논문 리뷰
1.[논문 리뷰] Self-Attentive Sequential Recommendation
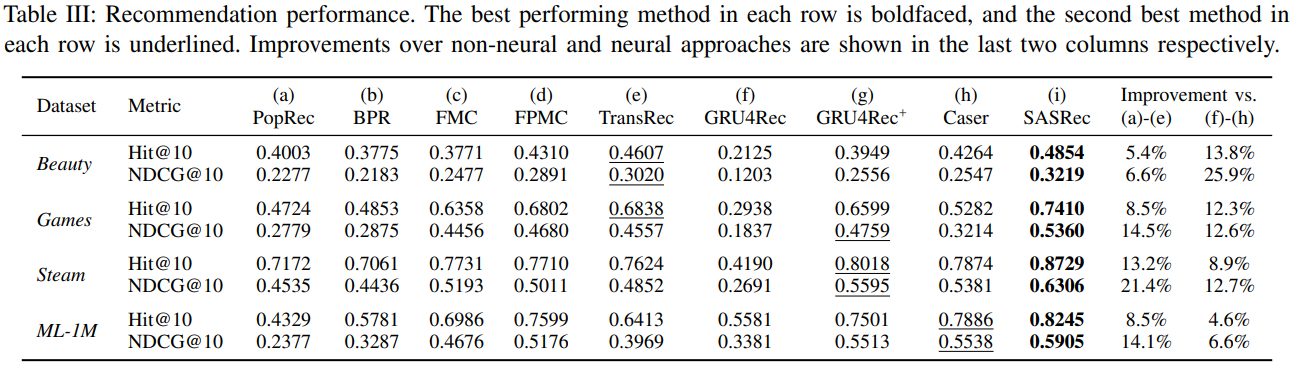
Abstract Self-Attentive Sequential Recommendation(SASRec)를 통해 사용자의 마지막 행동을 통해 예측하는 Markov Chains(MCs)와 장기적인 정보를 예측하는 RNN의 균형을 이뤘음. I. INTRODUCTION 순차
2022년 3월 20일
2.[논문 리뷰] Fully Convolutional Networks for Semantic Segmentation
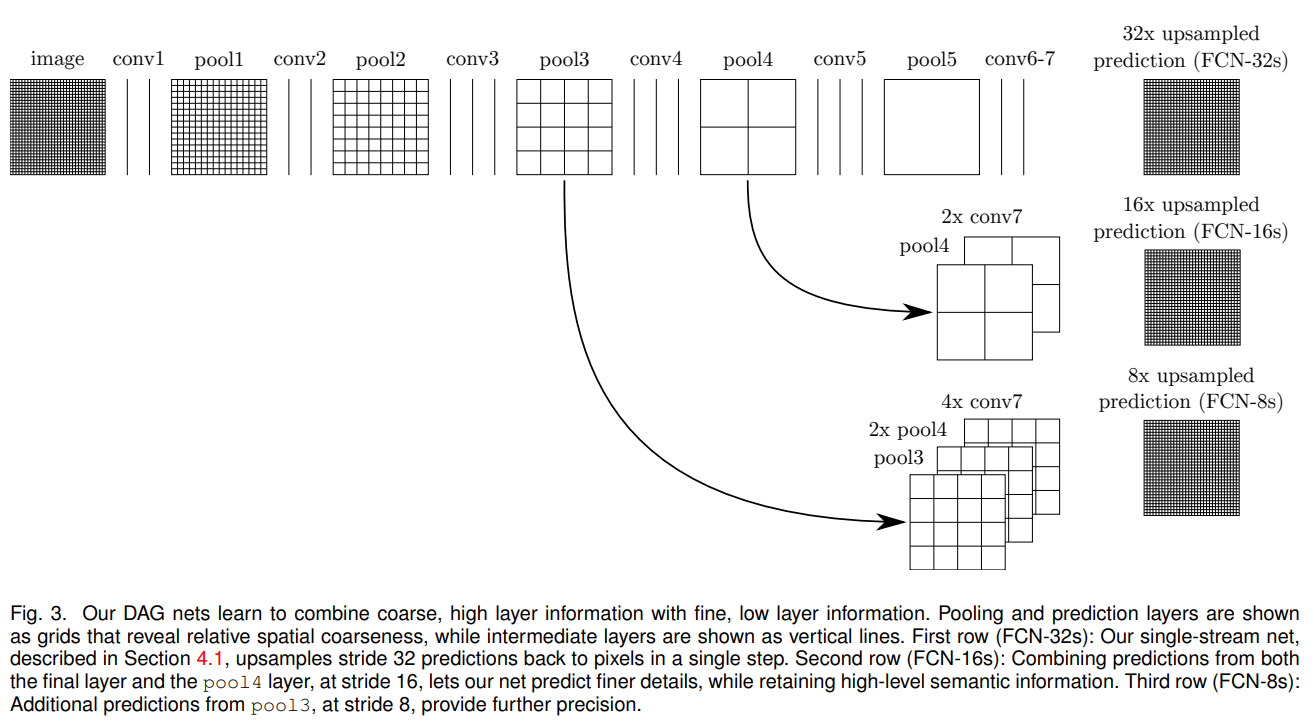
Abstract FCN은 end-to-end, pixel-to-pixel로 학습 가능한 Convolutional network임. end-to-end : Segmentation을 위해 사용되는 filter들이 learnable함. 독립적인 딥러닝 모델을 이용하
2022년 3월 22일
