주재걸 교수님 강의에서 길게 풀어썻던 내용들이다. 스마게 김성현 강사님의 수업과 함께 BERT 모델을 다시 요약해보자.
Introduction
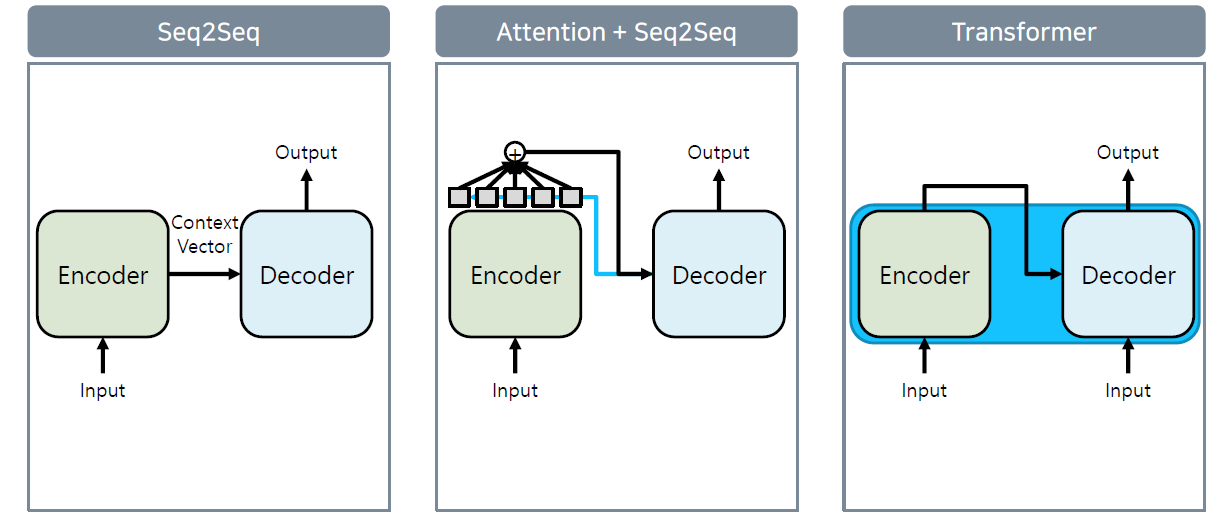
Language model은 위와 같은 순서로 발전했다. 초기에는 Encoder와 Decoder를 분리해 각각 RNN으로 개발했다. Seq2Seq에 Attention을 도입해서 Decoder 시의 성능을 높이고, transformer에서는 이를 하나로 결합했다.
Image AutoEncoder
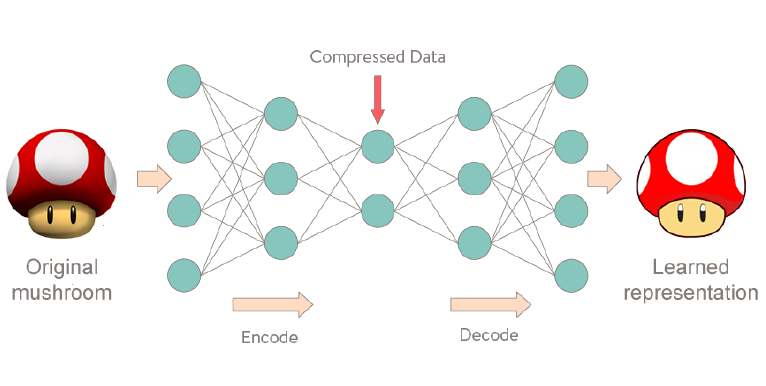
AutoEncoder는 원본 이미지 재현, 복원하는 것이 목적이다. 즉, 네트워크는 원본 이미지를 재현하기 위한 정보를 압축해서 저장할 것이다.
