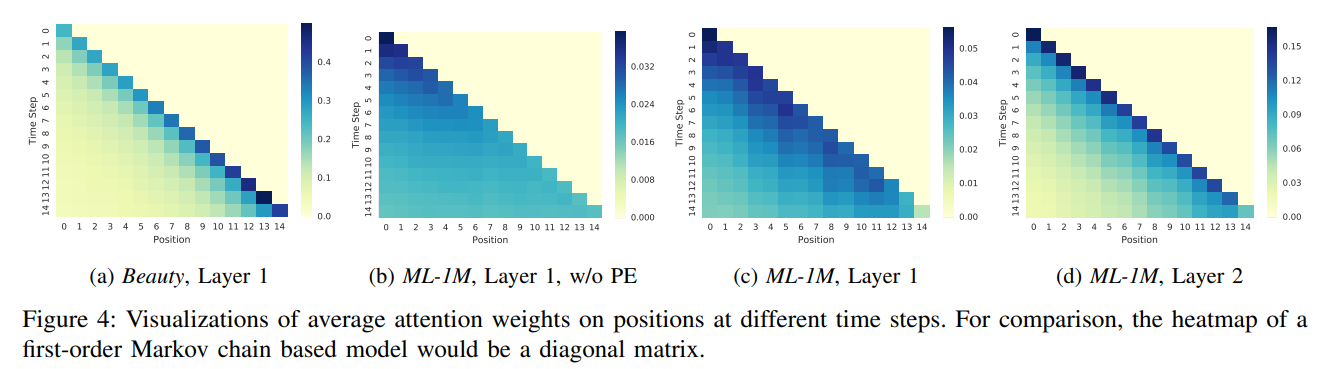
- (a) vs. (c) : sparse했던 Beauty 데이터셋에서는 최근 2~3개 아이템 정보를 기반으로 예측하는 것을 알 수 있고, 비교적 dense했던 MovieLens 데이터셋에서는 최근 정보를 더 많이 관측했음을 알 수 있습니다. 기존 방법은 스펙트럼의 한쪽 끝에 초점을 맞추는 경향이 있는 반면, 저자의 모델이 희박한 데이터셋과 고밀도 데이터셋을 적응적으로 처리할 수 있게 해주는 핵심 요인입니다.
- (b) vs. (c) : positional embeddings의 효과를 알아보기 위함입니다. positional embedding이 없는 (b)의 경우 attention map이 uniform하게 나타나 있는 것을 알 수 있음. 이는 순서에 대한 가중치가 없으면 학습이 안 됨을 의미합니다.
- (c) vs. (d) : Layer 수에 따라 학습의 정도가 다른 것을 알 수 있습니다. (c)의 경우, input sequence에 대해 전체 아이템들의 관계를 학습하기 때문에 넓은 attention 분포를 확인할 수 있습니다. 반면, (d)의 경우 Layer1에서 이미 전체 정보를 받아왔기 때문에 Layer2에서는 최근 정보만을 주목하는 것을 알 수 있습니다. 이는 예측에 영향을 미치는 중요(세부) 정보는 최근 아이템임을 의미합니다.
Summary
- 새로운 self-attention 기반 sequential model인 SASRec을 제안합니다.
- 희소 및 밀도 데이터 세트에 대한 광범위한 경험적 결과는 이 모델이 sota 기준선을 능가하며 CNN/RNN 기반 접근 방식보다 훨씬 빠르다는 것을 보여줍니다.
