ai-math
1.이전에 정리했던 내용들

tistory, notion에 산개했있는데 ML 관련된 notion 정리글들만 업로드.https://naem1023.notion.site/ML-68740e6ac0db42e9a01b17c9ab093606
2.Matrix, Vector
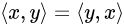
1학년 공수, 선대 이후로 수학 지식들이 삭제됐다.. 되새기는 겸으로 numpy 기호들과 기록.numpy에서 +, - 가능.Hadmard Product : 은 모양의 vector끼리 성분곱하는 것X · Y원점에서부터 벡터까지의 거리.L1 norm = 변화량의 절대값의
3.Gradient descent 기본
여러번 정리했던 내용인데 부캠에서 배운 내용 중심으로 다시 정리해봤다.f(x)미분값을 x에 더하며 함수의 극대값의 위치를 구할 때 사용.즉, 목적함수를 최대화해야 할 때 사용.f(x)미분값을 x에 빼면서 함수의 극소값의 위치를 구할 때 사용.즉, 목적ㅎ마수를 최소화해야
4.Gradient descent 증명
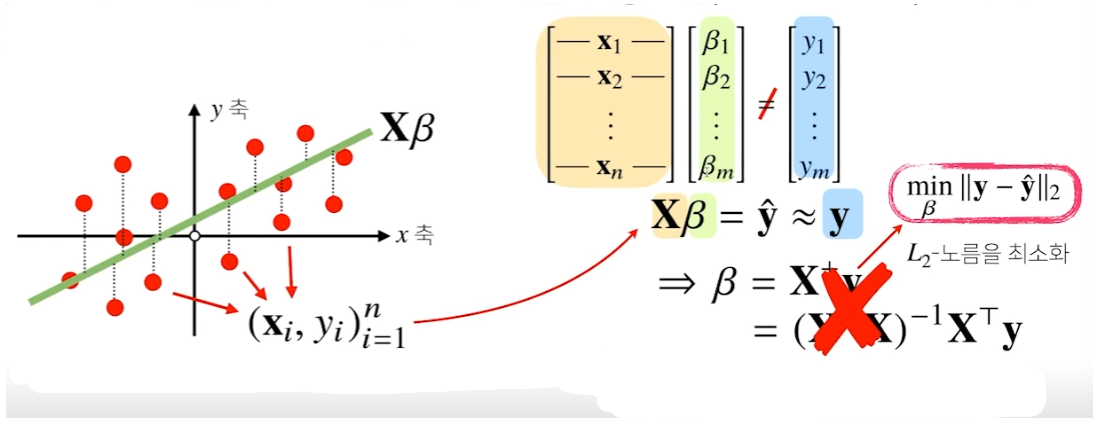
이 또한 notion에 여러번 정리했엇던 내용이다. 부캠에서 배운 내용만을 기준으로 재정리해봤다.그 동안 정리했던 gradient descent의 내용은 아래 링크에 있다.https://naem1023.notion.site/Gradient-descent-429
5.Neural network
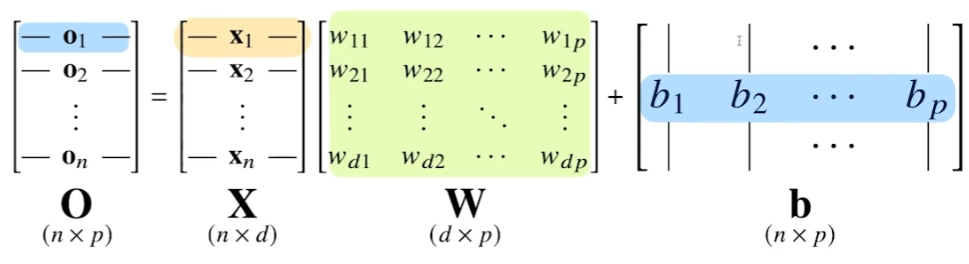
행렬의 역할을 아주 잘 활용한 전형적이 예시가 NN이다.X 행렬에서 데이터를 모아둔다. W에서는 X의 데이터를 다른 차원으로 보내주는 역할을 한다.b 행렬은 y 절편을 열벡터에 한꺼번에 더해주는 역할을 한다.본래 (X, d) 차원이었던 X 행렬은 (n, p) 차원으로
6.확률론
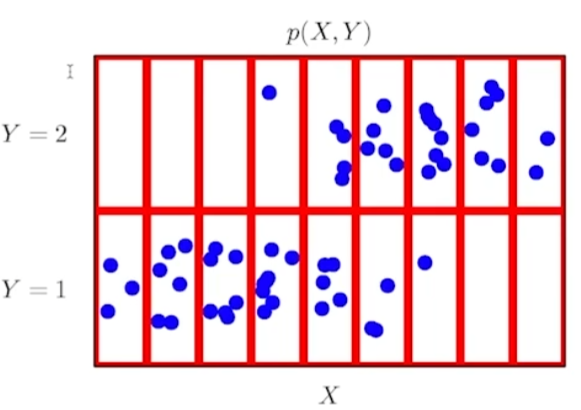
