이 또한 notion에 여러번 정리했엇던 내용이다. 부캠에서 배운 내용만을 기준으로 재정리해봤다.
그 동안 정리했던 gradient descent의 내용은 아래 링크에 있다.
https://naem1023.notion.site/Gradient-descent-429308fbd0184aaab90c0ac50e90b526
https://naem1023.notion.site/ML-68740e6ac0db42e9a01b17c9ab093606
Gradient descent
사용 목적
이전 포스팅에서는 gradient descent를 사용하여 선형회귀분석을 알고리즘적인 구조만 만들어봤다. 이번에는 수학적으로 어떻게 쓰였는지 알아본다.
선형회귀분석에서의 사용
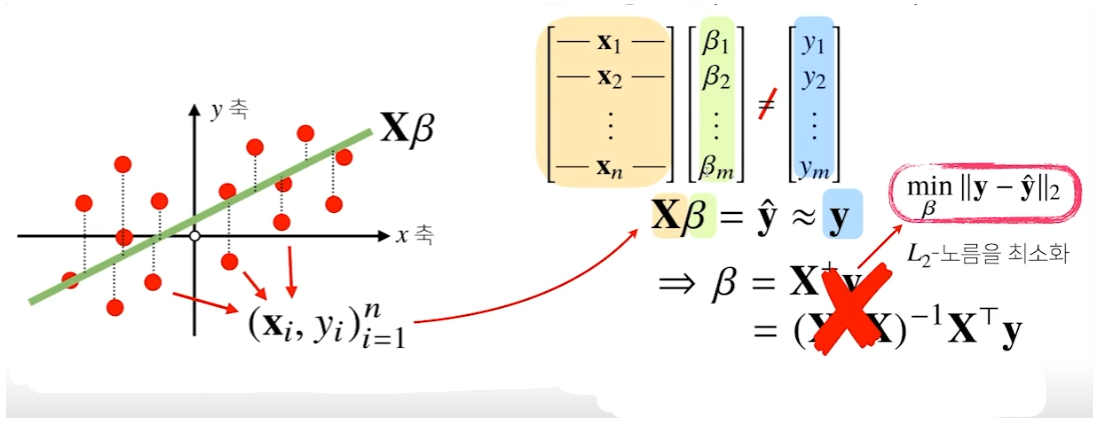
선형회귀분석의 목적은 실제 데이터 값들인 y와 예측치인 yhat의 L2 norm값을 최소화하는 것이다.
본래 Moore-Penrose 역행렬을 통해 구할 수 있으나 실제로는 사용이 거의 불가능하다. yhat을 gradient descent를 통해 구해보자.
선형회귀 목적식(cost function)
일반적으로 cost function이 뭔지 설명해주고 gradient descent를 풀어가는 블로그 포스팅들이 대부분이라 이부분에 대한 이해가 어려웠다. 가령, 상단에 링크한 노션 정리글에서도 J(Θ0, Θ1)에 대해서 미분을 풀어나가는 것처럼 말이다.
부캠에서 L2 norm에 대한 접근으로 잘 알려줘서 이해가 쉬웠다.
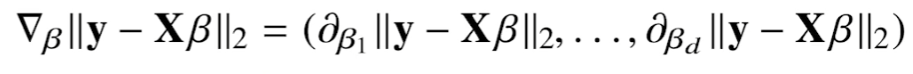
결과적으로 이상적인 yhat을 구하는 것이 목적이기 때문에 L2 norm이 아니라, L2 norm의 제곱을 목적식으로 설정해도 무방하다.
위 식에서 의도해야 하는 것은 목적식을 최소화하는 β를 찾는 것이다. 이에 대한 방법론으로 우리는 graident descent를 설정한 것이다.
즉, 앞선 포스팅의 알고리즘을 사용하기 위해서 목적식의 gradient vector를 구해야한다.
β의 k번째 요소에 대한 목적식의 편미분
β의 k번째 요소에 대한 편미분식은 다음과 같다.
