Language modeling
Seq2Seq task다. 주어진 문맥을 활용해 다음 단어를 예측하는 task.
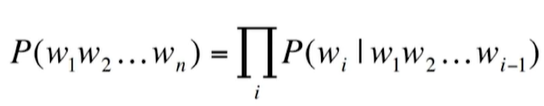
특정 시점의 문장에 대한 다음 단어가 나타날 확률을 예측하는 task로도 생각할 수 있다.
RNNs
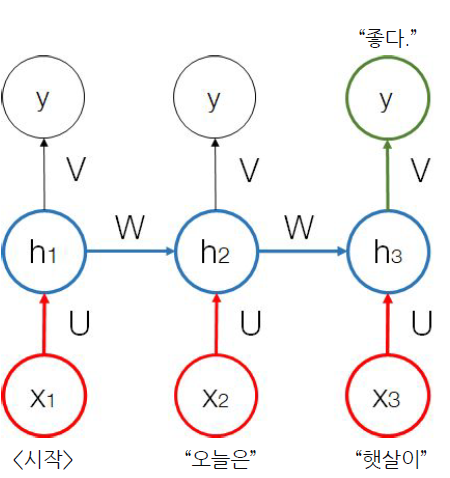
Sequence의 순서대로 model에 sequence를 입력한다. 이전 hidden state를 활용해 다음 step의 input으로 활용한다.
RNN은 task를 위해서 설계된 모델이기 때문에, 특정 task에서만 잘 작동한다. e.g., Seq2Seq model은 Seq2Seq만 처리.
Bidirectional Language Modeling
ELMo
양방향 언어 모델링. 이러한 개념을 처음 제시한 것은 ELMo(Embeddings from Language Models)다.
자연어를 Embedding 후 언어 모델링 task를 수행하는 것 자체가 다른 NLP task를 처리할 수 있다는 가능성을 보여줬다.
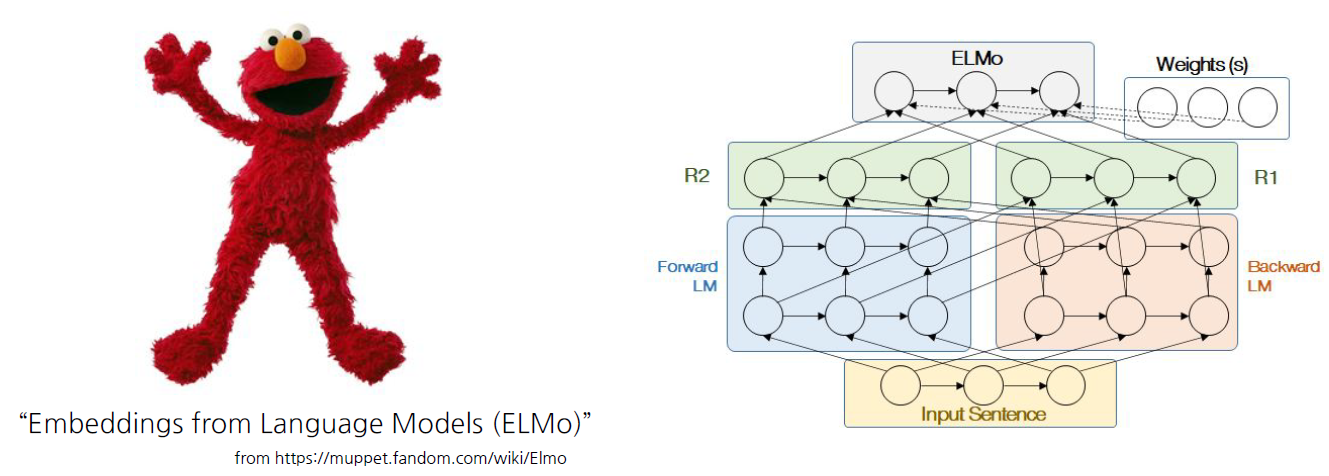
위 도식의 오른쪽 그림과 같이 ELMo는 Forward, Backward 두 방향으로 Language model을 수행한다.
