Background
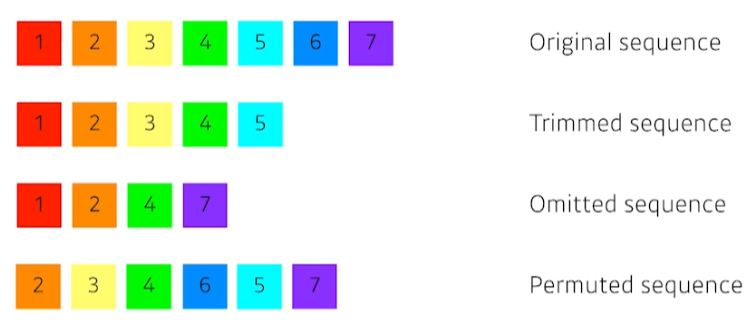
기존의 rnn들도 sequence data들을 다룰 수 있지만, 위와 같이 원본 데이터에서 일부 데이터가 빠진 sequence data들에 대해서 다루기는 매우 어려웠다.
이를 다루기 위해 transformer가 등장했다.
Transformer
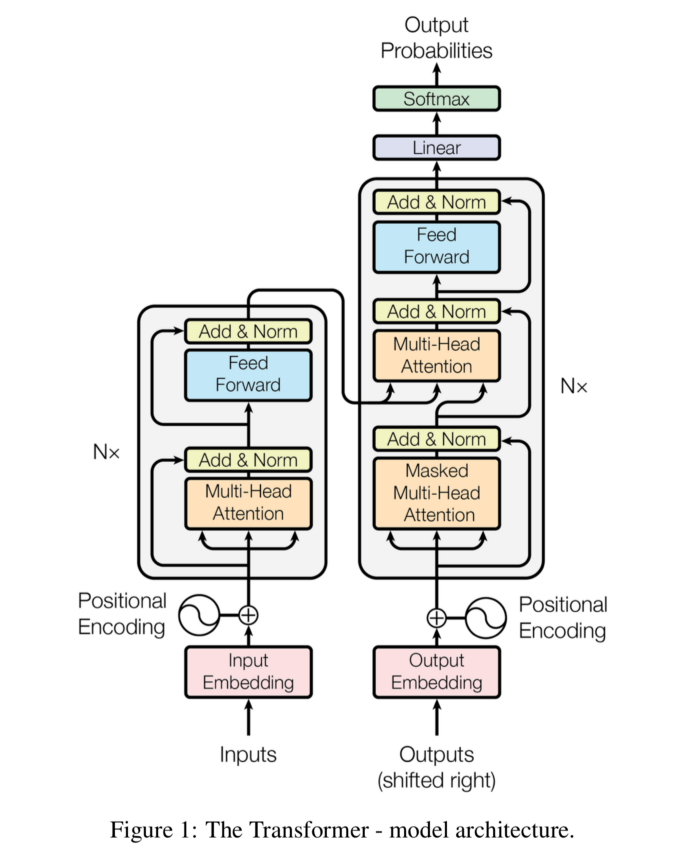
RNN처럼 재귀적인 구조가 없다.
Tranasformer is the first sequence transduction model based entirely on attention.

본래는 위와 같이 기계어 번역을 위한 모델이었다. 하지만 transformer는 sequential data를처리하고 이를 encoding하는 방법론이기 때문에, 기계어 번역 외에서도 사용할 수 있다.
최근에는 transformer, self atttention이 거의 모든 분야에서 사용되고 있다.
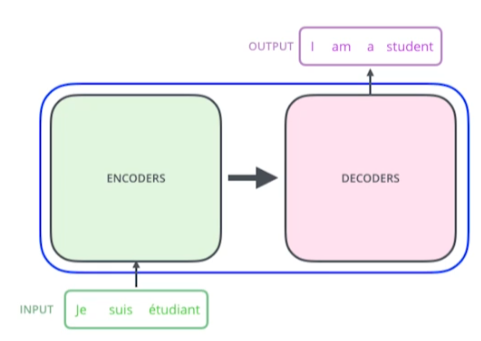
transformer는 위와 같이, sequence to sequence model이다. 좀 더 자세하게 뜯어보자.
