
ML에 꼭 필요한 확률 그리고 통계

통계학(Statistics)
수치 데이터의 수집, 분석, 해석, 표현 등을 다루는 수학의 한 분야


모든 국민을 대상으로 분석할 수 없으니 표본을 뽑고 통계분석 실시한 후 전국민을 모 집합이라 지정하고 앞서 분석한 통계분석 결과를 바탕으로 전체 국민들에 대한 결론을 유추하는 것

전국민들도 대략 이러한 정보가 나올 것이다. 이때 무작정 결론을 짓기보단 가설검정, 수치로 되어 있는 특징들을 계산, 또 각 데이터 간의 상관관계를 분석하는 등의 과정이 진행됨

통계모델

통계모델은 수학적 모델이라고도 하며, 변수들로 이뤄진 수학식이 있을 때, 이러한 수학식을 계산해 실제 값을 추정하는 방법이다.

이렇게 그어진 선을 수학적 모델,
이 선은 이와 같은 함수 형태로 나타낼 수 있고,
동시에 이러한 선을 통계 모델이라 하기도 합니다.

이러한 선은 여러 가정을 가지고 있는데 이 가정들은 확률분포를 따른다.
확률분포는 가운데가 볼록한 대칭형 종모양 그래프를 생각하면 된다.
이러한 분포를 정규분포라고 함.
영어로 직역하면 평균의 분포라고 한다.
이는 전체 데이터의 평균 즉, 가운데를 중심으로 데이터가 몰려있는 구조이며 동시에 가운데에서 멀어질수록 데이터의 빈도수가 적어지는 구조를 가지고 있다.
그리고 통계모델은 모든 변수 즉 데이터가 이러한 가정에 만족해야하는 '기본 가정'으로 시작하며,
이 조건이 만족할 때만 모델의 성능이 통계학적으로 의미를 갖게 된다.
확률분포(probability distribution)

확률 분포는 종모양의 분포 형태를 띠고 있음
모든 분포가 이렇지는 않고
대략 두 번째 분포도 있다고 가정해보자
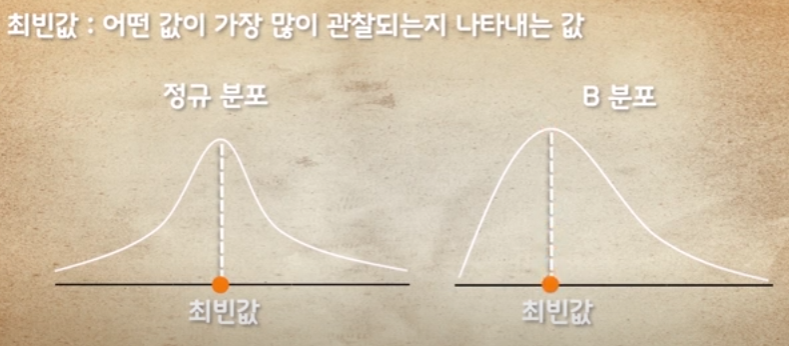
- 최빈값 : 분포상 가장 많은 빈도수를 가진 값
정규분포에는 중앙이 되고, B분포는 점선이 최빈값 됨

-
중앙값 : 중앙값은 데이터 값의 크기를 기준으로 정렬했을 때 가장 중앙에 위치한 값
정규분포에서는 최빈값과 같지만 B분포는 정규분포와 다름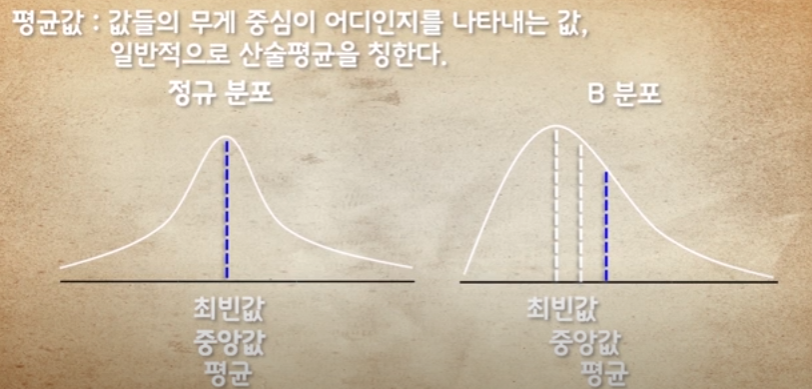
-
평균 : 모든 데이터들의 평균값
이것도 정규분포에서는 가운데 위치,
즉 정규분포는 최빈값, 중앙값, 평균이 같은 선상에 위치한다.
형태로 데이터 분포 형태 대략 유추 가능
넘파이 모듈과 사이피 패키지에 있는 스테이트 모듈 불러오기
무작위 난수를 출력하더라도 같은 무작위 값을 얻어낼 수 있다.


