Semantic Segmentation
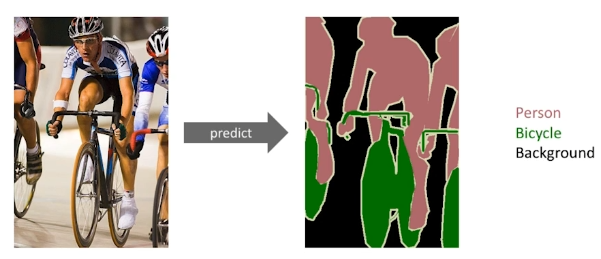
이미지를 모든 픽셀에 대한 라벨을 결정하는 문제.

ref: https://youtu.be/cuIrijsu9GY
Fully Convolutional Network
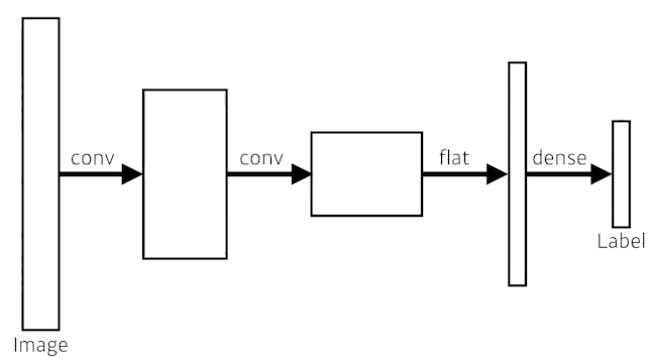
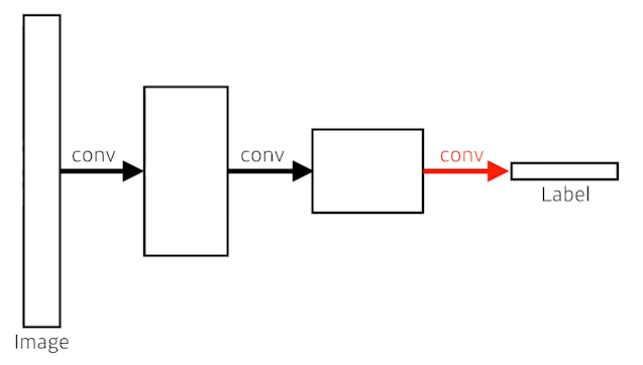
dense layer를 없애고 convolution layer를 통해 구현하여 parameter를 줄여보자.
이것을 convolutionalization이라고 한다.
하지만, 위 그림과 같이 단순히 치환만을 한 것이면 parameter의 수는 같다. 아무것도 바꾼 것이 없으니 convolutional network에서 dense layer의 역할을 해야하기 때문이다.
수식으로 표현하면 아래와 같다.