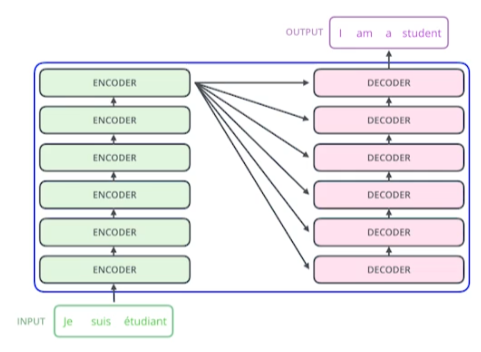
RNN과 다르게 재귀적으로 돌지 않는 차이점이 여기서 나타난다. RNN이라면 3개의 단어가 입력일 때, 재귀적으로 3번 돌면서 결과를 출력할 것이다.
하지만 transformer는 3개의 단어든, 100개의 단어든 한번의 encoding 과정을 통해 encoding vector를 한번에 만들어낸다. 출력을 위해서는 재귀적으로 무언가를 한다고 한다.
Key concept of transformer
- n개의 단어가 encoding에서 어떻게 한번에 처리 되는지?
- encoder과 decoder 사이에서 어떤 정보가 오가는지?
- decoder가 어떻게 generation할 수 있는지?
Encoder
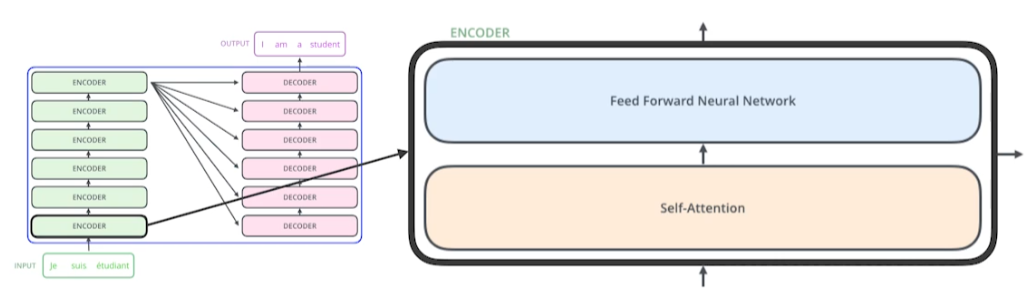
입력으로 모든 벡터를 받는다.
Self-attention이 encoder과 decoder에서 중요한 역할을 한다. 뒤의 Feed forward nn은 우리가 아는 흔한 mlp이다.
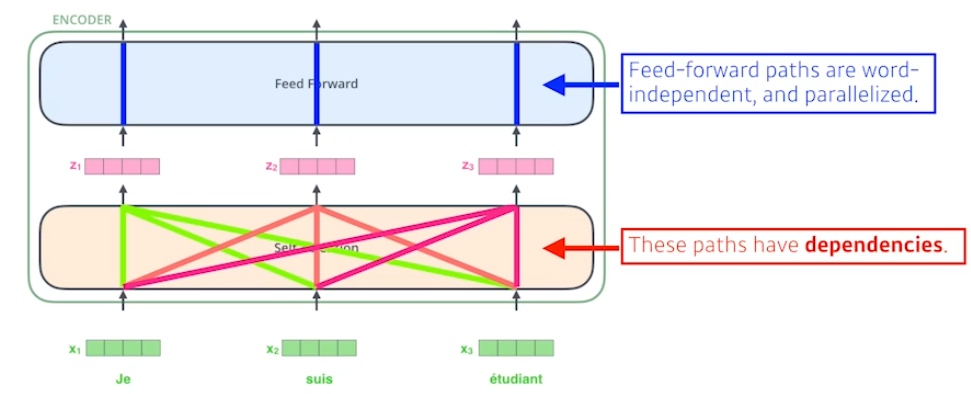
- self-attention은 n개의 벡터를 받는다.