3.[Paper Review] (2018, IEEE) Self-Attentive Sequential Recommendation (SASRec)
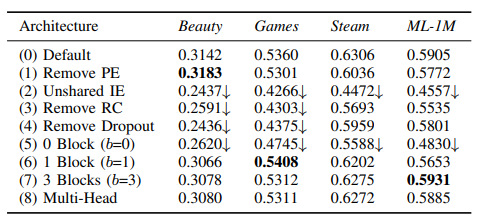
Abstract Self-Attentive Sequential Recommendation(SASRec)를 통해 사용자의 마지막 행동을 통해 예측하는 Markov Chains(MCs)와 장기적인 정보를 예측하는 RNN의 균형을 이루고자 합니다. Transformer의
2022년 5월 9일
4.Digging Into Self-Supervised Monocular Depth Estimation
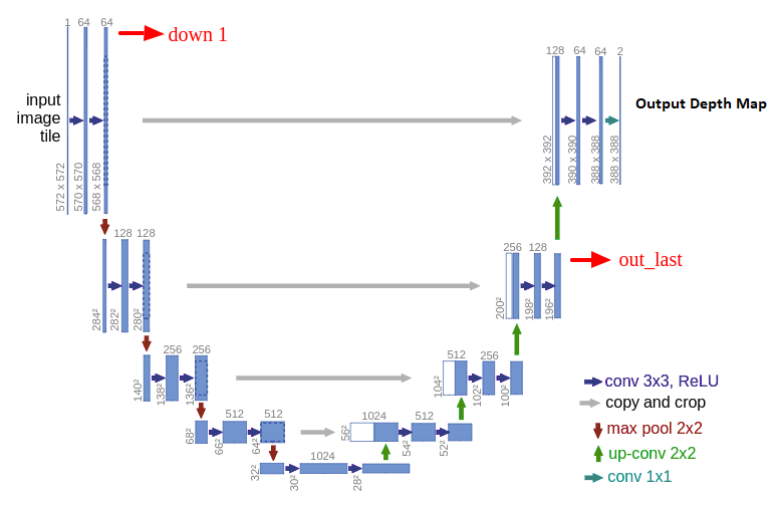
단안 영상에서 depth를 추정하기 위해 한 프레임과 다음 프레임 간의 disparity를 구하는 Unsupervised Learning(Self-Supervised)방식의 딥러닝 접근 방식monodepth2에서는 단일 프레임에서 depth를 예측하기 위해 depth
2023년 1월 5일