dense layer
- 4x4x16 입력을 flatten한다.
- flatten 벡터와 10차원의 벡터가 fully connected로 연결되야 한다.
- # of parameters = 4x4x16x10 = 2,560
fully convolutional network
- 4x4 filter로 convolution 연산을 하고자 한다.
- 입력은 16 channel이다.
- 즉, 4x4 filter 또한 16channel로 구성되어야한다.
- 출력은 10 channel이다.
- # of parameters = 4x4x16x10 = 2,560
사용하는 이유
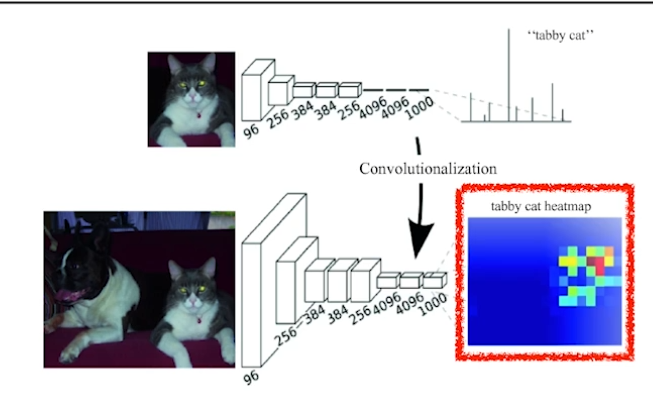
fully convolutoinal network는 input image의 dimension에 independent하다.
dense layer
- input image의 크기가 고정되어야 한다.
- 분류만 가능.
convolution layers
- input image에 크기에 구애받지 않는다.
- output이 커진다면 뒷단의 network도 커진다. convolution은 같은 kernel을 공유하기 때문이다.
- 이러면 kernel이 hitmap과도 같이 쓰일 수도 있다.
- 분류뿐만 아니라, segementation 문제도 풀 수 있다.
upsample의 필요
FCN(Fully convolutional network)를 사용하면 output의 spatial dimension(channel을 제외한 차원의 크기)은 줄어든다. 가령, 원래 100x100이었다면 10x10으로 줄어드는 것처럼 말이다.
따라서, 본래 input의 크기만큼 이미지를 늘려야한다.
Deconvolution(conv transpose)
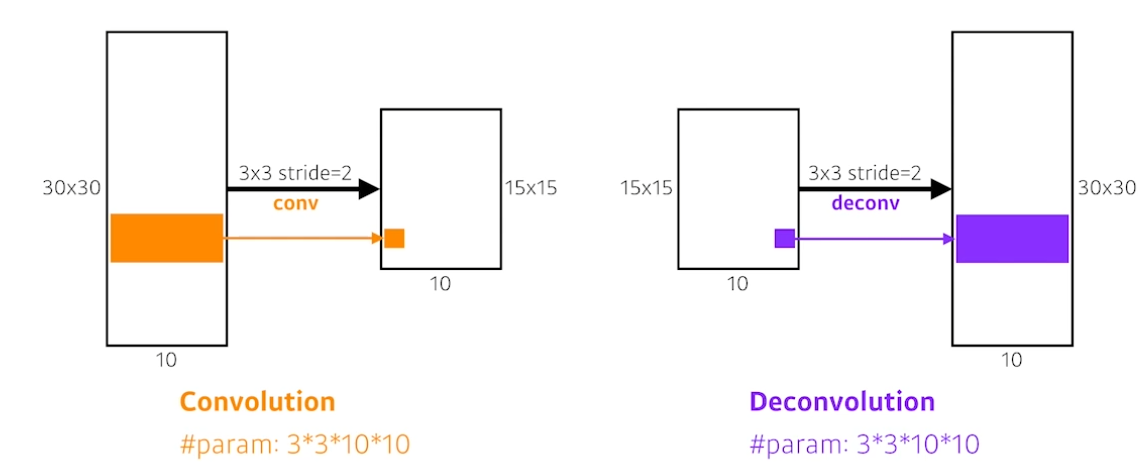
convolution의 역연산은 존재하진 않는다. 이미 정보가 합쳐졌는데, 어떠한 정보도 없이 복호화는 할 수 없는 것은 당연하다.
하지만 마치 역연산과도 같은 역할을 deconvolution에서 기대할 수 있다.
Detection
이미지 내에서 물체를 bounding box 내에서 찾는 것.
R-CNN
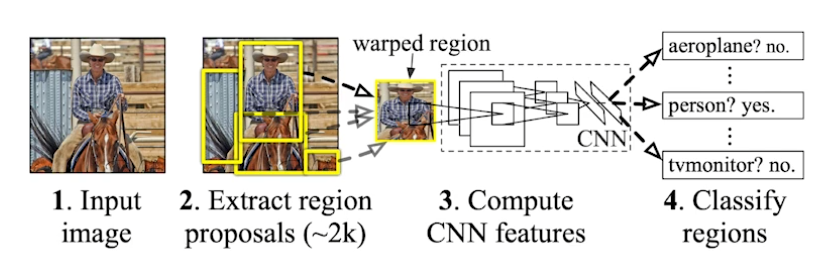
1. input을 받는다.
2. extracs around 2000 region propsals (using Selective search)
3. compute features for each proposal (using AlexNet)
4. classifies with linear SVMs.
굉장히 brute-force하다고 할 수 있다. AlexNet을 2000번이나 돌려야한다.. 당시에 CPU에서 하나의 이미지를 처리하는데 59s/m이 걸렸다고 한다. 굉장히 비효율적이다.

