Abstract
Self-Attentive Sequential Recommendation(SASRec)를 통해 사용자의 마지막 행동을 통해 예측하는 Markov Chains(MCs)와 장기적인 정보를 예측하는 RNN의 균형을 이뤘음.
I. INTRODUCTION
순차적 추천 시스템은 사용자의 행동에 대한 맥락을 고려하여 새로운 제품을 추천함. 하지만 사용자의 과거 행동들은 기하급수적으로 늘어나기 때문에 맥락을 포착하는 데에는 어려움이 있음.
순차적 추천 방법에는 MC와 RNN이 있음. Markov Chains(MCs)의 경우, 사용자의 이전 행동만 가지고 다음 행동을 예측함. 강력한 단순화를 가정함으로써 높은 희소성 환경에서 잘 수행되지만 복잡하거나 고밀도 환경에서는 성능이 떨어짐. Recurrent Neural Networks(RNNs)의 경우, hidden state를 활용하여 이전의 모든 행동들을 고려해 다음 행동을 예측함. RNN은 표현적이기는 하나 고밀도의 많은 데이터가 요구됨.
새로운 순차적 모델 Transformer는 self-attention을 사용하여 의미 있는 패턴을 효율적으로 발견할 수 있음. 아래 그림은 저자가 제시한 Self Attentive Sequential 추천 시스템(SASRec)의 학습 과정임.
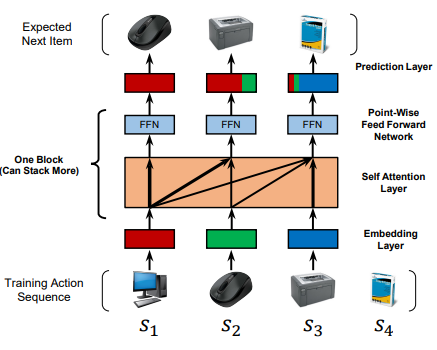
각 시점에서 모델은 attention을 사용하여 모든 이전의 아이템을 고려하고 다음에 등장할 아이템을 예측함. 순차적 추천 시스템에 self-attention 매커니즘을 적용함으로써 RNN의 특징과 MC 특징 모두를 반영할 수 있음. 고밀도, 희소한 데이터 셋에서의 실험을 통해 좋은 결과를 보였고, 병렬 처리에 적합하며, 기존의 CNN/RNN 기반의 모델보다 빠름을 보였음.
II. RELATED WORK
A. General Recommendation
추천 시스템은 과거 피트백(클릭, 구매 등)을 바탕으로 사용자와 항목 간의 호환성을 모델링하는 데 초점을 맞춤.
B. Temporal Recommendation
일시적 추천은 유저의 활동의 타임 스탬프를 명시적으로 모델링 하는 것으로써, 다양한 태스크에 강한 성과를 보임.
순차적 추천은 작업 순서만 고려하고 시간에 관계없이 순차적 패턴을 모델링하기 때문에 일시적 추천과는 약간 다름. 본질적으로, 순차적 모델은 시간적 패턴 그 자체를 고려하는 것이 아니라 사용자의 최근 활동을 기반으로 사용자 행동의 context를 모델링하려고 함.
C. Sequential Recommendation
많은 순차적 추천 시스템은 연속적인 항목 간의 순차적 패턴을 포착하는 수단으로서 항목-항목 전이 행렬의 모델화를 추구함.
D. Attention Mechanisms
순차적 추천 시스템은 시간적 패턴을 고려하기보다는 최근 활동을 기반으로 사용자 행동의 순차성을 고려함. 이러한 순차성을 고려하기 위해 Attentions 메커니즘은 전체 또는 특정 영역의 입력값을 반영해 attention weight를 통해 그 중 어떤 부분에 집중해야 하는지를 나타냄. 인코더-디코더의 구조에서 디코더는 출력 단어를 예측하는 시점마다, 인코더에서의 전체 입력을 다시 한 번 참고하게 됨. Transformer는 self-attention 방법을 사용하여 입력 토큰 간의 유사도를 계산하고, 디코더의 예측을 결정하게 됨.
III. METHODOLOGY
순차적 추천 환경에서는 사용자의 행동 시퀀스 정보를 받고 다음 항목을 예측함. SASRec 추천 모델은 embedding layer와 여러 개의 self-attention blocks 그리고 prediction layer로 구성되어 있음.
