딥러닝의 과정
데이터 준비 → 딥러닝 네트워크 설계 → 학습 → 테스트(평가)
tf.keras : 텐서플로우(TensorFlow)의 표준 API
아래 코드는 숫자 손글씨 데이터베이스인 MNIST 데이터셋을 읽어서 분류하는 코드이다.
데이터 준비
데이터 불러오기(mnist)
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
mnist = keras.datasets.mnist
# MNIST 데이터를 로드. 다운로드하지 않았다면 다운로드까지 자동으로 진행된다.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(len(x_train)) # x_train 배열의 크기를 출력
# 60000데이터 로드 테스트
잘 로드되었는지 이미지 테스트
X항목에 들어있는 이미지에 대응하는 실제 숫자 값이 담겨 있는 것을 확인할 수 있다.
plt.imshow(x_train[1],cmap=plt.cm.binary)
plt.show()
print(y_train[1])
# 0
Matplotlib이란?
파이썬에서 제공하는 시각화(Visualization)패키지
차트(chart), 플롯(plot) 등 다양한 형태로 데이터를 시각화하는 기능을 제공
학습용 데이터 체크
print(x_train.shape)
# (60000, 28, 28) - 28x28 크기의 숫자 이미지가 60,000장이 있다는 뜻
print(x_test.shape)
# (10000, 28, 28)데이터 전처리
print('최소값:',np.min(x_train), ' 최대값:',np.max(x_train))
# 최소값: 0 최대값: 255인공지능 모델을 훈련시키고 사용할 때, 일반적으로 입력은 0~1 사이의 값으로 정규화 시켜주는 것이 좋다. MNIST 데이터는 각 픽셀의 값이 0~255 사이 범위에 있으므로 데이터들을 255.0 으로 나누어주면 최소값이 0, 최대값이 1에 근접하게 된다.
x_train_norm, x_test_norm = x_train / 255.0, x_test / 255.0
print('최소값:',np.min(x_train_norm), ' 최대값:',np.max(x_train_norm))
# 최소값: 0.0 최대값: 1.0왜 0-1사이로 해야하는가? 왜 정규화를 시켜주어야 하는가?
딥러닝 네트워크 설계
딥러닝 레이어(layer)를 설계하는 것.
텐서플로우 케라스(tf.keras)에서 모델을 만드는 방법
- Sequential API : 매우 간단하게 딥러닝 모델을 만들어낼 수 있는 방법
- Functional API
- 직접 코딩 등
Sequential API
model=keras.models.Sequential()
model.add(keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(keras.layers.MaxPool2D(2,2))
model.add(keras.layers.Conv2D(32, (3,3), activation='relu'))
model.add(keras.layers.MaxPooling2D((2,2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(32, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
print('Model에 추가된 Layer 개수: ', len(model.layers))
# Model에 추가된 Layer 개수: 7- Conv2D
- 1번째 인자 : 이미지 특징 수(필터의 개수)
- 예시 코드에서 첫번째레이어에서는 16개, 세번째레이어에서는 32개를 고려하겠다는 뜻
- 2번째 : 필터의 크기
- padding : 경계 처리 방법
- valid : 유효한 영역만 출력(따라서 출력 이미지 사이즈는 입력사이즈보다 작다)
- same : 출력 이미지 사이즈가 입력이미지 사이즈와 동일
- input_shape : 입력이미지의 형태
- 모델에서 첫 레이어일때만 정의
- (행, 열, 채널수)
- 채널수 : 흑백일 경우 1, 컬러일 경우 3
- activation : 활성화 함수 설정
- linear : default, 입력뉴런과 가중치로 계산된 결과값이 그대로 출력으로 나온다.
- relu : rectifier함수, 은익층에 주로 쓰인다.
- sigmoid : 시그모이드함수, 이진 분류 문제에서 출력층에 주로 쓰인다.