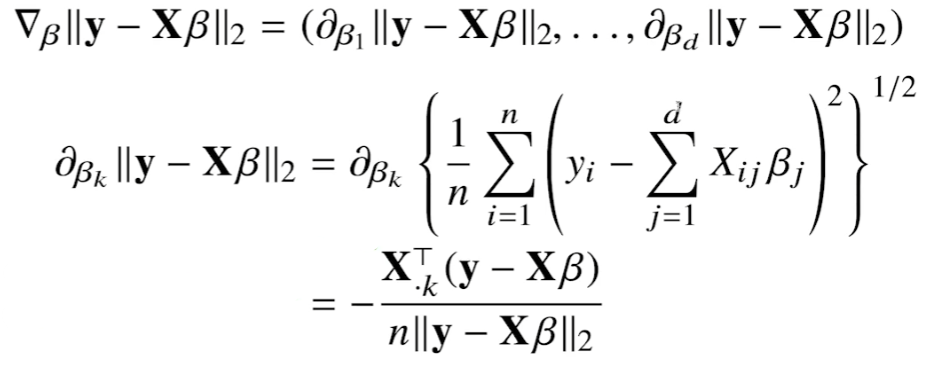
이 때, 일반적인 L2 norm과 다르게 평균을 구하는 것이 중요하다.
수식 중에서 다음과 같은 기호가 있는데
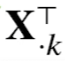
이는 행렬 X의 k번째 열벡터(column)를 전치시킨 것이라는 뜻이다.
목적식의 gradient vector
β에 대한 gradient vector는 다음과 같다. β의 k번째 요소에 대한 편미분식을 gradient vecotr에 나열한 구조이다.
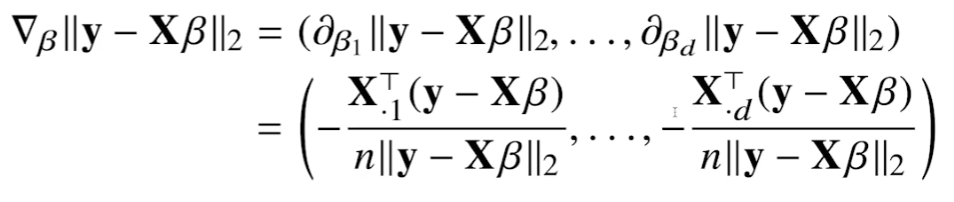
이를 간략화시키면 아래와 같다.
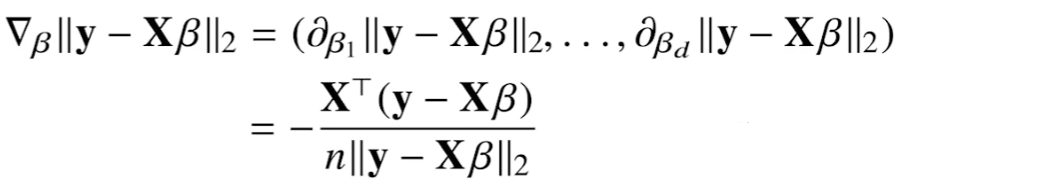
복잡한 과정을 거쳤지만 결국, Xβ를 β에 대한 미분한 결과인 XT만 곱해진 형식이다.
목적식을 최소화하는 gradient descent algorithm
t번째 단계에서 t+1번째 coefficient인 β를 업데이트하는 방법은 다음과 같다.
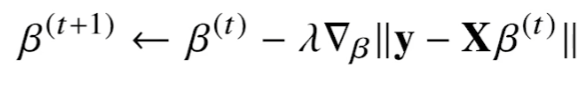
gradient descent의 의도대로 목적식을 최소화하는 방향으로 t번째 β에서 gradient vector를 빼주는 형태이다.
위에서 계산된 gradient vector를 대입하게 되면 부호가 바뀌게 된다.
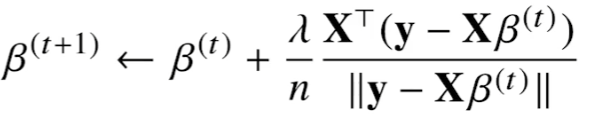
L2 norm의 제곱에 대한 목적식
L2 norm에 대해서만 계산해보니 gradient vector가 매우 더럽게 나왔다. 제곱에 대해서 계산하면 루트가 지워질 것이니 깔끔해질 것이다.