- 입력 벡터 을 로 변환하기 위해 모든 를 활용한다.
- 벡터를 만들기 위한 모든 paths들은 서로 종속적이다.
- 를 feed forward nn을 통과시킬 때는, 병렬적으로 비종속적으로 통과시킨다.
Self-attention
아래 문장을 분석하고자 한다면 아래와 같은 종속적인 네트워크를 구성해준다.
The animal didn't cross the street because it was too tired.
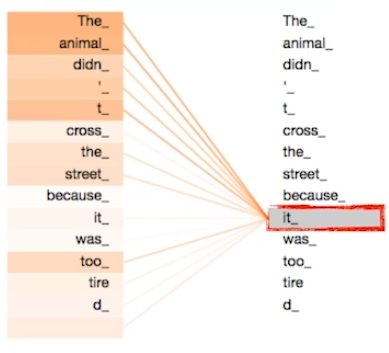
인간은 당연하게 it이 animal을 나타낸다고 생각한다. 이를 self-attention을 통해 학습하면 그림과 같이 animal 부근에서 강한 종속성을 나타낸다.
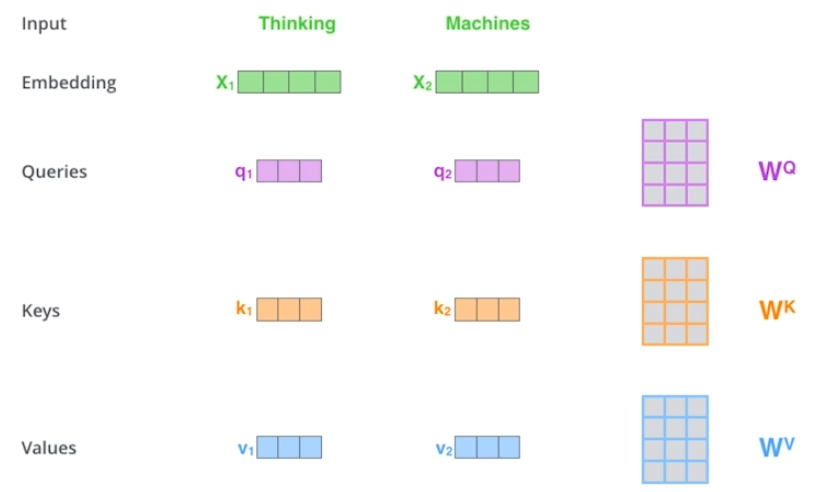
Query, Key, Value 벡터들은 단어별로 계산된다. (=embedding)
= 한번의 embedding으로 query, key, value가 1개씩 계산된다.
Encoder 계산 과정
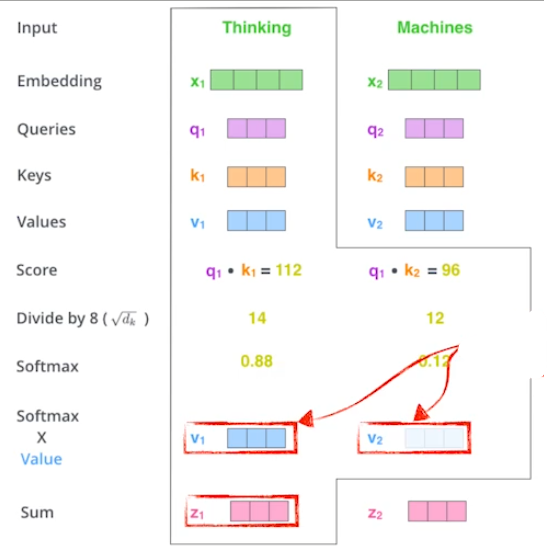
강의를 들어보니 말로 설명하면 정말 어렵고, 수식으로 설명하면 매우 간단했다.