A. Embedding Layer
학습 순서 ()를 고정 길이 시퀀스 으로 변환함. (는 사용자 한 명에 대한 구매 이력 기록) 은 모델이 처리할 수 있는 최대 길이로, 시퀀스 길이가 보다 크면 잘라내어 최근 개의 만큼만 모델이 고려할 수 있도록 함. 반대로 사용자에 대한 시퀀스의 길이가 보다 작으면 길이가 이 될때까지 왼쪽으로 패딩을 적용함. 아이템 임베딩 매트릭스 를 모델에 입력 가능하도록 로 변경하여 의미를 가지도록 함.(는 latent 벡터의 차원임)
Positional Embedding : self-attention 모델은 recurrent나 convolutional 같은 모듈을 포함하고 있지 않기에 이전 아이템에 대한 위치 정보를 알 수 없음. 이에 따라 위치 정보를 기억하는 position embedding 을 모델 학습에 넣었으며, 최종 input embedding은 아래와 같음.
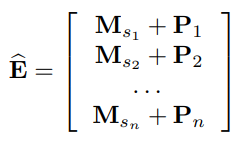
B. Self-Attention Block
다음으로 Self-Attention Block을 거치게 되는데 이는 Attention Is All You Need에서 등장한 Trasformer의 구조와 거의 유사함.
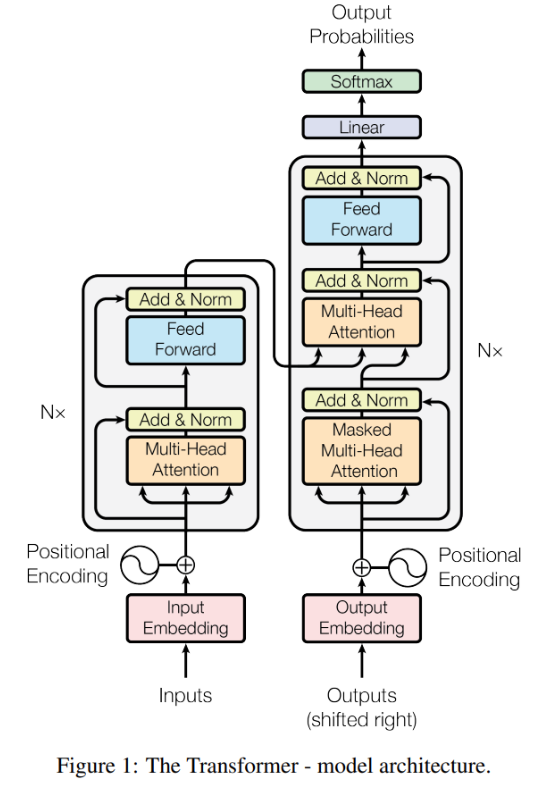
Transformer 구조는 인코더-디코더 구조로 나누어져 있으며, (Query, Key, Value)를 입력받아 Scaled dot-product와 Multi-head attention을 통해 입력들 간의 유사도를 계산하게 됨. 이때 Positional Encoding을 통해 입력의 순서를 기억할 수 있도록 하며, Residual connect를 통해 기존에 들어오는 입력의 정보는 유지하고 Layer normalization을 통해 계산된 입력값들에 대한 정규화를 진행함. 이후 Fully connected feed-forward network를 통과하고 softmax를 거쳐 가장 관련이 깊어 보이는 output 결괏값을 출력하게 됨.
입력의 유사도를 계산하는 방법으로 Scaled dot-product를 사용하게 되는데 이때 모든 입력을 Query, Key, Value로 생성하여 계산에 사용함. Query와 Key의 내적을 통해 유사도를 구한 후 ( = 차원의 크기)만큼 나누어 softmax 결과가 한쪽으로 치우지지 않도록 함. Query와 Key간의 유사도가 구해지면 Value의 값을 통해 최종적인 행렬 곱을 수행하게 됨. Scaled dot-product 그림에서 보이는 Mask의 경우 디코더 부분에서 활용되며 미래의 정보를 알 수 없기에 사용하게 됨. 이후 Multi-Head Attention을 통해 차원을 줄인 scaled dot-product를 여러 개로 나누어 각각의 시선에서 입력을 볼 수 있도록 병렬처리를 함. 이후 새로운 learnable parameter인 를 통해서 Query, Key, Value 각각을 Projection 시키고 concat하여 선형 변환하도록 함.