BERT
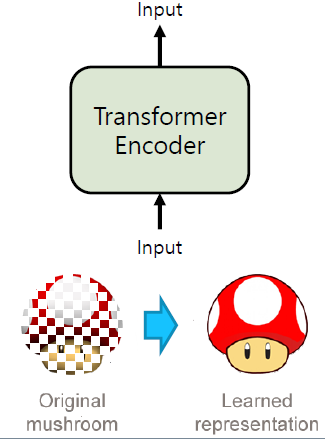
BERT 또한 AutoEncoder와 같이 원본을 재현, 복원하는 것이 목적이다. 다만 문제의 난이도를 위해 원본에 Masking을 해서 재현, 복원하고자 한다. 원본은 자연어 자체를 의미하기 때문에 네트워크는 자연어에 대해서 학습하도록 노력하 것이다.
BERT , GTP
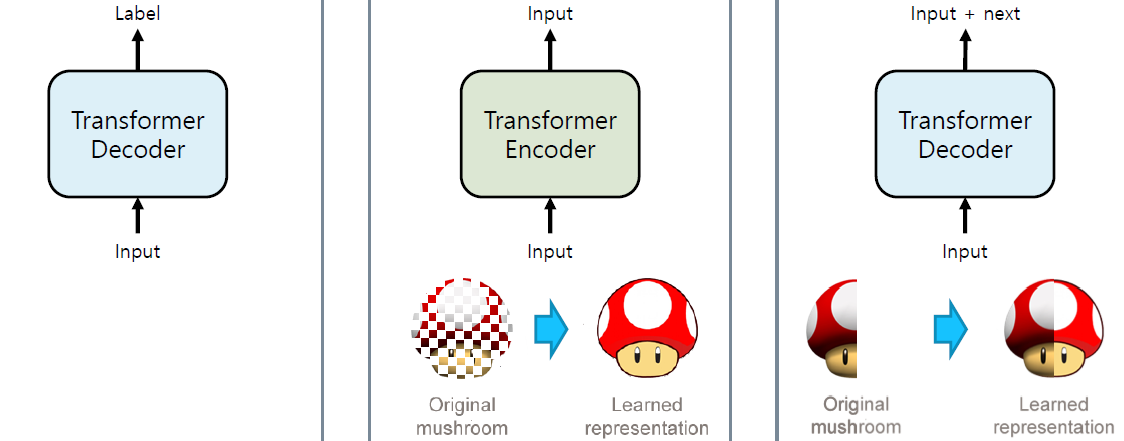
GPT-1이 BERT보다 먼저 나왔다고 한다.
- GPT-1: Transformer decoder만을 활용해 자연어 학습
- BERT: Trasformer encoder만을 활용해 Masking된 자연어 학습
- GPT-2: Transformer decoder만을 활용.
- sequence의 특정 지점 이후를 제거하고, 이후의 내용을 추론하도록 학습
BERT
BERT를 학습하는 과정은 아래와 같다. 이를 통해 Pre-trained BERT를 얻는다.
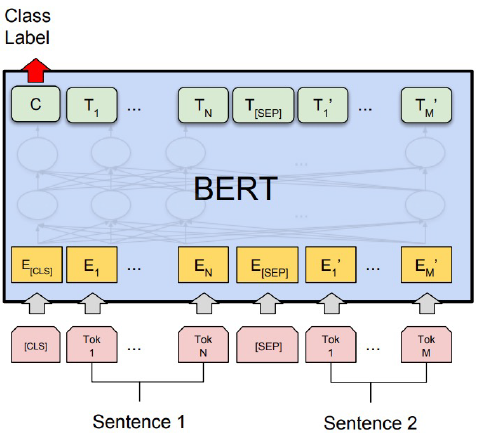
- Sentence 1, 2가 [SEP] token으로 묶여서 들어간다.
- [CLS] token에는 sentence 1, 2가 next 관계인지에 대한 정보가 담겨있다.
- [CLS] token vector에는 입력된 sentence의 정보가 모두 녹아서 embedding 된다!
- [CLS] token에 classifier를 붙여서 next 관계를 파악하는 classification 학습을 한다.