말로 정리하면 다음과 같다.
- score = query와 key를 내적(inner product)
- = key vector의 차원
- softmax result = score를 로 나눈 값에 softmax를 적용
- sum = softmax 결과 x value
이를 행렬과 수식을 통해 설명하면 아래와 같다.
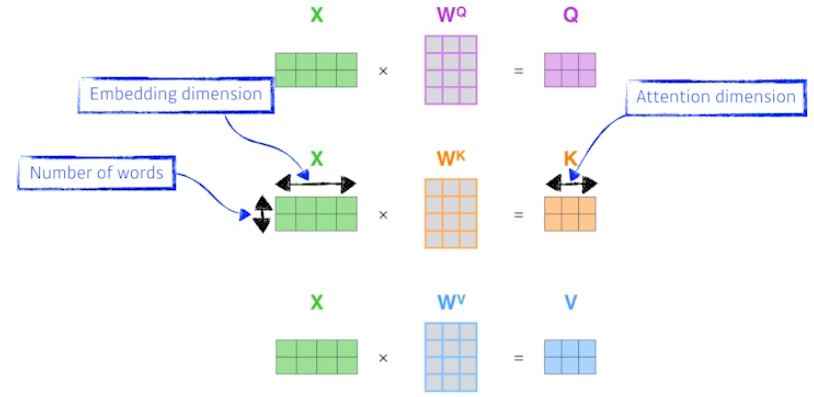
입력 X를 행렬로 표현한다.
- row = nubmer of words
- column = embedding dimension
query, key, value에 대한 각각의 weight 행렬을 X와 곱해서 query, key, value를 계산한다.
- attention dimension = key vector의 dimension
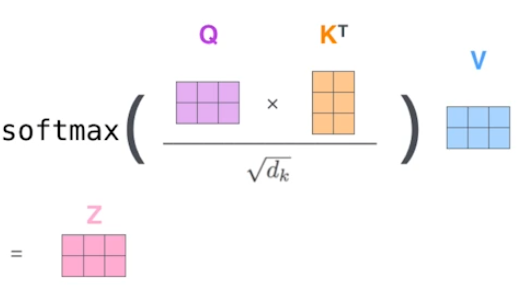
나머지는 말로 설명한 부분을 그대로 수식으로 옮긴 것이다.
- softmax = row-wise softmax
- dim(V)는 dim(Q), dim(K)와 달라도 된다.
- 구현상 편의를 위해 보통은 모두 같게 만든다.
Transformer의 특징
mlp, cnn은 입력이 고정된다면 출력도 반드시 고정된다.
하지만 transformer는 하나의 입력이 고정되더라도, 다른 입력들이 달라진다면 출력이 달라질 여지가 있다.
=> 훨씬 더 많은 것을 표현할 수 있다.
=> 더 많은 계산이 필요하다.
-> 입력이 무한정 길어질 수가 없다.
MHA(Multi-head attention)
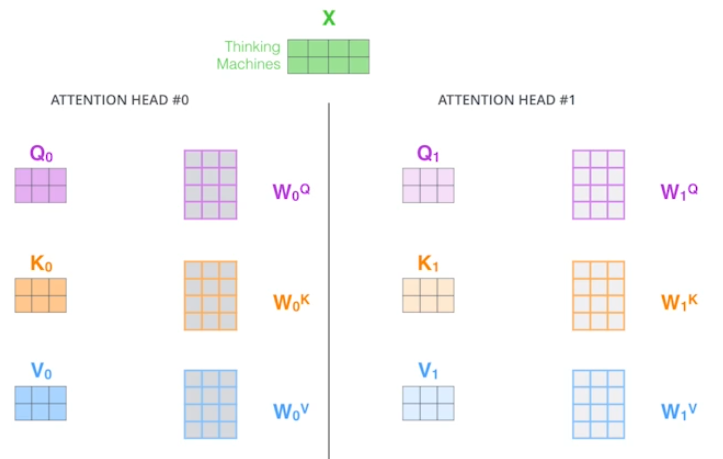
하나의 입력에 대해 query, key, value를 하나가 아닌 여러개 만든다.