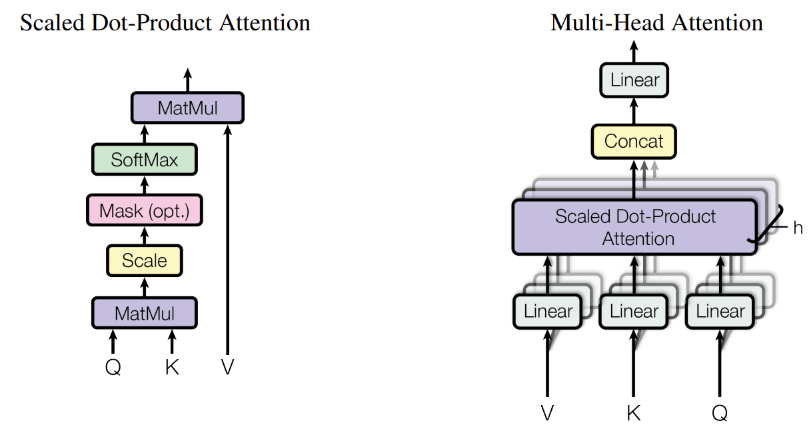

임베딩 레이어에서 생성한 를 입력 받아 (Query, Key, Value)를 linear projection을 통해 3개의 행렬로 변환하고 attention layer에 공급함.
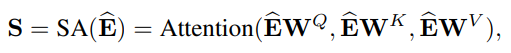
Causality : sequence의 특성으로 번째 항목을 예측할 때, 이전의 항목만 고려해야 함. 만약 이후의 항목들이 포함되어 있다면, 해당 데이터들의 연결을 마스킹 처리하여 이전의 항목들만 볼 수 있도록 함.
Point-Wise Feed-Forward Network : 모델에 비선형성을 부여하고 서로 다른 잠재 차원 간의 상호작용을 고려하기 위해, point-wise-two-layer feed-forward network를 사용함. 이때, 와 는 서로 상호작용이 없으며 (), 이는 사용자들의 행동이 서로 영향을 주지 않음을 의미함.
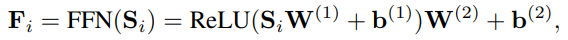
C. Stacking Self-Attention Blocks
이후 self-attention blocks를 여러 개 쌓아 복잡한 item transitions를 학습하도록 함. 아래의 식에서 는 self-attention blocks의 수를 나타냄.
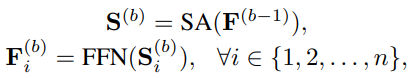
network가 깊어질수록
1. 모델의 capacity가 증가하여 overfitting이 발생
2. vanishing gradients로 인해 학습 과정이 불안정
3. 많은 파라미터로 인해 학습 시간이 많이 요구됨
이에 따라 입력에 대해 Layer Normalization을 적용하고, Dropout과 Residual Connections를 사용함.
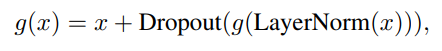
Residual Connections : Residual 네트워크 배후에 있는 핵심 개념은 잔류 연결을 통해 저층 기능을 상위 계층으로 전파하는 것임. 따라서, 저층 특성이 유용한 경우, 모델은 그것들을 최종 계층에 쉽게 전파할 수 있음.
Layer Normalization : Layer 정규화는 여러 피쳐에 걸쳐 입력을 정규화하기 위해 사용되며, 이는 뉴럴 네트워크 훈련의 안정화와 고속화에 도움이 됨. 배치 정규화와는 달리 Layer 정규화에 사용되는 통계량은 동일한 배치의 다른 표본과 독립적임.
Dropout : 심층 신경망의 과적합 문제를 완화하기 위해, Dropout 정규화 기법은 다양한 신경 네트워크 아키텍처에서 효과적인 것으로 나타남. 훈련 중에 확률 의 뉴런을 무작위로 끄기하고, 모든 뉴런을 시험할 때 사용함.
D. Prediction Layer
위의 번만큼의 self-attention blocks를 통과한 후 다음에 오는 아이템을 예측하는데, Matrix Factorization 방법을 사용하여 아이템의 관련 점수()을 계산함. 이때 아이템 임베딩 매트릭스 을 사용함.

Shared Item Embedding : 모델의 사이즈와 오버피팅을 예방하고자 Shared Item Embedding 매트릭스 을 사용함.
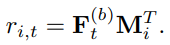
Shared Item Embedding을 사용할 경우 sequential을 반영할 때 비대칭적인 item transitions를 반영할 수 없기에 서로 다른 아이템 임베딩을 사용해야 한다고 생각할 수 있음. (예를 들어, 라는 아이템은 주로 번째 아이템 이후에 구매되었지만, 역은 성립하지 않음) 그러나 저자가 제안한 모델은 FFN을 통해 비선형 변환을 학습하여 문제가 되지 않으며, 실제로 Shared Item Embedding을 사용했을 때 모델의 성능이 향상함.