- softmax : 소프트맥스함수, 다중 클래스 분류 문제에서 주로 쓰인다.
- 1번째 인자 : 이미지 특징 수(필터의 개수)
- Polling
- Convolution과 activation에 의해 얻어진 feature map으로부터 값을 샘플링하여 정보를 압축하는 과정
- 이미지 사이즈를 줄여주는 역할을 하기 때문에 연산 속도가 빨라진다.
- Dense
- 1번째 인자 : 분류기에 사용되는 뉴런의 숫자. 이 값이 클수록 보다 복잡한 분류기를 만들 수 있다.
- 예시 코드에서 6번째레이어에서는 32개로 먼저 32개로 분류 후 최대한 복잡하게 분류한 후 7번째 레이어에서 최종으로 10개의 숫자로 분류하는 것을 볼 수 있다.
- 만약 알파벳을 구분하고 싶다면, 대문자 26개, 소문자 26개로 총 52개의 클래스를 분류해내야 한다. 그래서 6번째레이어에서는 32보다 큰 64, 128 등을 고려해 볼 수 있을 것이다. 그리고 7번째레이어는 52가 될 것이다.
- 1번째 인자 : 분류기에 사용되는 뉴런의 숫자. 이 값이 클수록 보다 복잡한 분류기를 만들 수 있다.
딥러닝 모델 확인
model.summary()
딥러닝 네트워크 학습시키기
위에서 만든 네트워크의 입력은 (데이터갯수, 이미지 크기 x, 이미지 크기 y, 채널수) 와 같은 형태를 가진다. 그런데 print(x_train.shape)을 해보면, (60000, 28, 28)로 채널수에 대한 정보가 없다. 따라서 (60000, 28, 28, 1)로 만들어 주어야 한다. 여기서 채널수 1은 흑백 이미지를 의미한다. 컬러 이미지라면 RGB 세 가지 값이 있기 때문에 3이다.
print("Before Reshape - x_train_norm shape: {}".format(x_train_norm.shape))
print("Before Reshape - x_test_norm shape: {}".format(x_test_norm.shape))
x_train_reshaped=x_train_norm.reshape( -1, 28, 28, 1) # 데이터갯수에 -1을 쓰면 reshape시 자동계산됩니다.
x_test_reshaped=x_test_norm.reshape( -1, 28, 28, 1)
print("After Reshape - x_train_reshaped shape: {}".format(x_train_reshaped.shape))
print("After Reshape - x_test_reshaped shape: {}".format(x_test_reshaped.shape))Before Reshape - x_train_norm shape: (60000, 28, 28)
Before Reshape - x_test_norm shape: (10000, 28, 28)
After Reshape - x_train_reshaped shape: (60000, 28, 28, 1)
After Reshape - x_test_reshaped shape: (10000, 28, 28, 1)complie
모델을 학습시키기 전에 compile메소드를 통해 학습 방식에 대한 환경설정을 해야 한다.
complie메소드는 세가지의 인자를 받는다.
- optimizer : 최적화 함수 설정
- sgd
- adam
- rmsprop
- adagrad
- keras.optimizers.*** 를 사용하면 더 정교하게 설정할 수 있다.
- ex) keras.optimizers.SGD(lr=0.02, momentum=0.8, nesterov=True)
- ex) keras.optimizers.Adam(learning_rate=0.001)
- loss : 손실 함수 설정
- categorical_crossentropy
- mse
- metrics : 모델의 성능을 판정하는데 사용하는 지표 함수, 리스트 형태로 설정, 사용자 정의 함수도 들어갈 수 있다.