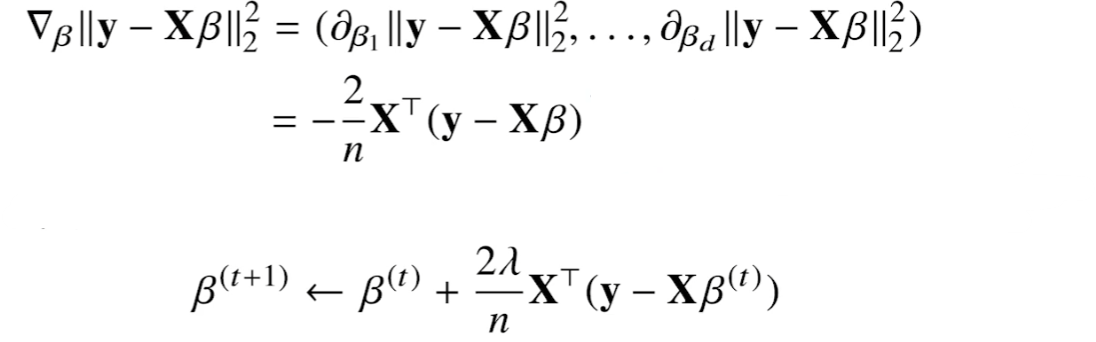
최종적인 gradient descent algorithm
# norm: l2 norm을 계산해주는 함수
# lr: 학습률
# T: 학습횟수
for t in range(T):
error = y - X @ beta
grad = - transpose(X) @ error
beta = beta - lr * gradgradient descent의 보장성
적절한 학습횟수와 학습률을 사용하면 미분가능한 convex function에 대해서는 항상 수렴이 보장된다.
선형회귀의 목적식은 β에 대해 convex function이기 때문에 수렴을 보장한다.
하지만 비선형회귀는 β에 대해 convex function일 것이라는 보장이 없기 때문에 수렴을 보장하지 못한다.
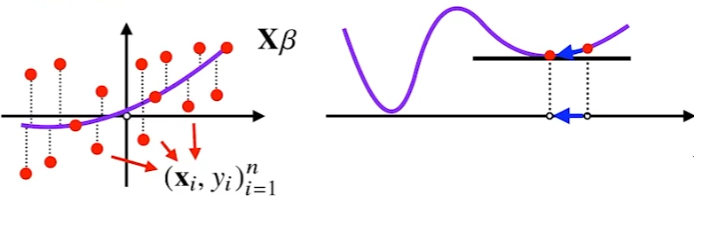
SGD(확률적 경사하강법)
SGD(stochastic gradient descent)는 모든 데이터를 사용하지 않고 일부 데이터만 활용해 업데이트를 진행한다.
만능은 아니지만 cost function이 convex하지 않은 경우가 대부분인 딥러닝의 경우, SGD가 gradient descent보다 실증적으로 더 낫다는 것이 검증됐다.
교수님은 모든 데이터를 활용한 일반적인 gradient descent와 비교하여 일부분의 데이터만을사용하는 SGD는 확률적으로 본래 gradient descent의 결과와 유사하다는 것이 실증됐다고 하셨다.
이 때 사용되는 일부분의 데이터를 mini batch라고 부른다.
관례적으로 데이터 한개만 사용하면 SGD, 일부분의 데이터들을 사용하면 mini batch SGD라고 한다.
효율성
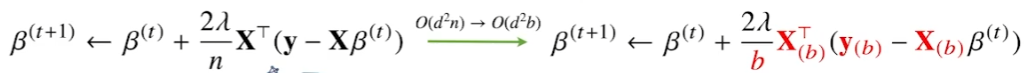
전체 데이터 (X, y)가 아닌 mini batch (Xb, yb)를 사용했기 때문에 연산량은 b/n으로 감소한다.
또한 데이터를 분할하는 효과가 발생하기 때문에 GPU의 메모리를 효율적으로 사용할 수 있다.
원리
기존 gradient descent는 전체 데이터를 활용하여 nabla theta L을 계산한다. 이는 아래 그림과 같다.