Data 처리
- Word Tokenizing
- BERT는 WordPiece tokeninzing을 사용한다.
- 즉, 빈도 수를 기반으로 tokenizing을 한다.
- Sentence
- 첫번째 문장의 다음 문장은 next sentence거나 random chosen sentence를 사용한다.
- Masking
- token들은 15%의 확률로 Masking 대상이 된다.
- Masking 대상 중 8:1:1의 비율로 Masking, Randomly replacing, Unchanging을 선택한다.
BERT 응용
GLUE, KLUE 등은 통해 Benchmark를 해보자.
대표적인 Benchmark는 아래와 같다.
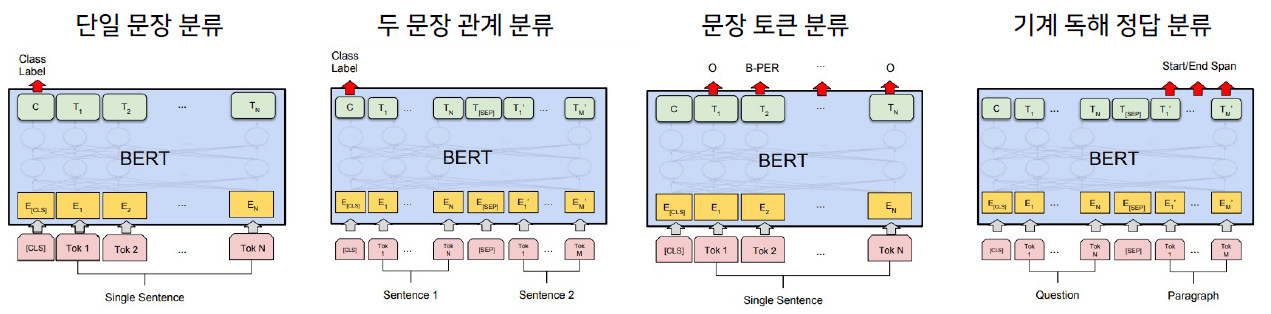
- 단일 문장 분류
- 1개의 문장 입력에 대한 분류
- 두 문장 관계 분류
- 두 문장의 유사도, 관계, next 관계 등을 분류
- 문장 토큰 분류
- 각 token마다 classifier를 부착해서 token을 분류한다.
- NER(Named entity recognition)
- 기계 독해 정답 분류
- 질문과 질문의 정답이 포함된 문서가 주어진다.
- 문서에서 정답의 위치를 파악
각 Benchmark들의 예시들은 다음과 같다.
감성 분석
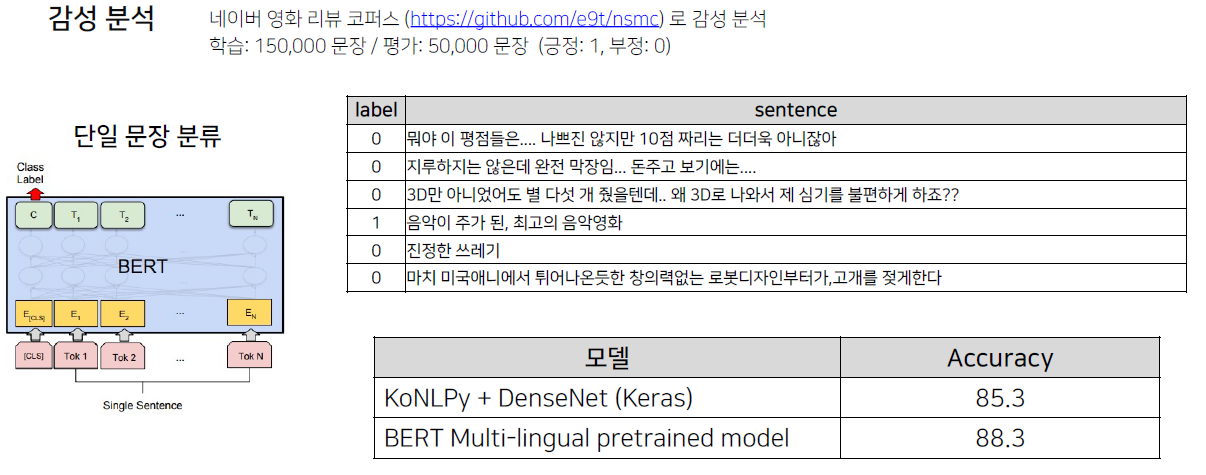
입력된 문장에 대한 긍정, 부정을 판단하는 task. 2018년에 등장한 BERT 이전에도 이러한 task를 수행해야했고 보통 85%의 acc를 보여줬다. BERT 이후로는 91% acc는 나와야 잘 나왔다고 한다.