분포를 이룰 데이터를 만들기 위해 넘파이에 있는 random함수의 randint함수를 사용하여 0부터 100까지의 범위 안에서 10000개의 데이터를 무작위로 추출하라라고 작성하고 data_A라고 저장하기

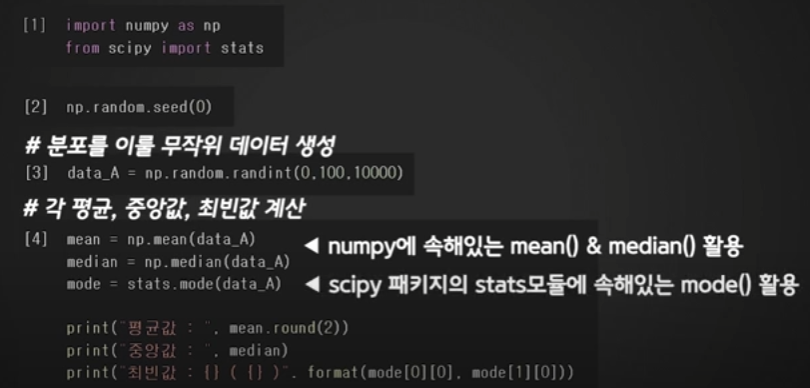

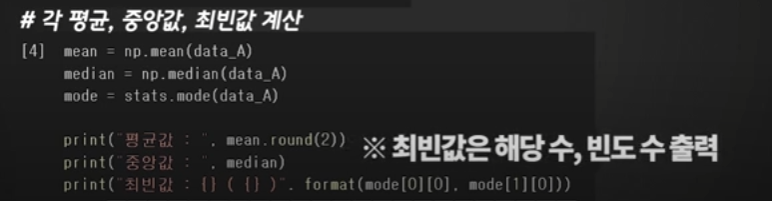
최빈값은 평균, 중앙값과 다르게 계산
어떠한 숫자가 몇 개를 가지고 있느냐, 즉 2개의 값을 출력해야 한다.

여기 mode 객체에 2개의 형식으로 저장되어 있는다는 건데
이는 파이썬 출력 기법중 format 기법을 사용해서,

모드 객체 안에 첫번째 타입과 두 번째 타입에 있는 객체를 꺼내
여기에 순서대로 출력해라 ~ 라는 코드를 사용해 최빈값을 구하는 코드를 작성해주기

그럼 0부터 100범위 안에 10000개의 값을 가진 분포에 대한 평균, 중앙, 최빈값은 이러한 값을 가지고 있음을 알 수 있고 이건 정규분포와는 조금 거리가 있다.
정규분포는 어떻게 만들까?
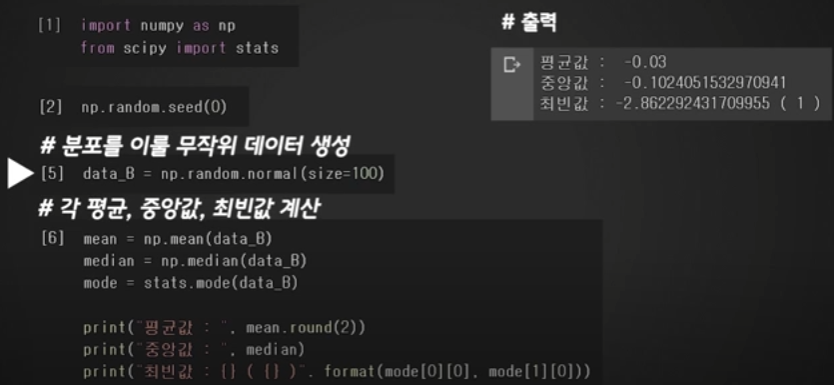
코드에서 normal 함수를 사용하고 size라는 변수에 '몇개의 데이터를 넣어줄 것이냐'만 설정해주시고 객체 이름만 바꿔준 다음, 나머지 코드는 동일하게 사용하신다음 출력을 해보면 확실히 이전의 분포보다는 평균, 중앙, 최빈값이 거의 동일한 정규분포의 형태를 띄고 있음을 알 수 있다.
변량의 측정
(= 수치 = 변수)

산포를 측정하는 게 분산
제곱을 한 이유는 음수가 나올 수 있어서 항상 양의 값만 출력하도록 하기 위해


값 계산해보면 표준편차에 비해 분산값이 훨 큼
평균과의 차를 제곱한 값으로 분산을 구했기 때문이다.
값이 너무 커서 비교가 쉽지 않기 때문에
이런 단점을 좀 보완하고자 원래의 단위로 보정한 것이 표준편차이다.
사분위수


사분위수는 총 4개의 지점으로 나눈다.
그리고 크기순으로 정렬

그 지점에 위치한 숫자들을 의미한다.



선을 벗어난 데이터는 이상치로 간주할 수 있으며 자세히 살펴볼 필요가 있다.

60분을 600분으로 표기했을 경우 일 수 있음

600분을 지우면 다시 깔끔하게 그려지는 것을 확인 가능
600은 이상치인데 이 기준은 어디에서 오는 걸까?

4분범위랑 중앙에서 50% 범위를 뽑아서 본다는 것
즉 양쪽의 25%를 자르고 가운데 50%만 보는 것
<양쪽 범위 설정해주기>


a사의 배달시간이 b사보다 더 많이 소요됨을 알 수 있음
오른쪽은 박스플롯의 장점