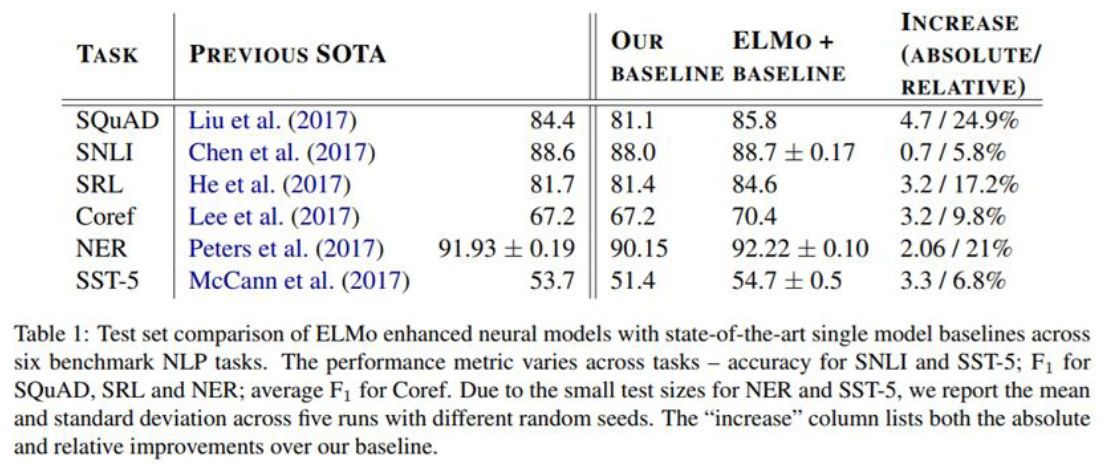
기존에는 SQuAD(질의응답), SNLI(문장 사이의 모순 파악), SRL(의미역 결정), Coref(Entity 찾기, Blog), NER(Entity 인식), SST-5(문장 분류)에 특화된 모델이 별도로 존재했다.
ELMo는 하나의 Language Model을 통해서 6개의 task를 모두 수행했고 정확도 또한 유의미함을 보여줬다.
BERT
Bidirectional Encoder Representations from transformers. Transformer를 사용해 양방향 언어 모델링을 수행한 논문이다.
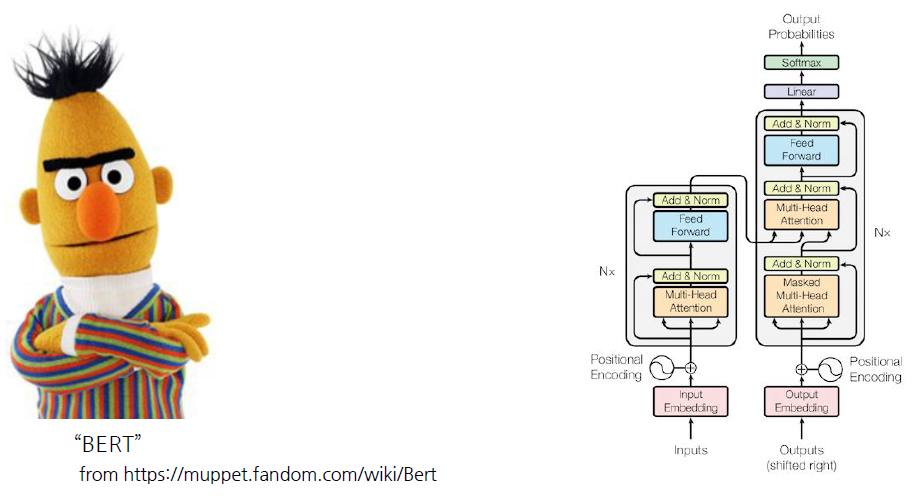
대량의 corpus에서 encoding, decoding transformer를 사전 학습하고 이를 통해 Embedding을 추출한다. ELMo에서는 두 개의 RNN을 통해 Bidirectional Encoder르 구현했다면 BERT는 transformer를 통해 양방향 학습을 동시에 진행한다.