작년에 lieklihood 관련해서 정리하면서도 이해가 잘 되지 않았던 내용들이다. 부캠 내용들 위주로 다시 재정리했다.딥러닝은 확률론 기반의 기계학습 이론이 바탕이다.데이터 공간 (X x y)에서 확률분포 D는 데이터 공간에서 데이터를 추출하는 분포.이 때, y가 상
7.통계론
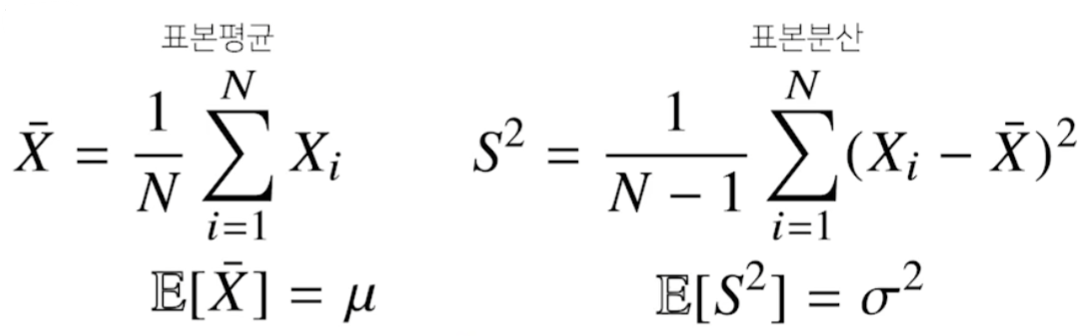
통계적 모델링 = 적절한 가정으로 확률 분포를 추정하는 것기계학습과 통계학이 공통적으로 추구하는 목표.유한한 데이터만 관찰해서 모집단의 정확한 분포 예측은 불가능하다.=> 근사적으로 확률분포 추정데이터가 특정 확률 분포를 따른다고 선험적(a priori)으로 가정그 분
8.베이즈 통계학
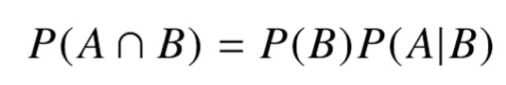
이것도 고등학교 때 배운 내용들이 많은데 까먹은 것도 많다...위 조건부확률은 사건 B가 일어났을 때, 사건 A가 발생할 확률을 의미.위 수식은 A라는 새로운 정보가 주어졌을 때, P(B)로부터 조건부확률을 계산하는 방법을 제공한다.D : 새로 관찰하는 데이터Θ : h
9.CNN
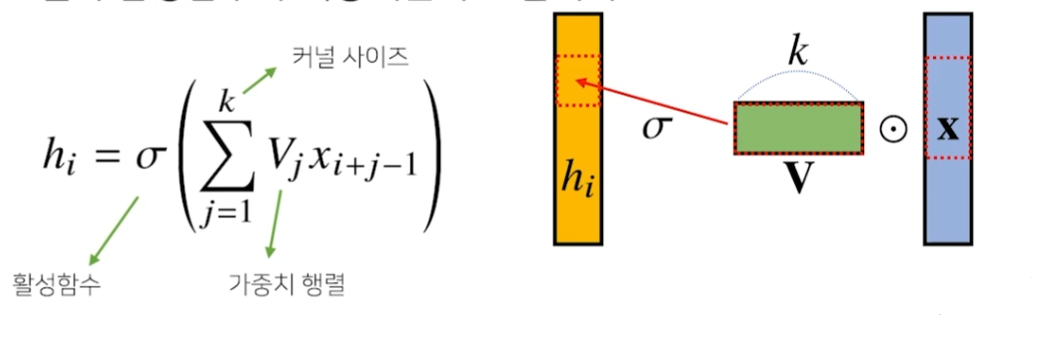
MLP의 fully conneted layer는 가중치 행렬이 매우 크다.반면 CNN은 kernel이라는 고정된 입력벡터를 사용한다.모든 i에 대해 커널 V를 적용한다.커널의 사이즈만큼 x 상에서 이동하며 적용한다.활성화 함수를 제외한 convolution 연산도 선형
10.RNN
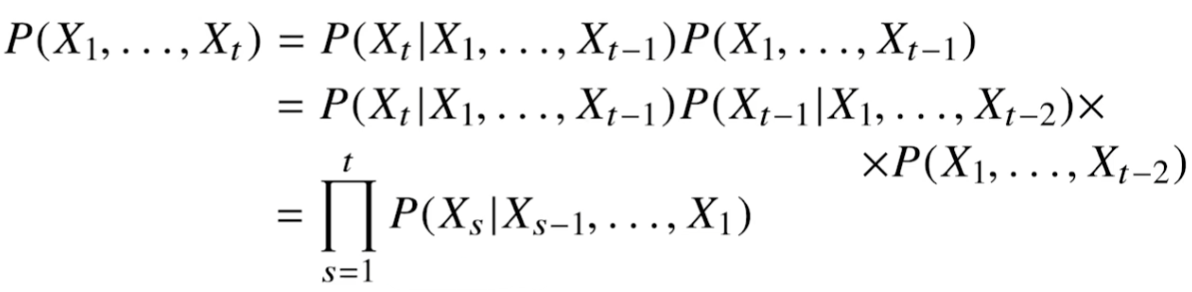
소리, 문자열, 주가 등 순차적으로 진행되어야 하는 데이터.독립동등분포(iid, independent and identically distributed)를 위배하기 쉽다. \- 가령, '개가 사람을 물었다'와 '사람이 개를 물었다'는 데이터 분포, 빈도, 의미 등