관계 추출
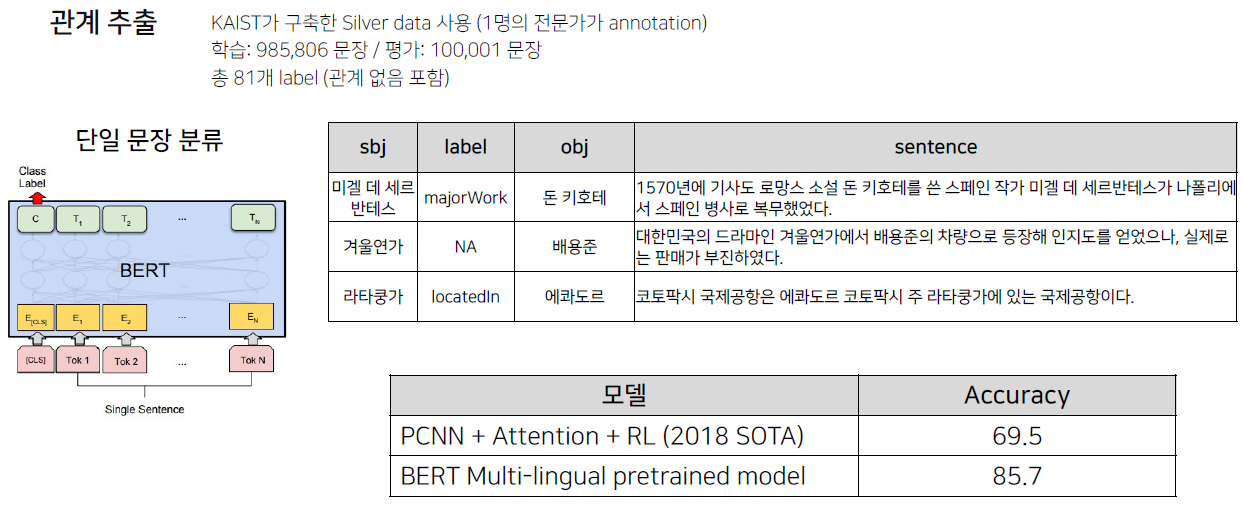
Entity라는 관계 추출의 대상을 정하고 Entity들 간의 관계를 추출하는 task다. 가령, subject인 '이순신'과 object인 '무신'이라면 이에 대한 관계는 '직업'일 것이다.
한국어 데이터 기준으로 성능이 좋지 않았던 task도 BERT가 훌륭하게 수행했다.
