Abstract
FCN은 end-to-end, pixel-to-pixel로 학습 가능한 Convolutional network임.
* end-to-end : Segmentation을 위해 사용되는 filter들이 learnable함. 독립적인 딥러닝 모델을 이용하지 않고(not cascade), 하나의 딥러닝 모델 이용함.
* pixel-to-pixel : 이미지의 pixel마다 classification 학습을 진행함.저자는 최종 segmentation 결과가 모든 pixel을 classification하는 방식인 dense prediction task라고 설명함.
핵심 아이디어는 임의의 크기로 입력 값을 받고, 그에 해당하는 출력값을 생성하는 Fully Convolutional Network임.
AlexNet, GoogLeNet, VGGnet과 같은 classification 신경망을 사용하고, 이들을 segmentation task에 맞게 fine-tunning함.
shallow 정보와 deep 정보를 결합하는 새로운 구조를 정의함.
semantic information과 appearance information을 결합하여 사용함.
* semantic information(의미론적 정보) from **deep, coarse layer** : 깊은 레이어에서 뽑은 피쳐들은 외관을 파악하기 힘듦, 하나의 의미를 갖는 정보들을 보여줌, 세밀하지 않음
* appearance information(외관 정보) from **shallow, fine layer** : edge 피쳐들이 추출됨, 세밀한 피쳐들을 잘 추출하여 fine layer라고 함.1 INTRODUCTION
Semantic segmentation은 coarse부터 fine까지 inference를 통해 모든 pixel에 대해 예측을 생성하는 것임. 이전까지 semantic segmentation에 사용했던 convet은 각 pixel에 레이블링 했음. 하지만 이 방법은 해결해야 할 단점이 있음.
pixel마다 classification을 하는 dense prediction을 수행함.
Fully Convolutional Networks(FCNs)
* end-to-end, pixel-to-pixel 기반의 semantic segmentation
* 사이즈의 제약을 받지 않는 입력 이미지(arbitrary-sized inputs)에서 dense prediction을 수행함
* pixelwise prediction과 supervised pre-training을 이용함.
* dense feedforward computation과 backpropagation을 통해 전체 이미지에 대한 학습과 추론을 한 번에 진행함.