Explicit User Modeling : 개인화된 추천시스템을 구성하기 위해 사용자의 이전 행동들을 임베딩값으로 만들어 로 나타낼 수 있지만, 성능의 개선은 없었다고 함.
E. Network Training
모델의 loss의 경우 사용자가 관심 있는 항목(positive sampling)과 관심 없는 항목(negative sampling)을 통해 binary cross entropy를 계산하고, Adam 옵티마이저를 사용하여 모델을 최적화함. 아래 loss의 식에서 좌측의 항은 positive samples과 우측 항은 negative samples를 의미함.
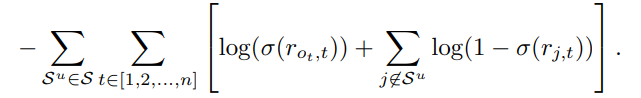
IV. EXPERIMENTS
A. Datasets
저자는 총 4개의 데이터셋(Amazon Beauty, Amazon Games, Steam, MoieLens)에서 실험을 진행함. 사용자가 가장 최근에 구매한 아이템 은 test 데이터로 생성하고, 그 이전에 구매한 아이템 은 validation 데이터로 생성하였으며, 나머지 모든 데이터는 학습에 사용함.
E. Recommendation Performance
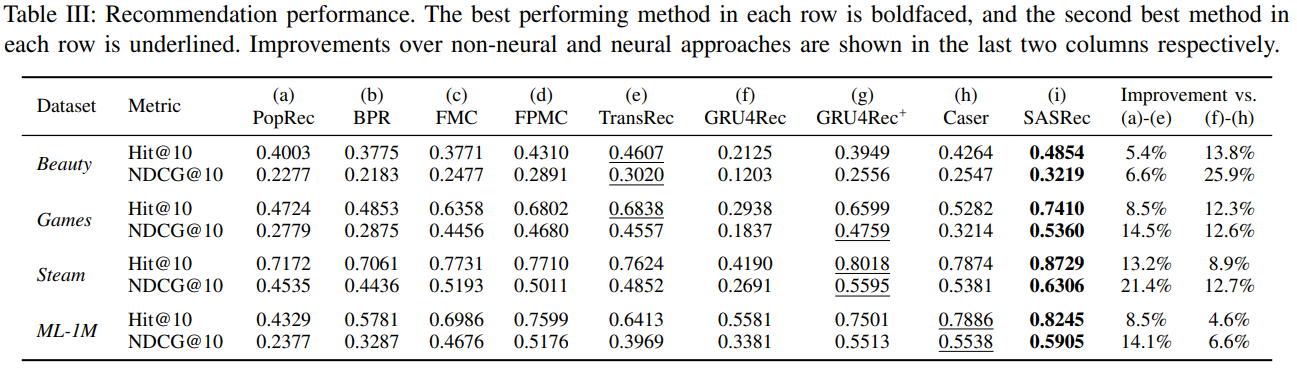
모델 성능 비교 결과 저자가 제안한 SASRec 모델이 모든 데이터셋에서 가장 우수한 성능을 보였으며, 특히 기존의 신경망 기반의 추천시스템(f-h)에서 좋은 성능 개선을 이뤘음. 모델이 다양한 데이터셋의 다양한 범위 내의 항목에 적응적으로 참여하기에 희소한 데이터셋과 고밀도 데이터셋 모두에서 모든 기준선을 능가함.
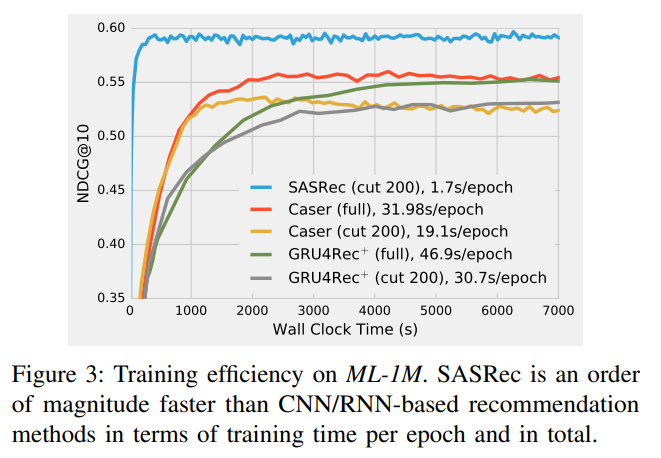
G. Training Efficiency & Scalability
모델의 훈련 효율성의 두 가지 측면의 평가함 : 훈련 속도(훈련 1 epoch에 걸리는 시간) & convergence 시간(만족스러운 퍼포먼스를 달성하는 데 걸리는 시간) 또한, 최대 길이 의 관점에서 모델의 확장성을 조사함.
