RNN
Sequential model
sequence data는 몇차원인지 알 수 없다. 즉, 임의의 n차원 입력에 대한 처리가 가능한 모델이 필요하다.
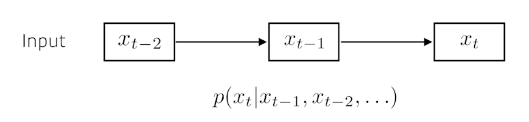
sequential model은 고정된 길이의 과거 정보들을 활용해 다음의 seuqence에 대한 예측을 하는 모델이다.
e.g., 과거의 5개 정보만을 활용해 미래의 정보를 예측하겠다.
Markov model

first-order autoregressive model
나의 현재는 바로 전의 과거에만 dependent하다가 가정. 많은 정보를 버릴 수 밖에 없는 모델이다.
하지만, joint distribution을 표현하기 매우 편리하다.
Latent autoregressive model
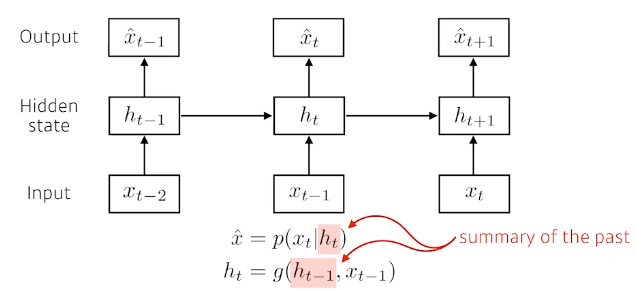
미래의 정보를 hidden state와 현재 정보만을 활용하여 예측한다.
hidden state: 바로 이전의 hidden staet와 이전 정보를 활용하여 생성. 과거 정보들을 summary해주는 역할.
RNN(Recurrent Neural Network)
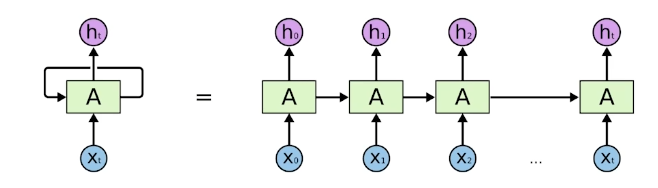
t시점에서 보는 정보는 t-1시점에서 건네준 정보다.
RNN은 그림의 왼쪽과 같은 네트워크이다. 계산된 정보를 자기 자신에게 다시 건네준다.
이를 이해하기 쉽게 time step별로 풀면 익숙한 RNN 네트워크 그림이 된다. 이 또한 fully connected layer라고 볼 수도 있다.
Short-term dependencies
fix된 룰로 과거의 정보들을 summary 한다
=> 가까이 있는 과거들은 현재에 반영이 잘 되지만, 먼 과거일수록 해당 정보들이 반영되지 않는다.
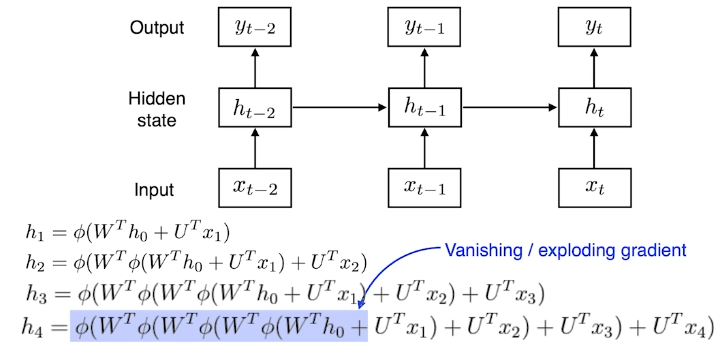
activation function을 4번이나 거쳐야지 h0에 대한 정보를 얻을 수 있다.
activation function을 sigmoid라고 생각해보자.
4번의 sigmoid를 거치면서 본래의 값을 잃어버릴 것이다.
activation function을 relu라고 생각해보자.
만약, W에 양수가 있다면 h0에는 양수가 4번이나 곱해지면서 exploding할 것이다.
LSTM(Long short term memory)
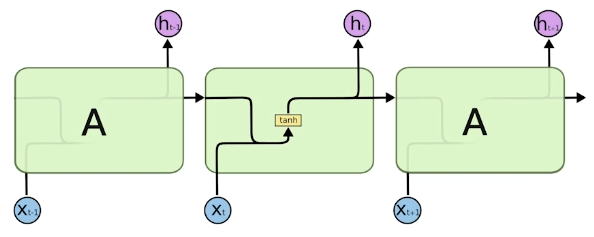
vanila rnn을 위와 같이 생각해보자. 과거의 정보들을 종합한 hidde state와 현재의 정보 x를 concatenate하고 weight에 통과시키고 tanh를 통과시켜 새로운 hidden state를 생성한다.
