Extraction-Based MRC
질문의 답변이 항상 주어진 지문(context)내에 span으로 존재.
답변을 생성하지 않고 답변을 context에서 찾는 것으로 문제를 좁힐 수 있다.
e.g.,) SQuAD, KorQuAD, NewsQA, Natural Questions
이러한 dataset들은 HuggingFace Datsets에서 다운 받는게 제일 편하다.
Metric
Exact Match(EM) Score
예측값과 정답이 character 단위로 완전히 일치할 경우에만 1점 부여. 하나라도 다르면 0점.
F1 score
예측값과 정답의 overlap을 비율로 계산하기 때문에 [0, 1]가 점수의 범위가 된다.

Overview
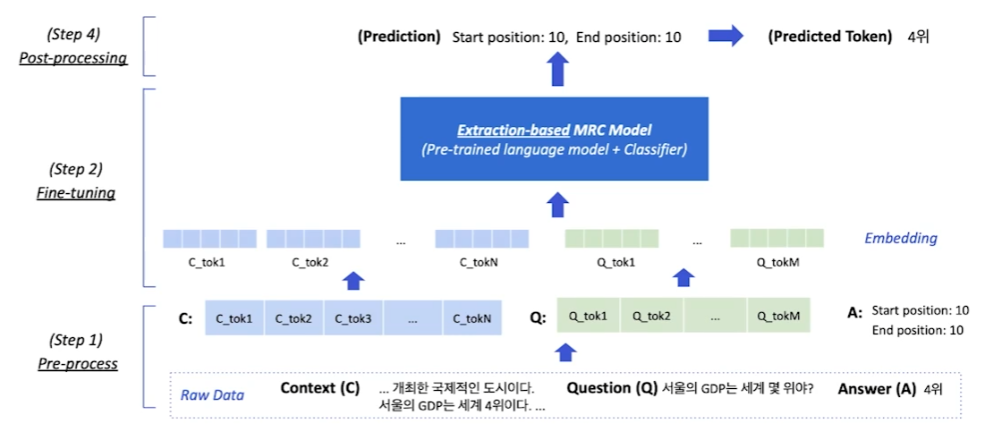
Pre-processing
Tokenization
- 최근에는 Byte Pair Encoding(BPE)를 많이 사용한다.
- Out-of-vocabulary(OOV) 문제 해결 가능
- 정보학적으로 이점(?)
- BPE 중 WordPiece Tokenizer 사용할 것
- 자주 나오는 token 위주로 구분짓는다.
Attention mask
- Positional Embedding에서 발생
- 보통 0은 무시, 1은 연산에 포함된다는 의미
Token type IDs
- Question에는 0, Context는 1로 mask를 줘서 1이 나타나는 범위에서만 답을 찾도록 유도
- 따라서 PAD 토큰도 0으로 처리
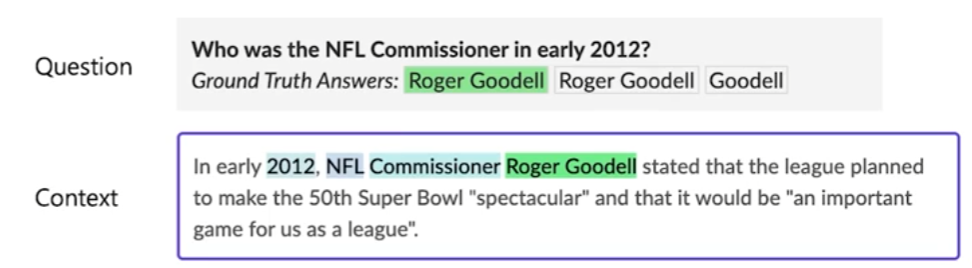
답의 위치
Tokenization을 하면 답의 인덱스도 달라질 것이다. 이에 대한 전처리가 필요하다.
보통은 start, end index만 알면 되기 때문에 답을 포함하고 있는 span을 찾기만 하면 된다.
Fine-tuning
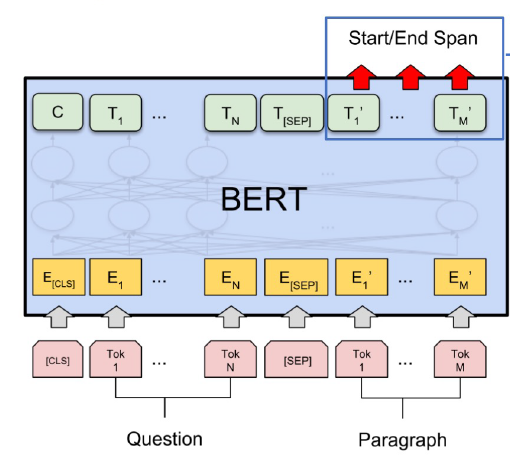
Context의 모든 token들이 두 개의 Output을 출력하도록 BERT의 출력단을 변경한다.
- 해당 token이 답의 시작 token일 확률
- 해당 token이 답의 끝 token일 확률
확률값들을 모두 구할 수 있다면 groun truth와 비교해서 cross-entropy loss를 구할 수 있다. 이후의 과정은 익히 알고 있듯이 softmax를 취하고 negative log likelihood를 구하면서 학습이 진행된다. ref
Post-processing
불가능한 답 제거
- End position이 start position보다 앞에 있는 경우
- 예측한 위치가 context 범위 밖인 경우
- max_answer_length보다 긴 경우
*최적의 답 찾기
1. Start/end position prediction에서 score(logits)가 가장 높은 N개를 각각 찾는다.
2. 불가능한 start/end조합을 제거한다.
3. 가능한 조합들을 score의 합이 큰 순서대로 정렬한다.
4. Score가 가장 큰 조합을 최종 예측으로 선정한다.
5. Top-k가 필요한 경우 차례대로 내보낸다.