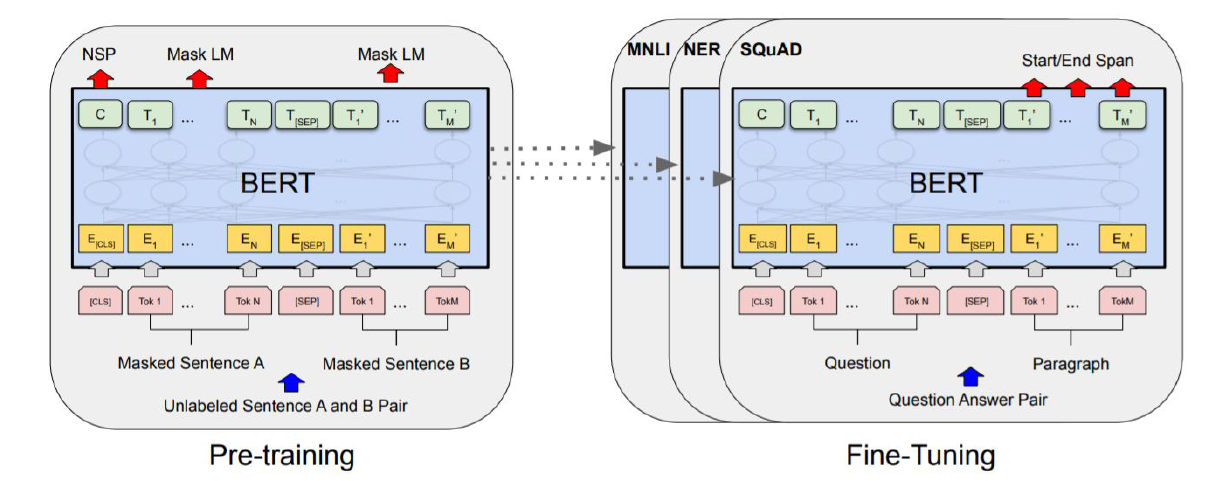
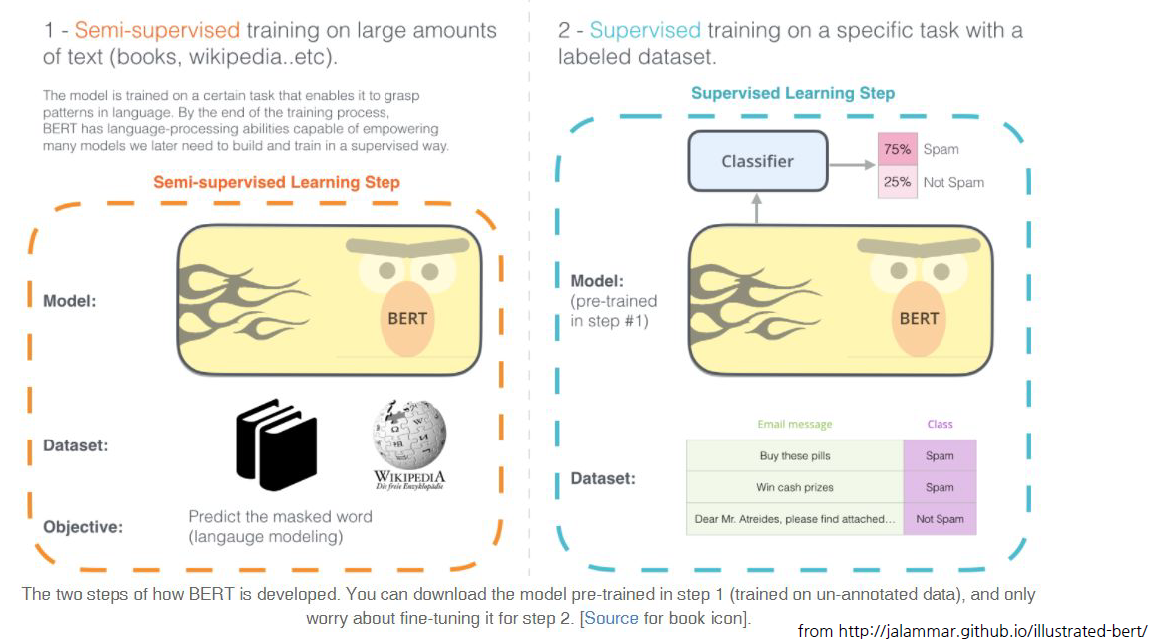
ELMo와 동일하게 Language modeling을 통해서 여러 nlp task를 수행할 수 있다는 것을 보여줬다.