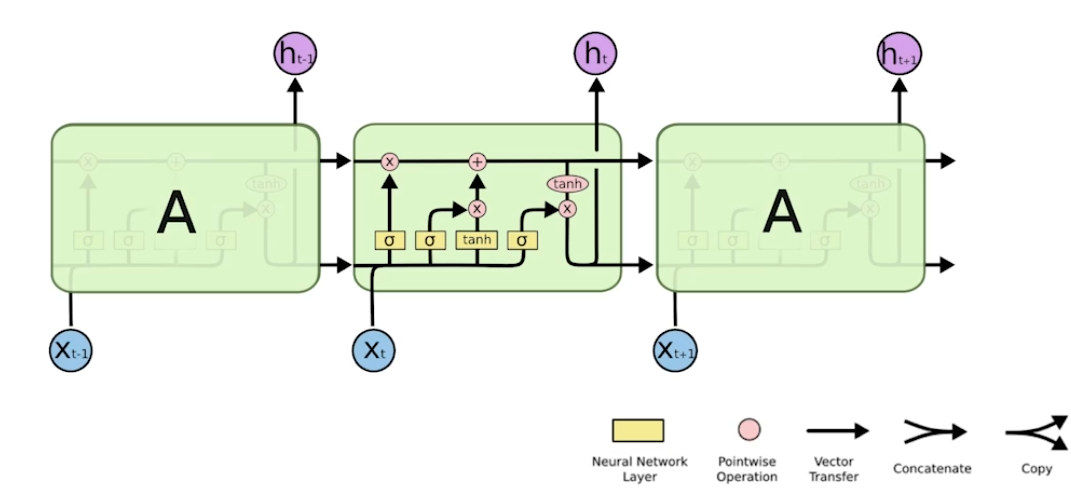
이러한 tanh를 사용하는 RNN구조를 발전시킨 것이 LSTM이다.
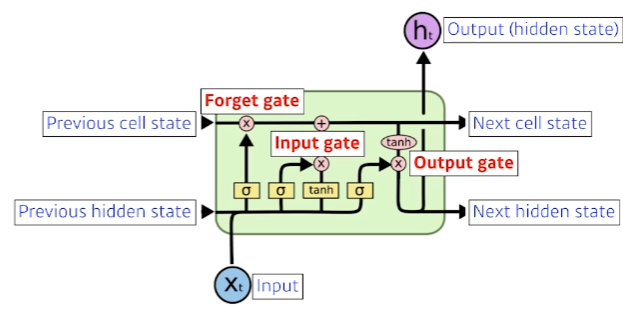
LSTM의 한가지 요소만을 가져왔다.
= t번째 step의 input. word embedding 결과, word 그 자체 등의 입력
= t번째 step의 output. hidden state
Previous cell state
- LSTM 밖으로 나가지않고 네트워크 내부에서만 돈다.
- 0부터 t까지의 정보를 summarize.
Previous hidden state
- 이전 hidden state를 기반으로 t 시점의 hidden state를 계산
- output과 t+1 시점의 lstm으로 출력.
Core idea of LSTM
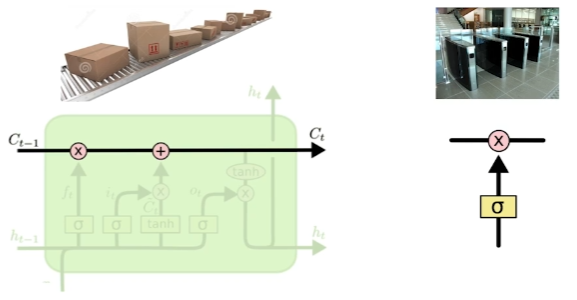
마치 컨베이어 벨트에서 필요한 정보만 취하고, 버릴 정보를 버리는 과정을 반복하는 과정을 gate를 통해 구현했다.