의미 비교
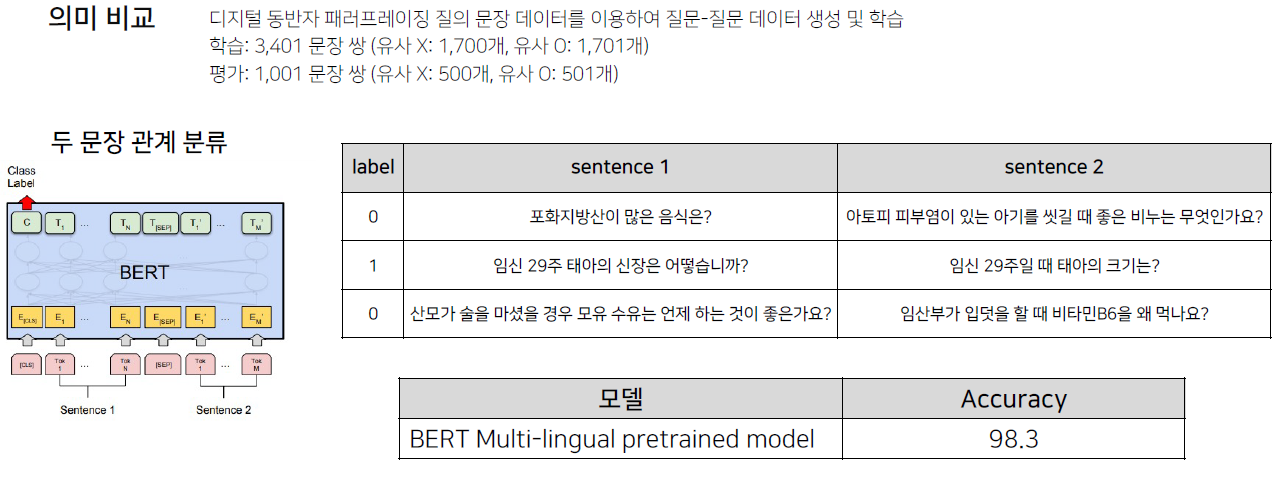
두 문장 사이의 의미적인 유사도를 판단하는 것이다. 즉, 의미가 비슷한 문장을 뽑아주는 task다.
이 때, 유사도가 높은 문장들을 통해 학습 데이터를 구성해야 한다. 왜냐하면 유사도가 너무 다른 학습 데이터들만 있다면 모델이 학습할만한 요소는 '사용되는 단어의 차이'일 뿐이다. 하지만 사용되는 단어가 비슷할지라도 분명 의미가 다른 문장들이 있다.
따라서 유사도가 높은 문장들로 학습 데이터를 구성하도록 한다.
이러한 유사도가 높은 학습 데이터만을 사용하는 것은 전처리, 데이터 설계의 문제다.
개체명 분석
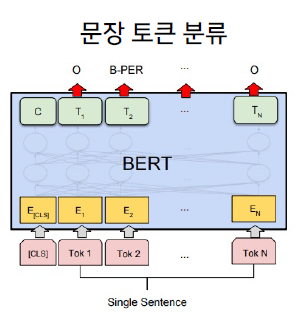
기존에는 SVM과 같은 전통적인 ML을 통해 NER을 수행했는데, BERT를 사용하면 SVM보다 월등하게 성능이 좋다.
기계 독해

기존에는 거의 유일하게 리더보드를 가지고 있는 KorQuAD라는 Benchmark를 통해서 MRC task를 평가했다. 2021년 현재는 KLUE가 발표되면서 KLUE를 쓰면된다!
Tokenizing에서 어절 단위는 음절 단위보다 성능이 월등히 나빴다. 왜냐하면 의미론적으로 같은 단어라도 어절 단위 tokenizing에서는 다른 token으로 분류되기 때문이다.