* upsampling lyaer는 subsampled pooling을 사용하여 pixelwise prediction 및 학습을 가능하게 함.저자의 모델은 분류망을 fully convolutional로 재해석하고 학습된 표면에서 미세 조정함으로써 최근의 분류 성공을 밀도 예측으로 전환함.
skip architecture을 이용하여 deep layer의 semantic information(=coarse)와 shallow layer의 appearance information(=fine)을 잘 혼합하여 segmentation에 사용 가능함
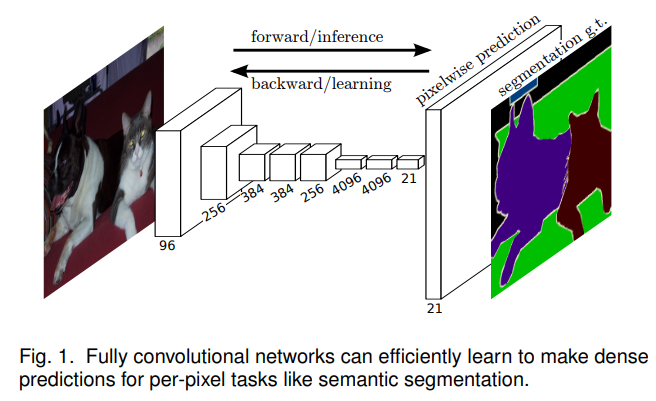
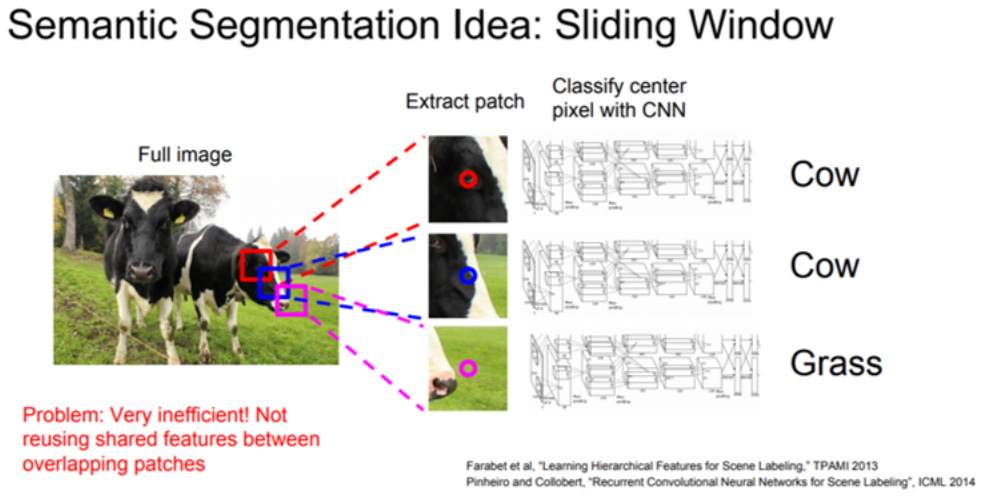
FNC 이전의 segmentation 학습 방법론
- Patchwise learning : 특정 크기의 patch를 설정하고 CNN에 입력 입력으로 들어간 patch는 CNN에 의해 clasiffication 특정 class로 분류되었다면, 해당 patch 중앙에 위치한 pixel을 해당 class로 분류 이러한 과정을 sliding window 방식으로 반복함
-
Patchwise learning의 문제점
- 모든 patch들을 CNN에 넣어 일일이 분류하기에 계산량이 많음.
- patch 크기를 키우면 두 개의 class가 동시에 들어가 분류가 애매하며, patch끼리 겹치는 부분이 커져 중복 계산됨.
- patch 크기를 줄이면 low resolution되어 classification accuracy가 떨어짐.
-
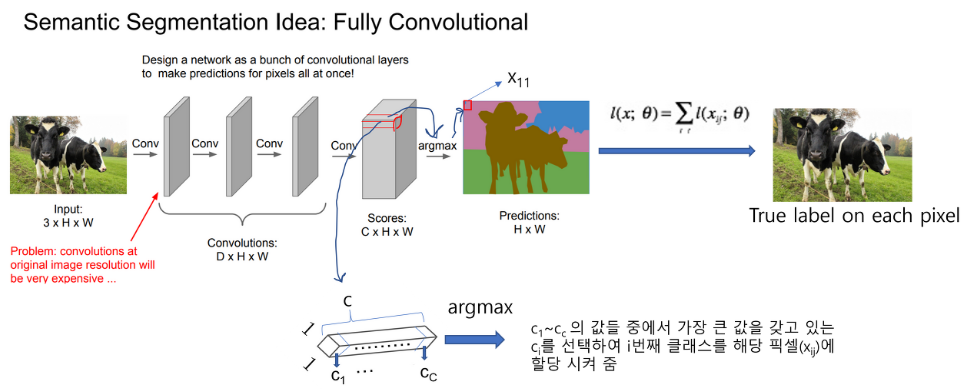
Pixelwise learning : 전체 이미지를 CNN에 넣어 Pooling 과정 없이 feature을 추출함 결과 C(class) H W 형태(classification scores map) 각 픽셀 위치에 제일 높은 class score에 맞는 색 할당 최종 결과 H W (prediction map)
-
Pixelwise learning 문제점
- layer가 깊어질수록 계산량이 상당히 증가함.
- 구조적인 hierarchical feature를 뽑지 못함.
- 이러한 문제점을 해결하기 위해 FCN을 고안함. FCN의 encoder 부분을 기존 CNN 방식처럼 수행하고, decoder 부분을 붙여 segmentation을 수행함.
3 FULLY CONVOLUTIONAL NETWORKS
FCN은 임의의 크기를 가진 입력값을 취하고, 그에 해당하는 크기의 출력값을 생성함.
다음은 classification 신경망을 corse output을 생성하는 fully convolutional 신경망으로 어떻게 전환하는지 설명함. pixelwise prediction을 위해, 이 coarse output을 pixel로 연결해야 함.
upsampling을 위한 deconvolution layer를 소개함.