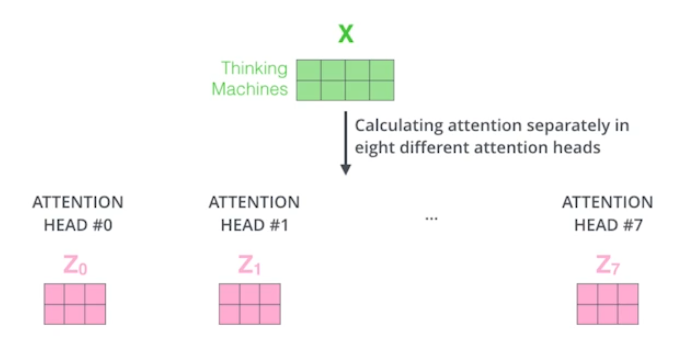
즉, 하나의 입력에 대해 n개의 attention을 적용하면 n개의 출력이 나올 것이다.
관건은 입력과 출력의 차원을 맞춰줘야 하는 것이다. 이는 결과들을 하나로 concatenate하고 입력 차원으로 맞춰주는 행렬을 곱해주면서 해결한다.
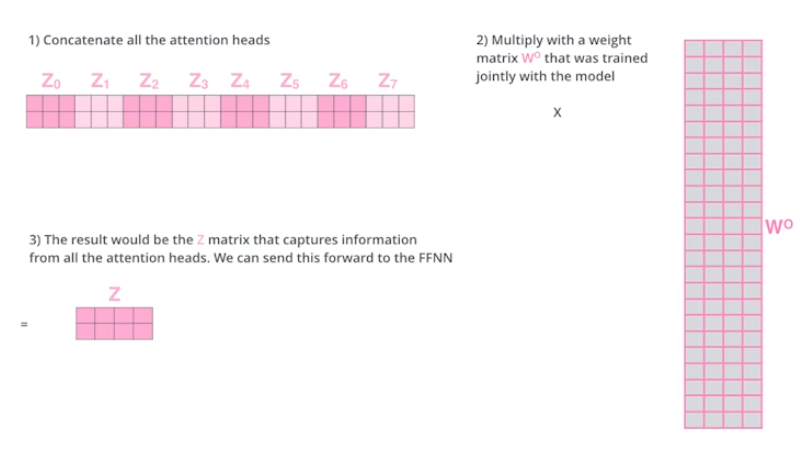
이러한 모든 과정을 그림으로 정리하면 아래와 같다.
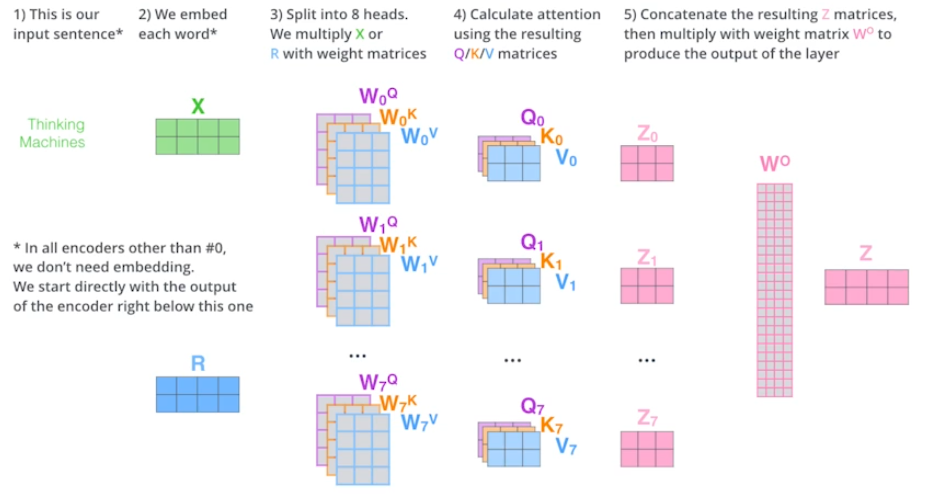
ref: https://jalammar.github.io/illustrated-transformer/
이론적으로는 위 그림처럼만 하면 되지만, 실제 구현은 다르다고 한다.