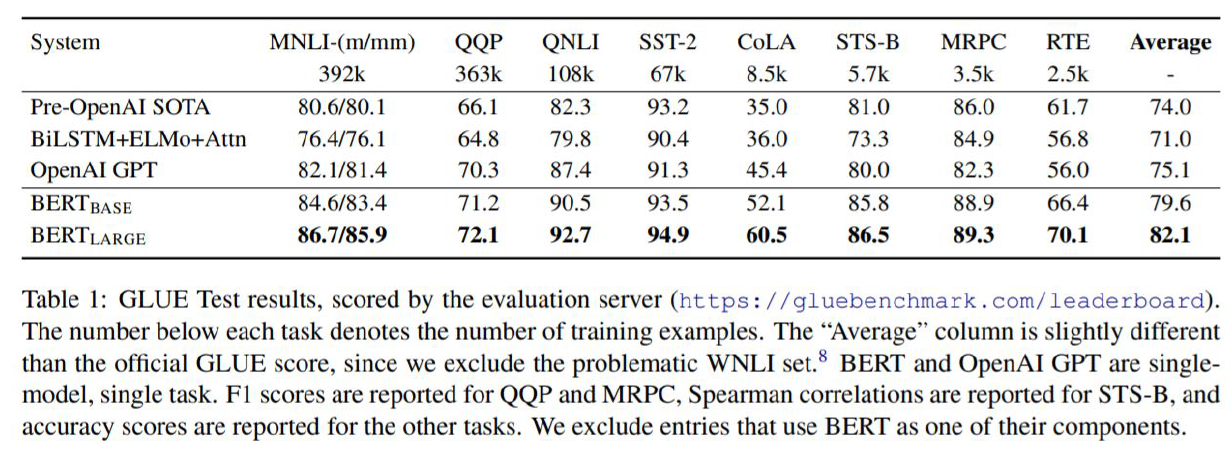
기존에도 single langauge model만으로 여러 nlp task를 처리하고자 했지만 BERT의 성능이 제일 좋았고 사용법도 보다 쉬워졌다.
GLUE와 SQuAD 1.1, 2.0에서 효과적으로 동작함을 보여줬다.
GLUE
General Language Understading Evaluation.
Language model이 자연어를 얼만큼 이해하는지 평가하는 데이터셋과 task 정의.
표준화된 데이터셋과 이에 대한 nlp task는 정의 덕분에 BERT와 이후의 모델 평가가 매우 용이해졌다. Facebook의 RoBERTa, Stanford의 ELECTRA, Google의 ALBERT 등 모두 이러한 체계 아래서 공정하게 평가가 이뤄졌다.
GLUE Benchmark는 아래와 같다. ref:https://vanche.github.io/NLP_Pretrained_Model_BERT(2)
- MNLI(Multi-Genre Natural Language Inference): entailment classification task
- QQP(Quora Question Pairs): Quora에 올라온 질문 페어가 의미적으로 동일한지 확인하는 테스크
- QNLI(Question Natural Language Inference): SQuAD의 이진분류 버전. paragraph가 answer를 포함하는지 안하는지 확인하는 문제.
- SST-2(Stanford Sentiment Treebank): 단문장 이진분류문제. 영화리뷰에서 추출된 문장에 감정이 표기되어있음.
- CoLA(Corpus of Linguistic Acceptability): 영어문장이 언어학적으로 acceptable한지 확인하는 이진분류문제
- STS-B(Seemantic Textual Similarity Benchmark): 문장쌍이 얼마나 유사한지 확인하는 문제.
- MRPC(Microsoft Research Paraphrate Corpus): 문장쌍의 유사성 확인하는 문제.
- RTE(Recognizing Textual Entailment): MNLI와 유사하나 데이터가 적음.
- WNLI(Winograd NLI): 자연어 추론 데이터셋이나 현재 채점에 이슈가 있어서 BERT 실험에서는 제외됨.
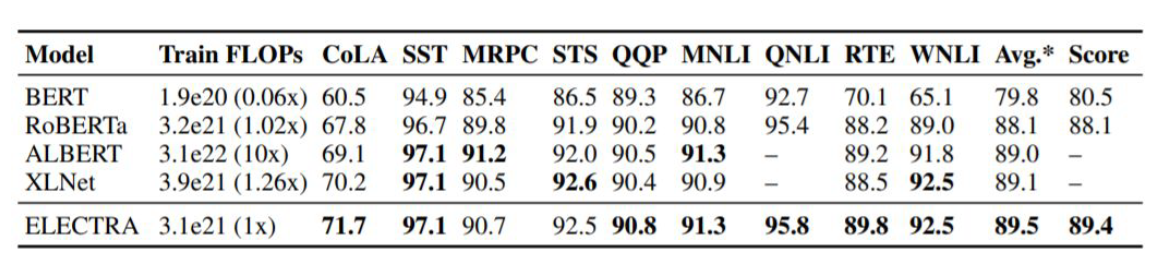
GLUE는 Benchmark를 통해 지속적으로 모델을 발전시킬 수 있는 계기가 됐다.