3.1 Adapting clssifiers for dense prediction
LeNet, AlexNet과 같은 전형적인 recognition 신경망은 fixed-sized 입력값을 받아서 공간정보가 없는 출력값을 생성함. 이러한 신경망은 차원을 고정하고 fully connected layers는 공간 정보를 제거함. 하지만 이 fully connected layers는 또한 전체 입력 값을 다루는 kernel을 가진 convolution으로 볼 수 있음. 이것을 fully convolutional 신경망으로 전환하면, classification 신경망은 임의의 크기의 입력값을 받아서 heat map을 생성할 수 있음.
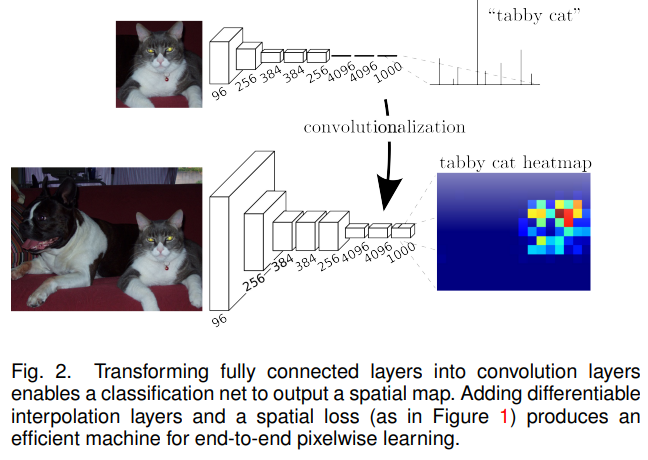
모든 출력 셀에서 이용 가능한 접지 진도를 통해 순방향 및 역방향 패스는 모두 간단하며, 둘 다 convolution 고유의 계산 효율성을 활용함.
분류망을 fully convolutional으로 재해석하면 모든 크기의 입력에 대한 출력 map이 생성되지만, 출력 치수는 일반적으로 subsampling에 의해 감소함. 분류 신경망은 filters를 작고 합리적인 계산 요건을 유지하기 위해 하위 표본으로 삼음. 이것은 fully convolutional 신경망의 출력을 조밀하게 하고, 출력 장치의 receptive fields의 pixel stride와 같은 계수만큼 입력의 크기에서 감소시킴.
3.2 Shift-and-stitch is filter dilation
입력값이 conv + pooling을 통과하면 크기가 감소함. 이를 복원하는 방법으로 shift-and-stitch 방법을 검토하는데, upsampling이 더 효과적으로 판단하여 이 방법은 사용하지 않음.
3.3 Upsampling is (fractionally strided) contolution
Couarse output을 dense pixel로 연결하는 또 다른 방법은 보간법(interpolation)임. upsampling을 위해 bilinear interpolation을 사용함.
Upsampling은 pixel 단위 손실에서 역전파에 의해 end-to-end 학습을 위해 네트워크에서 수행됨. Deconvolution networks에서의 사용에 따라, 이러한 계층은 때때로 deconvolution 계층이라고도 불림.
저자는 실험에서 network 내 upsampling이 빠르고 조밀한 예측을 학습하는 데 효과적이라는 것을 발견함.
3.4 Patchwise training is loss sampling
Patchwise training과 fully convolutional training을 비교해서 설명함. Patchwise training은 전체 이미지에서 crop된 부분을 이용하는 것임. 반면에 fully convolutional training은 전체 이미지를 입력으로 받아 학습하는 것임.
Patchwise training을 사용하면, class imbalance 문제가 발생하고, fully convolutional training이 속도와 효율성 면에서 더 좋음.
4 SEGMENTATION ARCHITECTURE
ILSVRC classification 신경망을 FCN으로 변경하고, upsampling과 pixelwise loss를 위해 구조를 수정함. 그리고 prediction을 개선하기 위해 coarse, semantic, local, appearance 정보를 결합하는 skip architecture을 제안함.