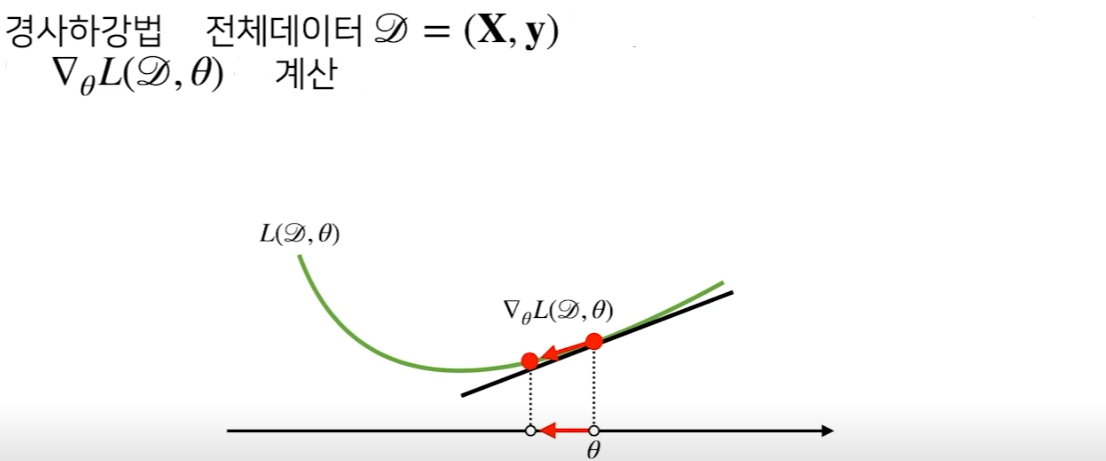
SGD는 아래와 같이 mini batch인 D(b)를 사용해 gradient vector를 계산한다.
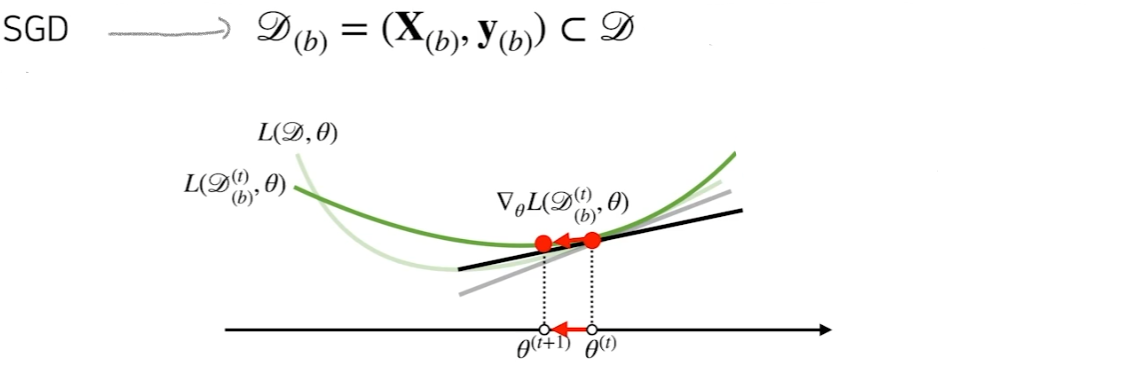
이는 본래 gradient descent와 유사한 방향성을 제공해준다.
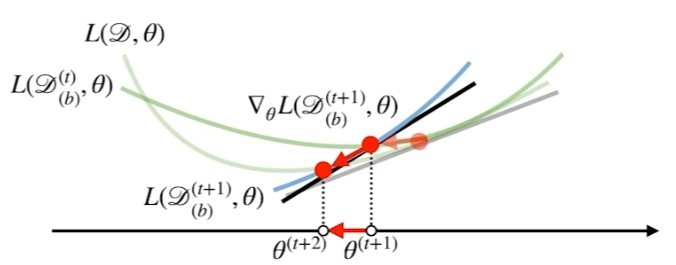
또한 D(b)가 매 step별로 바뀌기 때문에 목적함수 또한 매 step마다 달라진다.
따라서 극소점에 도달한다고하더라도 목적함수가 달라지기 때문에, 극소점에서 탈출하는 경우가 확률적으로 발생한다.
gradient descent와 비교
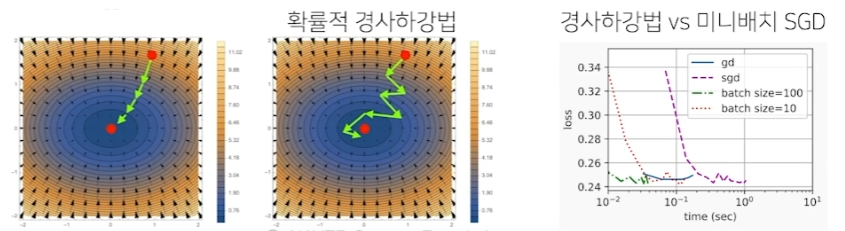
convex에서는 gradient descent보다 비효율적일수도 있다. 하지만 일반적인 머신러닝의 목적함수에서는 보다 효율적이다.