자연어 생성 Benchmark
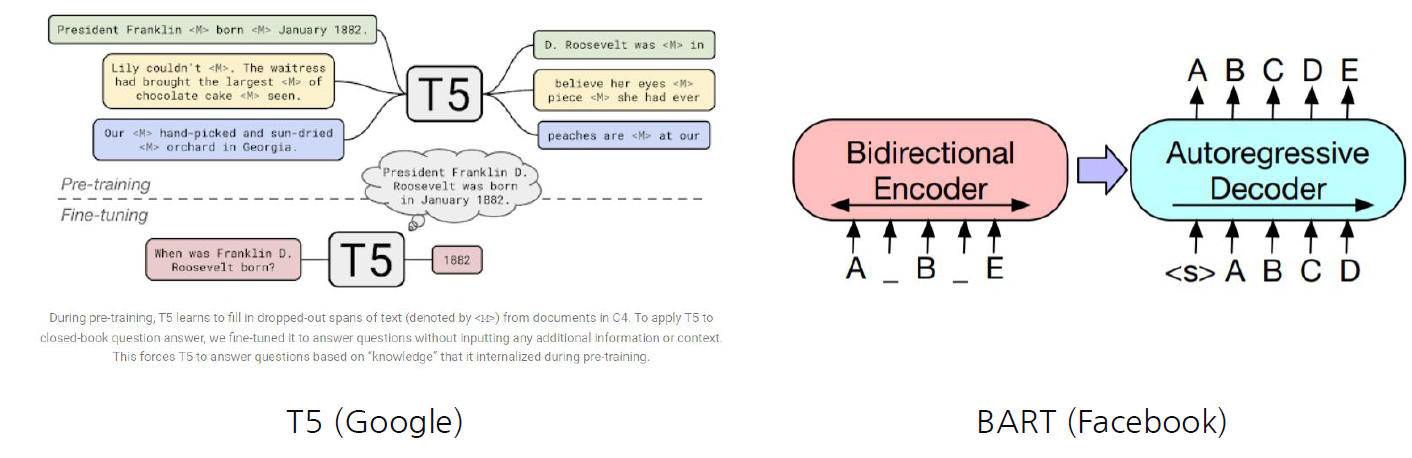
GLUE 외에도 Google의 T5(Blog), Facebook의 BART(Blog) 등의 Langauge model 평가를 위한 Benchmark가 생겼다.
Benchmark를 통해 자연어를 얼만큼 잘 생성하는지를 평가할 수 있는 Benchmark들이다.
Masking되거나 noise가 발생된 자연어에 대한 복원을 encoder가 하지 않고 decoder의 output을 통해 복원하도록 한다. 즉, decoder까지 pre-train의 범주에 넣어서 사용하도록 했다.
다국어 Benchmark
GLUE가 영어이기 때문에 다른 언어들은 영어 기반의 접근법읠 활용할 수 밖에 없었다. 해당 언어의 특성이 고려되지 않았기 때문에 영어 기반 접근법을 수정하거나 해당 언어에 특화된 방법론을 따로 고안해야하는 비효율적인 과정이 발생했다.
따라서 다국어 Benchamark들이 등장하면서 해당 언어들에 특화된 Benchmark를 직접 고안하고평가하기 시작했다.
- FLUE: 프랑스어
- CLUE: 중국어
- IndoNLU benchmark: 인도네시아
- IndicGLUE: 인도어
- RussianSuperGLUE: 러시아어
한국어 Benchmark
KLUE(Korean Lanuguage Understading Evaluation)
- 개체명 인식(NER, Naemd entity Recognition)
- 정해진 카테고리에 따라 단어를 분류
- 품사 태깅 및 의존 구문 분석(POS tagging, Dependency Parsing)
- 단어들의 품사 파악
- 단어들 간의 의존 관계 분석
- 문장 분류(Text classification)
- 자연어 추론(Natural Language Inference)
- 두 문장이 모순 관계인지, 설명 관계인지 등을 파악
- 문장 유사도(Semantic Textual Similarity)
- 관계 추출(Relation Extraction)
- 질의 응답(Question & Answering)
- 목적형 대화(Task-oriented Dialogue)