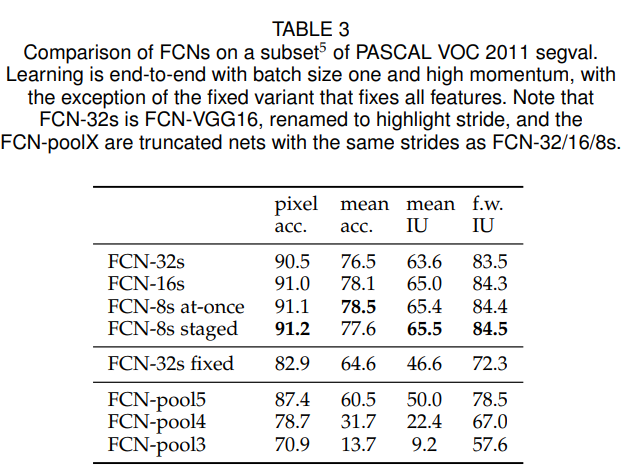
Per-pixel multinimial logistic loss로 학습하고, mean pixel intersection over union의 표준 metric으로 평가함. 학습은 ground truth에서 벗어나는 pixel을 무시함.
4.1 From classifier to dense FCN
Backbone은 VGG 16을 사용함. 그리고 마지막 classifier layer를 버리고, 이것을 fully convolution으로 변경함. 원래 이미지 크기로 맞춰주기 위해 coarse output에 upsampling을 수행하는 deconvolution layer 이후의 coarse output locater에 21차원을 가진 1 1 convolution을 추가함. 21차원은 배경을 포함한 PASCAL classes를 예측함.
저자는 실험을 통해 FCN-VGG16을 base network로 사용함.
4.2 Image-to-image learning
손실은 모든 pixel에 걸쳐 공간적으로 합산되기 때문에 저자는 적은 학습률을 사용함.
배치 크기를 위해 gradients는 20개 이상의 영상이 축적되고, 배치 사이즈 1은 온라인 학습에 사용됨. 추가적으로 0.99의 높은 momentum을 시도하여 배치 처리와 유사한 방법으로 최근 gradient에서 가중치를 증가시킴.
4.3 Combining what and where
Segmentation을 위한 새로운 fully convolutional network를 정의함. Layer를 결합하고 출력값의 공간적인 정보를 개선함.
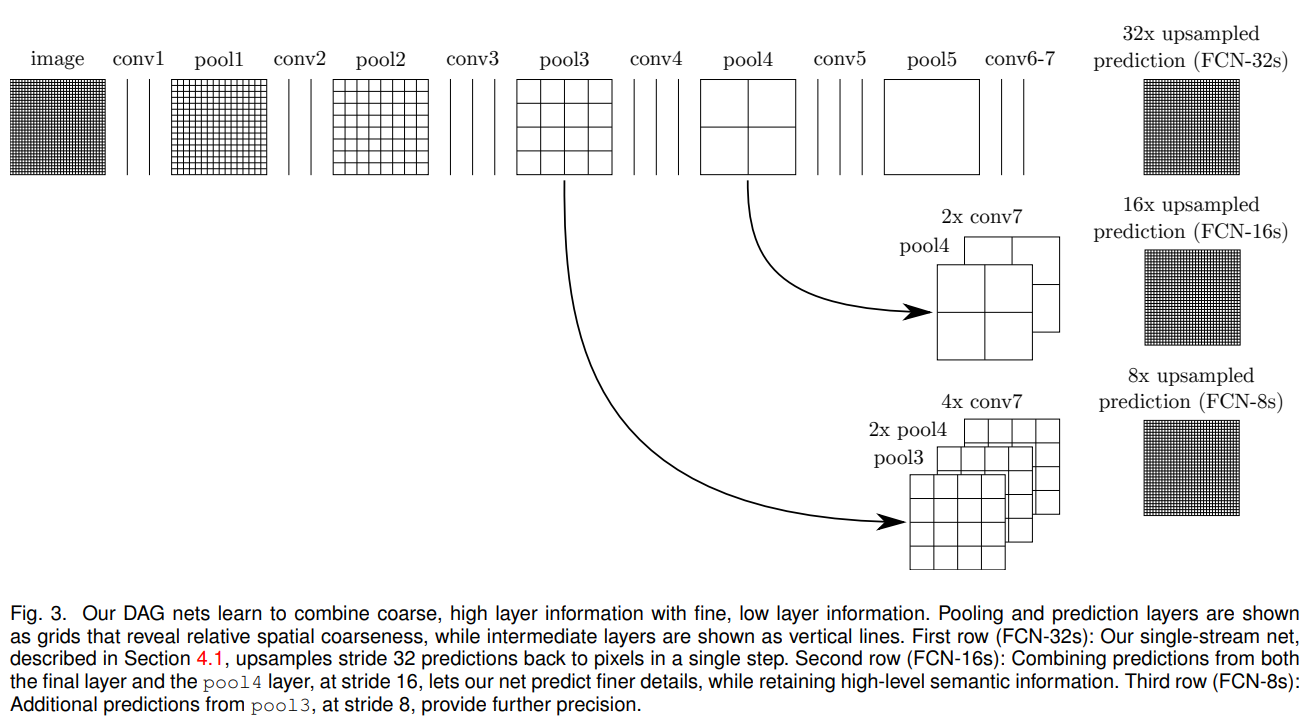
Fully convolutionalized classifiers는 segmentation을 위해 fine-tuning을 할 수 있고, 이러한 network는 더 얕고 더 local한 기능을 직접 사용하도록 개선될 수 있음. 비록 높은 standard metrics를 얻더라도, 이 출력값은 coarse를 만족하지 않음. 아래 그림에서 FCN-32s를 보면, pixel들이 뭉쳐져 있는 것을 확인할 수 있음. 마지막 prediction layer에서 32 pixel stride는 upsampled output에서의 scale을 제한함.