SPPNet
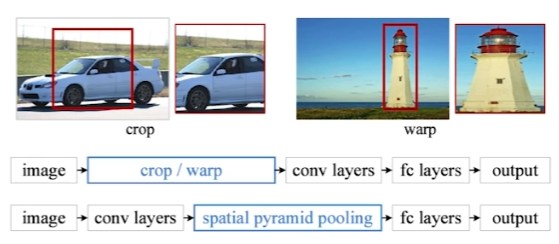
R-CNN은 모든 이미지의 region에 대해 convolution을 진행했다.
SPPNet은 다음과 같다.
1. SPPNet은 모든 이미지에 대해 convolution을 한번만 통과시킨다.
2. region에 맞는 tensor를 convolution 결과인 feature map에서 가져온다.
R-CNN과 동일한 방법이지만, convolution을 한번만 수행하게 된다.
Fast R-CNN
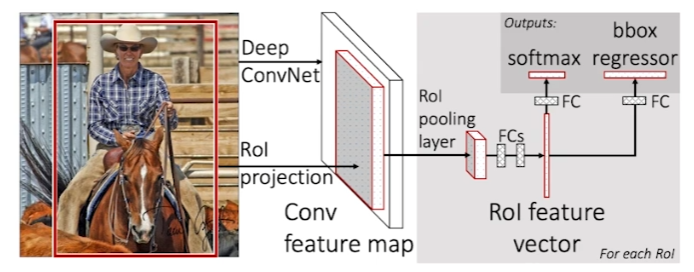
SPPNet과 굉장히 유사하다.
1. input 이미지를 받는다.
2. selective search를 통해 bounding box 영역을 미리 2000개 정도 얻는다.
3. convolution을 통해 feature map을 얻는다.
4. region별로, ROI를 통해 고정된 길이의 feature를 얻는다.
5. NN을 통해 class classification과 bounding box에 대해 회귀분석을 한다.
SPPNet과 다른 점은 ROI, 뒷단의 NN이다.
Faster R-CNN
Faster R-CNN = RPN(Region Proposal Network) + Fast R-CNN
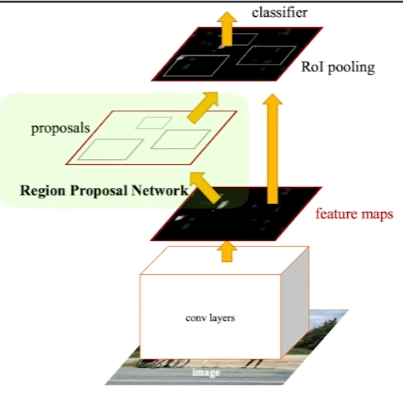
RPN = 임의의 이미지를 2000개 샘플링하여 region을 정하는 selective search를 임의의로 하지 말고, region 샘플링조차도 학습해서 수행하자!
Region Proposal Network
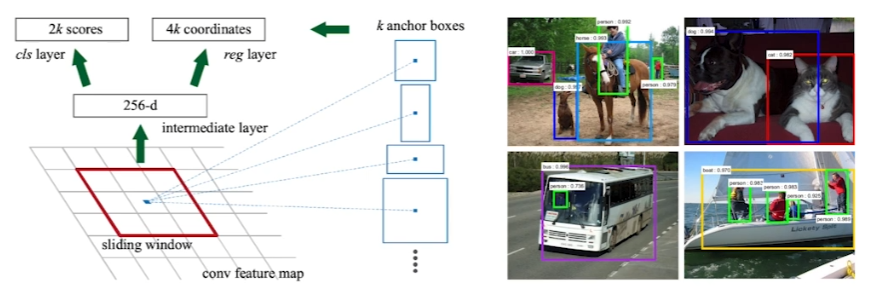
물체가 무엇인지는 모르겠지만, 최소한 물체가 있을 것 같은 region을 잡아주도록 학습한다.
위 그림을 보면 anchor box라는 것이 있다. region의 bounding box 모양을 미리 설정하는 것인데, 학습을 진행하면서 k개의 anchor box 크기를 바꿔가는 것이다.
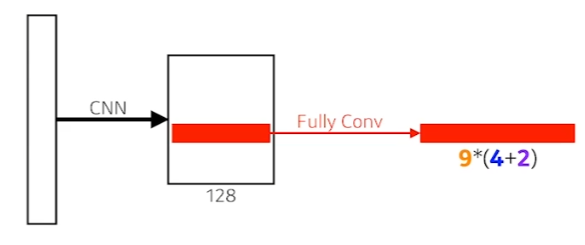
RPN의 네트워크 구조는 위와 같다.
Fully convolution network가 이미지의 전체를 돌면서 convolution을 수행한다. 이는, kernel(여기서는 fully convolution network)이 물체에 대한 정보를 가지고 있기에 가능하다고 해석할 수 있다.
9 : 3개의 다른 region 영역(128, 245, 512)와 region 영역의 비율(1:1, 2:1, 1:2)
4 : bounding box를 width, height 4방향으로 얼마나 키우고 줄일지
2 : bounding box가 쓸모있는지에 대한 classification(yes or no)

Faster R-CNN의 결과는 위와 같이 아주 잘 나온다.
YOLO
v5까지 나왔다. 볼건 v1.

- object detection이 매우 빠르다.
- baseline: 45fps / smaller version: 155fps
- faster r-cnn과 같이 bounding box를 지정하기 위한 Region proposal 작업이 없다.
- 동시에 여러 bounding box와 class classification를 매우 빠르게 수행.
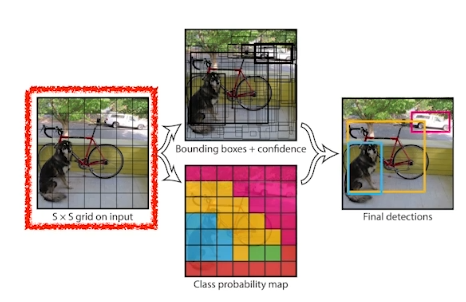
수행 순서는 다음과 같다.
- 이미지를 grid로 나눈다.
- 이미지의 중앙에 있는 grid는 물체의 bounding box 지정과 object detection을 동시에 수행해야 한다.
- 다음의 동작들을 동시에 수행한다.
- 각가의 셀들은 B개의 bounding box에 대해 예측을 한다.(B=5)
- bounding box가 쓸모있는지(confidence)를 x/y/width/height를 바꿔가며 수행
- 각각의 셀들은 class probailities를 예측한다.
- 각가의 셀들은 B개의 bounding box에 대해 예측을 한다.(B=5)
- 동시에 수행된 작업들을 통합한다.
- SxSx(B*5+C) size의 텐서 생성
- SxS = grid 안의 셀 수
- B*5 = B개의 bounding box와 offsets(x,y,w,h)와 confidence
- C = class의 수