가령, 입력 X가 100차원이면 이를 10개로 나눠서 한다고 말씀하신거 같은데.. 실습 포스팅에서 설명해야겠다.
Positional encoding
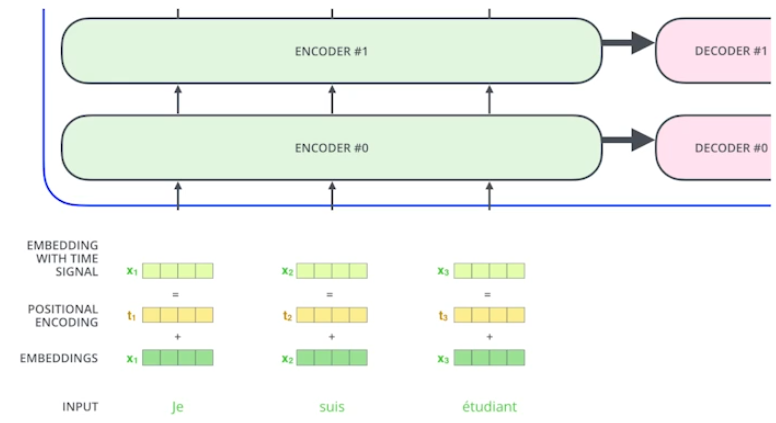
마치 bias처럼 입력에 어떤 값을 더한다.
이는 말 그대로 position에 따른 값의 변화가 필요해서 쓰였다고 한다. 가령, 문장의 순서가 뒤바뀐다고 해도 positional encoding이 없다면 이러한 변화를 알 수가 없다. 따라서 입력 순서에 따른 변화를 positional encoding을 통해 구현한다.
Encoder Overview
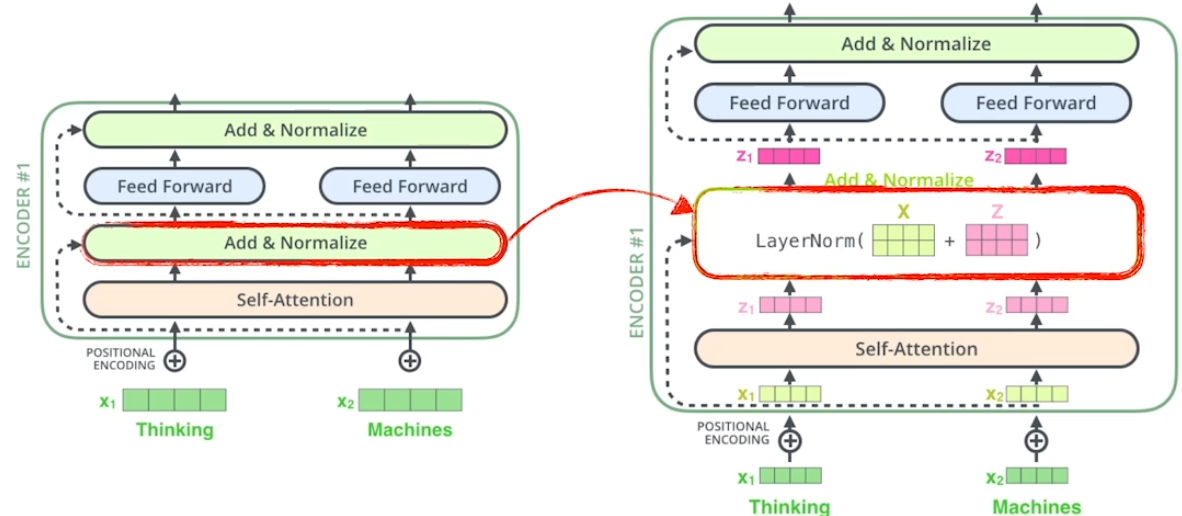
Encoder와 Decoder 사이의 정보 이동
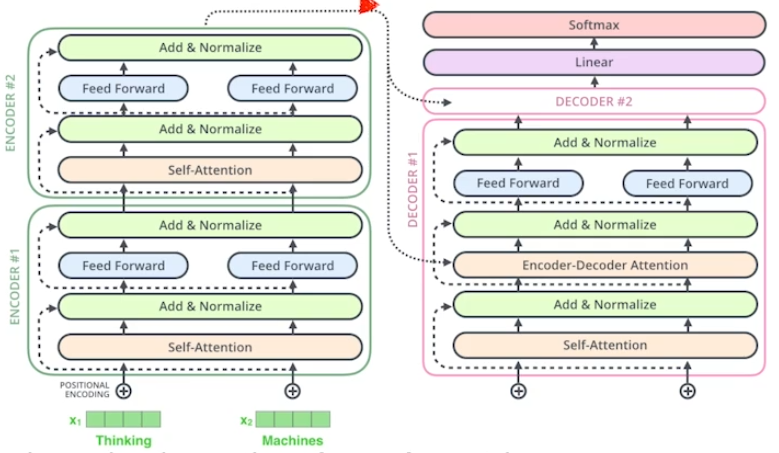
![]()
encoder 정보가 decoder로 옮겨가는 과정을 gif로 나타낸 것이다.