이를 해결하기 위해서, final prediction layer를 lower layer와 결합하는 link를 추가함. Lower layer를 higher layer와 연결함. Fine layer를 coarse layer와 연결하는 것은 model이 local predictions을 예측하게 함.
저해상도 레이어를 upsampling하여 두 layer를 scale agreement함. 잘라내기 padding으로 인해 다른 layer보다 확장된 upsampled된 layer 부분을 제거함. 그 결과 정확하게 정렬된 동일한 치수의 layer가 생성됨.
Layer를 공간적으로 정렬한 후, 다음으로 fusion 작업을 선택함. 우리는 연결로 특징을 융합하고 즉시 1 1 convolution으로 구성된 점수 layer로 분류함. 연결된 feature를 메모리에 저장하는 대신, 연결 및 후속 분류를 이동함. 따라서 skip은 먼저 1 1 convolution으로 융합될 각 layer에 점수를 매기고 필요한 보간 및 정렬을 수행한 다음 점수를 합산하여 구현됨.
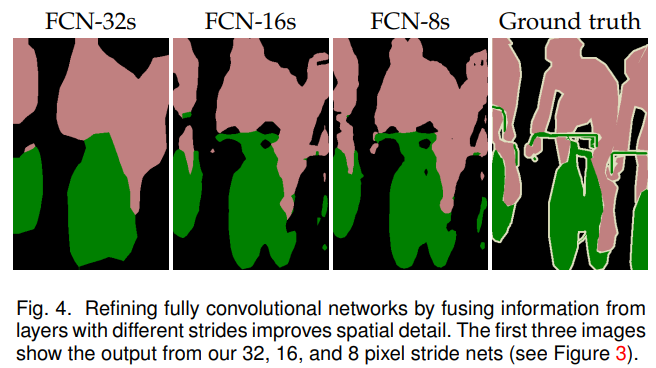
Skip Architectures for Segmentation : 16 pixel stride layer로부터 예측함으로써, output stride를 반으로 분할함. 그리고 추가적인 class prediction을 생성하기 위해 pool4의 위에 1 1 convolution layer를 추가함. 이 출력값을 stride32dls conv7에서 계산된 예측값을 2 upsampling한 뒤에 더함. 마지막으로 입력 이미지의 크기로 upsampling 함. 이것을 FCN-16s라고 함. 다시 이것을 2 upsampling한 뒤에 pool3의 출력값과 더해주면 FCN-8s가 됨.
7 CONCLUSION
Semantic segmentation을 위한 FCN은 사전 훈련된 classifier의 가중치를 전송하고, 다른 layer 표현을 융합하며, 전체 이미지에 대한 end-to-end로 학습함으로써 정확도를 크게 향상시킴. End-to-end, pixel-to-pixel 조작을 통해 학습과 추론을 심플화하는 동시에 고속화할 수 있음.
참고
https://deep-learning-study.tistory.com/562
https://velog.io/@leejaejun/Paper-Review-FCN-Fully-Convolutional-Networks-for-Semantic-Segmentation