Training Efficiency : SASRec는 1 Epoch 모델 업데이트에 1.7초밖에 걸리지 않음. 이는 Caser(19.1s/epoch)보다 11배, GRU4Rec+(30.7s/epoch)보다 18배 빠른 속도임. 또한 SASRec은 ML-1M에서 약 350초 이내에 최적의 퍼포먼스로 수렴되지만 다른 모델에서는 훨씬 더 오랜 시간이 소요됨.
Scalability : 표준 MF 방식과 마찬가지로 SASRec은 총 사용자 수, 항목 및 작업에 따라 선형적으로 확장됨. 이 클수록 성능이 향상됨.(최대 까지) 이때 성능이 포화됨.(행동의 99.8%가 적용되었기 때문에 더욱 향상됨) 그러나 인 경우에도 Caser 및 GRU4Rec+보다 빠른 2,000초 만에 모델을 훈련시킬 수 있음. 따라서 저자의 모델은 사용자 sequence로 쉽게 확장할 수 있으며, 이는 일반적인 리뷰 및 구매 데이터셋에 적합함.
H. Visualizing Attention Weights
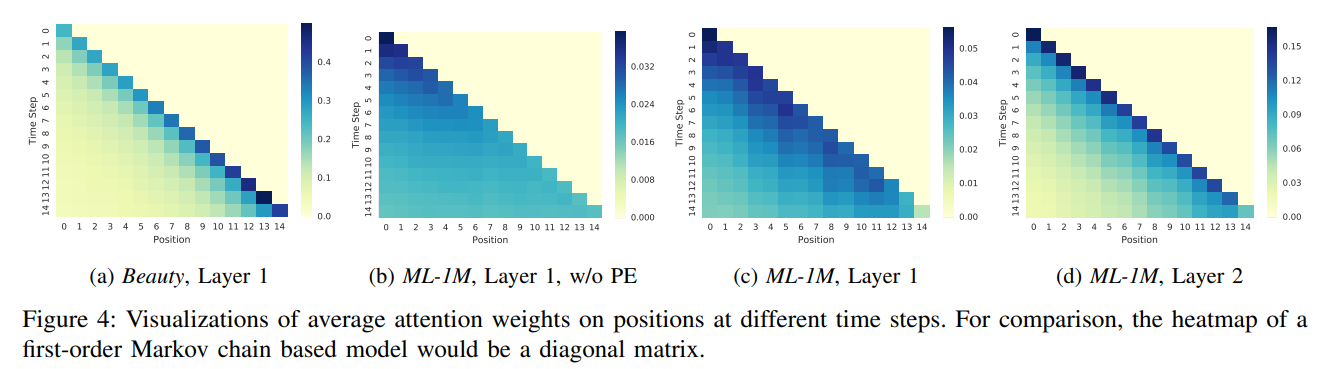
아래의 그림은 Attention weights를 히트맵으로 시각화하여 데이터셋, Positional Embedding, Layer에 따라 Adaptive하게 달라지는 Attention map을 나타냄.
Attention on Positions :
* (a) vs. (c) : sparse했던 Beauty 데이터셋에서는 최근 2~3개 아이템 정보를 기반으로 예측하는 것을 알 수 있고, 비교적 dense했던 MovieLens 데이터셋에서는 최근 정보를 더 많이 관측했음을 알 수 있음. 기존 방법은 스펙트럼의 한쪽 끝에 초점을 맞추는 경향이 있는 반면, 저자의 모델이 희박한 데이터셋과 고밀도 데이터셋을 적응적으로 처리할 수 있게 해주는 핵심 요인임.
* (b) vs. (c) : positional embeddings의 효과를 알아보기 위함임. positional embedding이 없는 (b)의 경우 attention map이 uniform하게 나타나 있는 것을 알 수 있음. 이는 순서에 대한 가중치가 없으면 학습이 안 됨을 의미함.
* (c) vs. (d) : Layer 수에 따라 학습의 정도가 다른 것을 알 수 있음. (c)의 경우, input sequence에 대해 전체 아이템들의 관계를 학습하기 때문에 넓은 attention 분포를 확인할 수 있음. 반면, (d)의 경우 Layer1에서 이미 전체 정보를 받아왔기 때문에 Layer2에서는 최근 정보만을 주목하는 것을 알 수 있음. 이는 예측에 영향을 미치는 중요(세부) 정보는 최근 아이템임을 의미함.