- encoder는 key, value를 decoder로 보낸다.
- encoder에서 query와 나머지 단어들의 key들을 inner product해서 attention을 만들고 여기에 value를 곱한다. 즉, attention map을 알고 싶으면 key와 value를 알면 된다.
- 왜냐하면 decoder의 입력으로 decoder 내에서 query를 따로 만들기 때문이다.
- encoder가 stack처럼 쌓여있으니까 상위 레이어의 단어들을 만든다고 한다. (?)
- output sentence를 자가회귀적으로 만든다.
Decoder
Self-attention
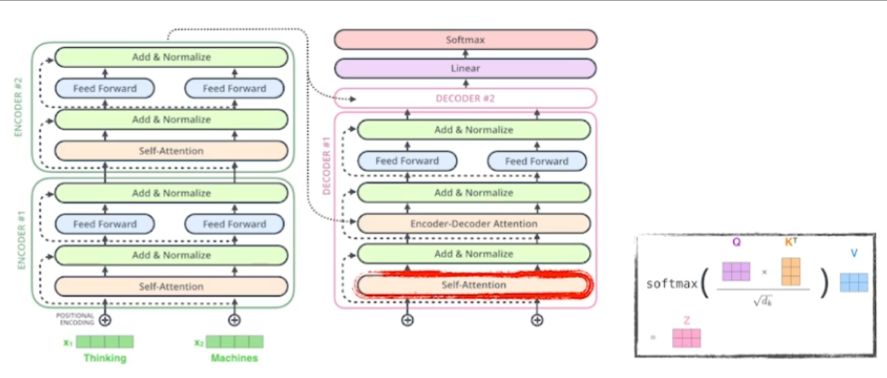
softmax step 이전에 미래 정보들에 대한 masking이 된 정보를 생성한다. 즉, 미래의 정보를 알고 decoder를 통해 학습하는 것은 의미가 없으므로 앞단의 정보에만 접근이 가능하도록 만드는 것이다.