e.g., '이순신'과 '이순신은'
한국어 BERT
ETRI KoBERT
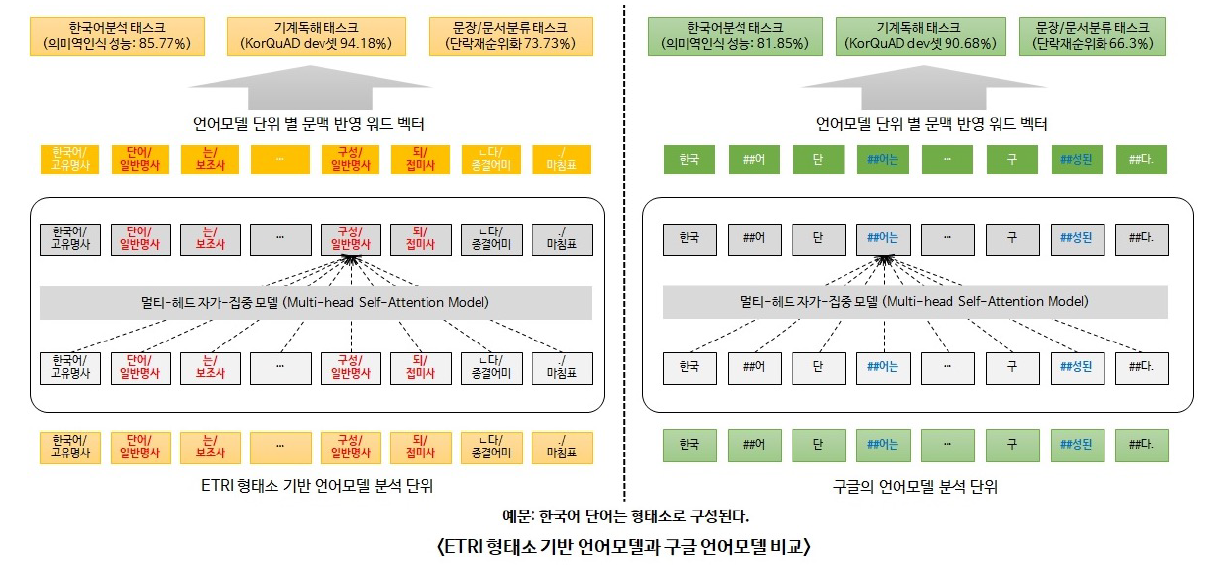
KoBERT는 바로 WordPiece를 수행하지 않고, 형태소 분리를 한 후 WordPiece를 수행한다. 이는 의미를 가진 최소 단위로 Tokenizing을 하겠다는 의도였다. 실제로도 성능이 매우 좋아 출시되자마자 바로 KorQuAD 1등을 한달 이상 찍었다. 구글 모델보다 10점 이상 좋은 점수였다고 힌다.
SKT KoBERT
https://github.com/SKTBrain/KoBERT
SKT에서도 한국어 BERT인 KoBERT를 출시했다. 이것은 형태소 단위로 분리하지 않고 바로 WordPiece를 수행했다.
차이점
KorQuAD에서 ETRI KoBERT는 SKT KoBERT보다 성능이 더 좋다. 따라서 performance적인 측면에서는 ETRI 모델이 더 좋다. 하지만 이를 사용하기 위해서는 ETRI 모델에 적합한 형태로 데이터를 전처리해야하는 수고로움이 존재한다.
바로 사용하기에는 SKT 모델이 편할 것이다.
