우선 정렬을 공부하기에 앞서 사용해야 하는 이유에 대해 알아보자
데이터를 정렬하는 이유
우리는 탐색을 위해서 정렬한다
컴퓨터는 보통 백만 개 이상의 많은 데이터를 다룬다 이때 만약 정렬이 되어있지 않다면 순차 탐색 알고리즘을 통해서 하나씩 데이터를 찾아야 한다
데이터가 정렬되어 있다면 이진 탐색을 통해서 더욱 쉽게 데이터를 찾을 수 있다 정렬되었다는 것은 모든 임의의 데이터의 왼쪽에는 자신의 값보다 작거나 같은 값이 있고, 오른쪽에는 자신의 값보다 크거나 같은 값이 있다는 것을 의미한다
따라서 임의로 하나의 데이터를 선택했을 때 원하는 값보다 선택한 값이 더 작다면 왼쪽은 아예 볼 필요가 없게 된다 시간 복잡도를 줄일 수 있어서 정렬은 꼭 필요하다
삽입 정렬 (Insertion Sort)
이미 정렬된 배열 부분에서 요소들을 하나씩 비교하여 자신의 위치를 찾아서 삽입함으로써 정렬하는 알고리즘이다
평균 시간 복잡도는 O(n^2)
[1단계] 선택 데이터를 현재 정렬된 데이터의 범위 내에서 적절한 위치를 찾는다
[2단계] 삽입할 위치와 선택 데이터의 위치 사이에 있는 데이터를 전부 오른쪽으로 shift한다
[3단계] 삽입할 위치에 데이터를 삽입한다
[4단계] 위의 단계를 반복한다
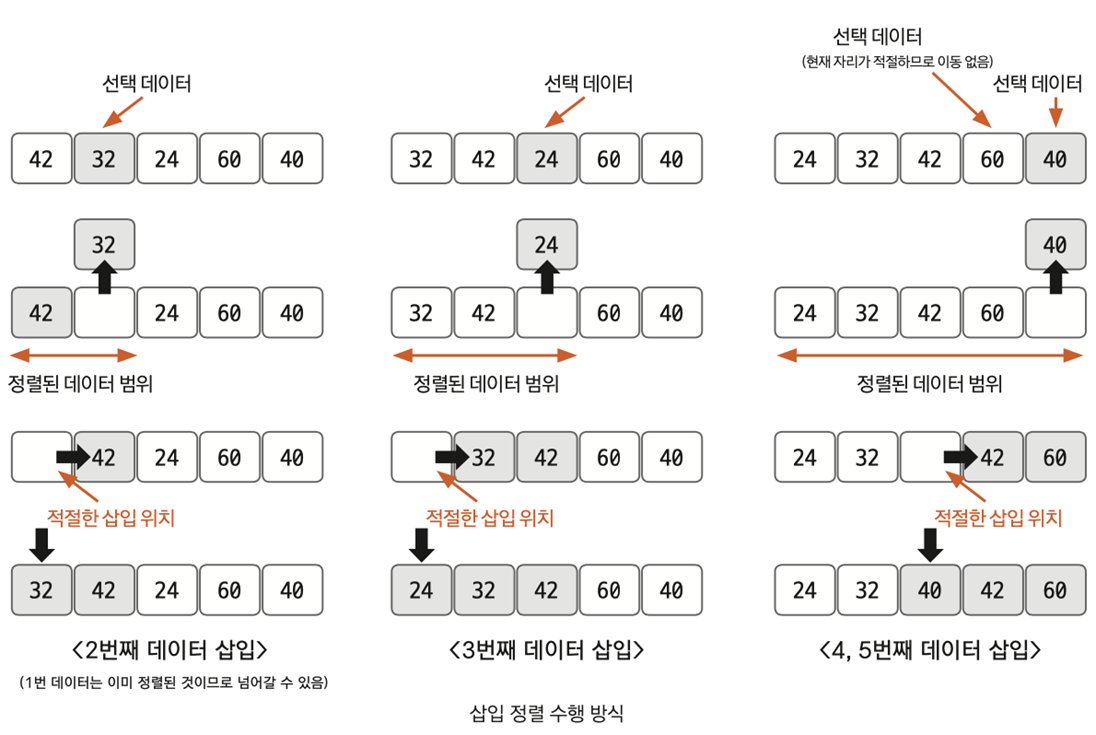
실제 예제를 통해 이해해보도록 하겠다
- 첫 번째 데이터는 정렬된 것으로 간주하고 두 번째 데이터부터 삽입을 시작한다
- 두 번째 데이터(=값이 32인 데이터)를 넣을 자리를 찾는다 앞의 정렬된 데이터인 42와 선택 데이터의 값인 32를 비교한다 모든 정렬된 데이터보다 32가 더 작기 때문에 index가 0인 자리로 이동해야 한다
- index가 0인 자리에 42가 있기 때문에 삽입하기 위해서는 42가 이동되어야 한다 오른쪽으로 shift해서 이동한다
- 42가 이동했기 때문에 index가 0인 자리는 비어있게 된다 이 자리에 32를 삽입하면 된다
- 이제 세 번째 데이터를 삽입한다 앞의 정렬된 데이터인 [32, 42]와 선택 데이터인 24의 값을 비교한다 모든 정렬된 데이터의 값보다 24가 작기 때문에 index가 0인 자리로 이동해야 한다
- 그렇다면 32와 42를 오른쪽으로 shift해서 index가 0인 자리를 빈 상태로 만든다
- 이제 index가 0인 자리에 24를 삽입한다
- 이제 네 번째 데이터를 삽입한다 앞의 정렬된 데이터인 [24, 32, 42]보다 선택 데이터인 60의 값이 더 크기 때문에 적절한 자리로 간주한다
- 이제 다섯 번째 데이터를 삽입한다 앞의 정렬된 데이터인 [24, 32, 42, 60]과 선택 데이터인 40을 비교한다 index가 큰 값부터 차례대로 비교한다 60은 40보다 크기 때문에 앞의 index에 해당하는 값과 비교한다 42도 40보다 크기 때문에 앞의 index에 해당하는 값과 비교한다 32는 40보다 작기 때문에 32의 오른쪽 자리에 삽입하면 된다 index는 (32의 index + 1)이 된다
- 42와 60을 오른쪽으로 shift하고 이제 해당하는 index에 40을 대입한다
삽입 정렬 코드
#include <iostream>
#include <vector>
using namespace std;
int main() {
int N;
cin >> N; // 정렬할 데이터의 개수
vector<int> v(N, 0);
for (int i = 0;i < N;i++)
cin >> v[i];
for (int i = 1;i < N;i++) {
int index = i;
int value = v[i];
for (int j = i - 1;j >= 0;j--) { // index가 0인 값은 정렬된 것으로 간주하므로 1부터 정렬
if (v[j] < v[i]) { // 선택 데이터보다 더 작은 데이터를 찾으면
index = j + 1; // 해당 데이터의 오른쪽에 삽입하기 때문에 index값에 +1 해줘야한다
break;
}
if (j == 0) // 선택 데이터의 값이 가장 작은 경우
value = 0;
}
for (int j = i;j > index;j--)
v[j] = v[j - 1]; // 오른쪽으로 shift
v[index] = value;
}
for (int i = 0;i < N;i++)
cout << v[i] << " ";
return 0;
}// 입력 예시
5
24 32 42 60 40
// 출력 예시
24 32 40 42 60