Encoder-Decoder attention
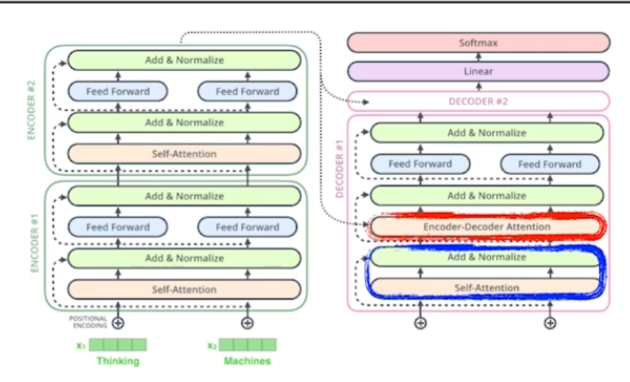
앞서 언급한 내용들이다.
"Encoder-Decoder Attention" layer는 MHA(Multi-headed self-attention)처럼 작동한다. 다만, query는 이전 layer의 출력 matrix로 만들고 key와 value는 encoder stack에서 얻는다.
Final layer
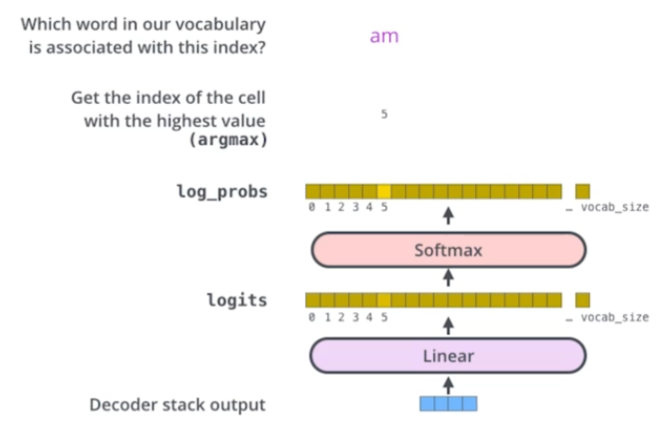
편의상 final layer로 명명.
stack of decoder의 결과물을 단어들의 분포로 만들어준다.
Vision Transformer
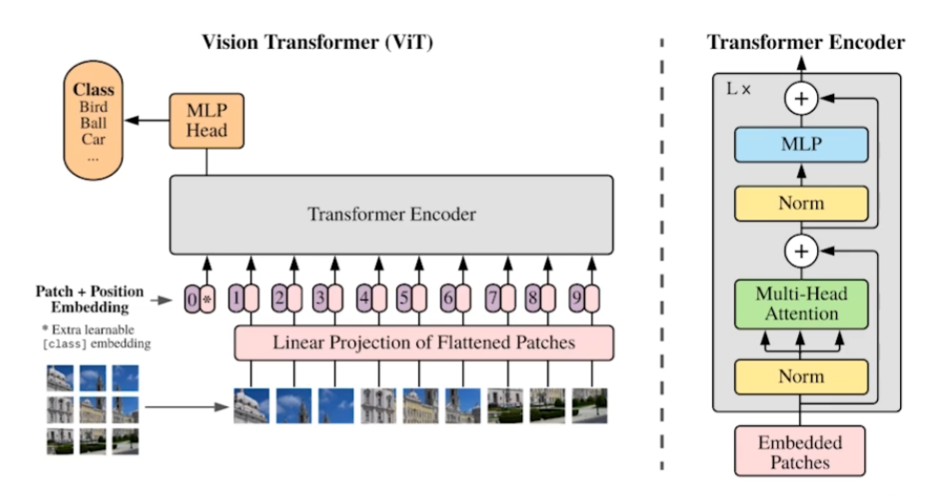
최초 transformer 논문은 기계번역을 위한거였지만, CV에서도 활용이 되기 시작했다.
이미지를 patch로 나누고 word에서 하는 것과 비슷한 embedding을 거치고 transformer를 사용한다.
DALL-E

문장을 이미지로 만드는 논문. GPT-3를 활용했다고 한다.