Tokenizing에 따른 성능 차이
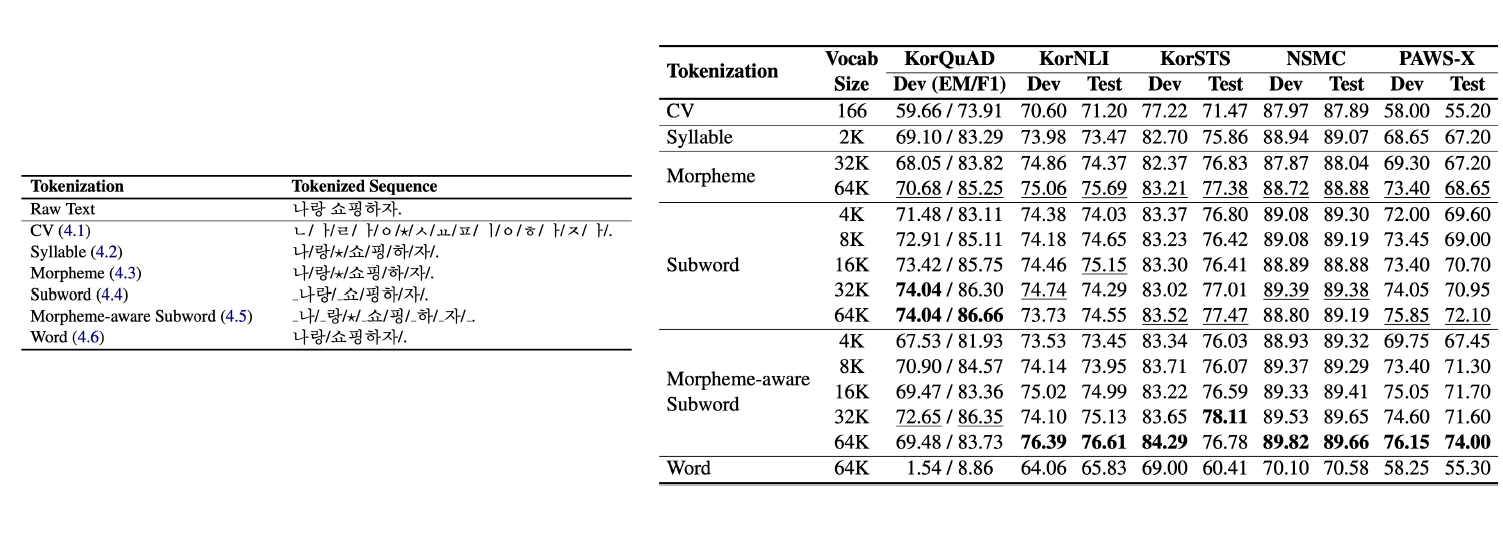
ref: https://arxiv.org/abs/2010.02534
카카오와 스캐터랩(이루다를 만든 그 회사다)이 합작해서 만든 논문이다. 논문은 한국어 Tokenizing에 따른 성능을 비교했다.
논문은 가장 성능이 좋았던 방법론은 형태소 분리를 하고 WordPiece를 수행한 Morpheme-aware Subowrd라고 했다.
Advanced BERT
김성현 강사님의 경험담이라고 하셨다.
KorQuAD에서 BERT가 정답을 만드는 feature는 Entity일 것이다. 하지만 BERT 내에는 근본적으로 Entity를 명시할 수 있는 구조가 없다.
따라서
1. Entity linking을 통해 주요 entity를 먼저 추출한다.
2. 1번에 대해 Entity tag 부착
3. Entity embedding layer 추가
4. 형태소 분석을 통해 NNP와 entity를 우선으로 하여 chunking masking을 한다.
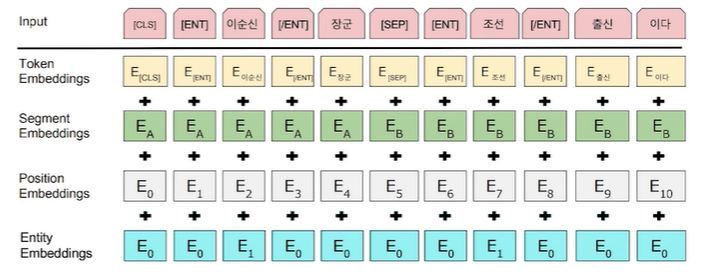
즉, 기존의 Token Embedding, Segment Embedding, Position Embedding 외에 Entity Embedding이라는 개념을 Embedding layer 단에 추가하신거라고 하셨다.
이렇게 하니 KorQuAD에서 더 좋은 점수를 얻었다고 하신다.
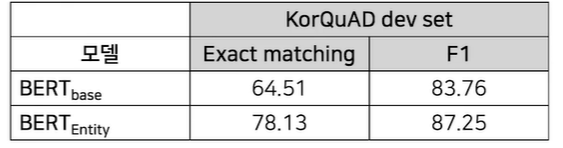
이러한 방법론이 영미권에서는 ERNIE라는 모델로 제시됐다고 하고 현재 SOTA model이라고 한다.
Blog