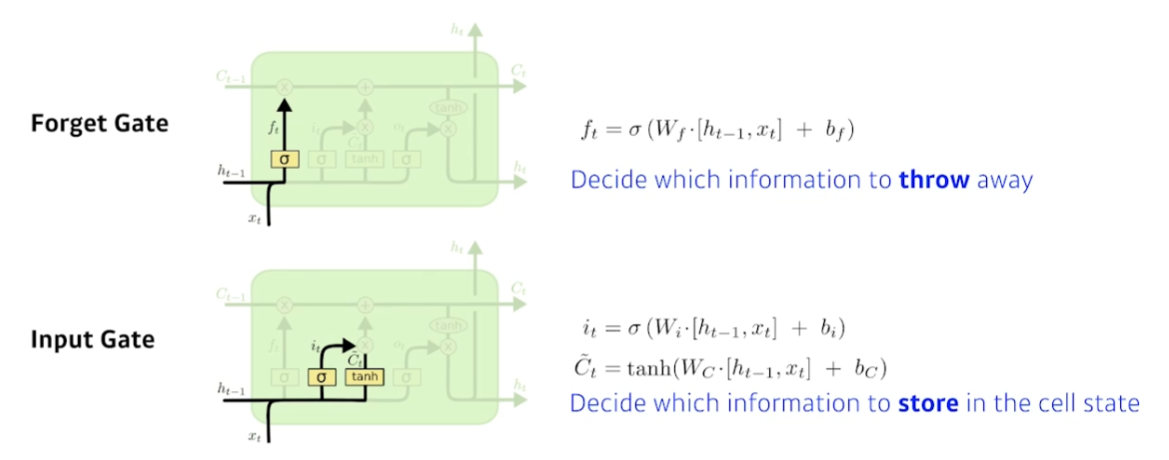
Forget Gate
- sigmoid를 통과시키기 때문에 항상 0에서 1사이의 값을 가진다.
- 버리고 살릴 정보를 선택한다.
Input Gate
- Cell state에 올릴 정보를 선택한다.
- : 업데이트할 정보를 결정
- : 이전 hidden state와 현재 입력을 통해 cell state 후보군 생성
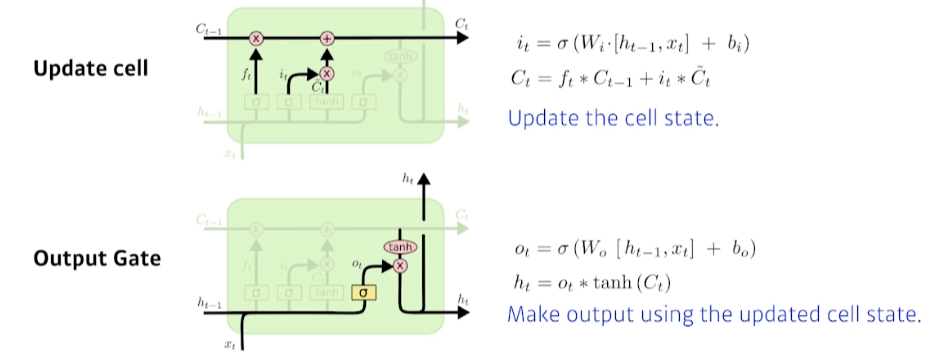
- Update cell: forgat gate의 정보와 이전 cell state 정보를 결합하고, input gate의 정보와 현재 cell state 후보군을 결합한다.
- 즉, 버릴건 forgat gate를 통해 일정 부분 거르고, 새로 받을건 input gate를 통해 일정 부분 얻는다.
- Ouput gate: 과 현재 입력을 sigmoid 통과시킨결과와 를 활용해 새로운 hidden state를 생성한다.
Gated Recurrent Unit
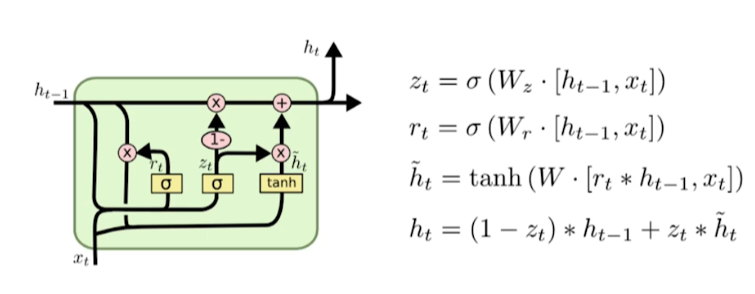
- reset gate와 update gate만 존재한다.
- cell state, hidden state, output gate가 없다.
- lstm보다 gru를 활용할 때 성능이 더 좋은경우가 많다.
- parameter 수를 줄이는 것이 학습도 쉽고, generalize performance가 좋기 때문.
conclusion
요즘은 lstem, gru 둘 다 거의 안 쓴다. transformer가 훨씬 좋기 때문이다..