학습하기
아래 코드는 60,000개의 데이터를 10번 반복해서 학습하라는 뜻이다.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train_reshaped, y_train, epochs=10)Epoch 1/10
1875/1875 [==============================] - 2s 1ms/step - loss: 0.1975 - accuracy: 0.9395
Epoch 2/10
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0670 - accuracy: 0.9799
Epoch 3/10
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0489 - accuracy: 0.9844
Epoch 4/10
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0395 - accuracy: 0.9880
Epoch 5/10
1875/1875 [==============================] - 3s 1ms/step - loss: 0.0318 - accuracy: 0.9897
Epoch 6/10
1875/1875 [==============================] - 3s 1ms/step - loss: 0.0265 - accuracy: 0.9919
Epoch 7/10
1875/1875 [==============================] - 3s 1ms/step - loss: 0.0215 - accuracy: 0.9936
Epoch 8/10
1875/1875 [==============================] - 3s 1ms/step - loss: 0.0186 - accuracy: 0.9941
Epoch 9/10
1875/1875 [==============================] - 3s 1ms/step - loss: 0.0160 - accuracy: 0.9948
Epoch 10/10
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0130 - accuracy: 0.9959
<tensorflow.python.keras.callbacks.History at 0x7f10e80cfc50>epoch 별로 accuracy가 올라가는 것을 볼 수 있다.
테스트(평가)
테스트
test_loss, test_accuracy = model.evaluate(x_test_reshaped,y_test, verbose=2)
print("test_loss: {} ".format(test_loss))
print("test_accuracy: {}".format(test_accuracy))313/313 - 2s - loss: 0.0344 - accuracy: 0.9899
test_loss: 0.0344112291932106
test_accuracy: 0.9898999929428101학습했을 때 accuracy는 99.59가 나왔지만 실제로 테스트해보았을 때는 98.99가 나왔다. 테스트 손글씨에는 처음 쓰인 손글씨가 섞여있을 가능성이 있기 때문이다.
추론
model.predict()를 사용하면 model이 입력값을 보고 실제로 추론한 확률분포를 출력할 수 있다. model이란 사실 10개의 숫자 중 어느 것일지에 대한 확률값을 출력하는 함수이다. 이 함수의 출력값 즉 확률값이 가장 높은 숫자가 바로 model이 추론한 숫자가 된다.
predicted_result = model.predict(x_test_reshaped) # model이 추론한 확률값.
predicted_labels = np.argmax(predicted_result, axis=1)
idx=0 #1번째 x_test를 살펴보자.
print('model.predict() 결과 : ', predicted_result[idx])
print('model이 추론한 가장 가능성이 높은 결과 : ', predicted_labels[idx])
print('실제 데이터의 라벨 : ', y_test[idx])model.predict() 결과 : [9.8947801e-11 1.0196472e-11 4.9176936e-08 1.6367677e-07 1.9609570e-12
1.9836343e-11 1.5060793e-18 9.9999976e-01 3.0529048e-09 3.4305444e-08]
model이 추론한 가장 가능성이 높은 결과 : 7
실제 데이터의 라벨 : 77이 1.00에 근접하고 있는데 이는 모델이 7을 인식할 확률이 아주 높다는 것을 뜻한다.
실제로 확인해보면.
plt.imshow(x_test[idx],cmap=plt.cm.binary)
plt.show()
model이 추론해 낸 숫자와 실제 라벨의 값이 다른 경우
import random
wrong_predict_list=[]
for i, _ in enumerate(predicted_labels):
# i번째 test_labels과 y_test이 다른 경우만 모아 봅시다.
if predicted_labels[i] != y_test[i]:
wrong_predict_list.append(i)
# wrong_predict_list 에서 랜덤하게 2개만 뽑아봅시다.
samples = random.choices(population=wrong_predict_list, k=2)
for n in samples:
print("예측확률분포: " + str(predicted_result[n]))
print("라벨: " + str(y_test[n]) + ", 예측결과: " + str(predicted_labels[n]))
plt.imshow(x_test[n], cmap=plt.cm.binary)
plt.show()
개선 - 하이퍼파라미터 변경
Conv2D 레이어에서 입력 이미지의 특징 수를 늘리거나 줄여 보거나, Dense 레이어에서 뉴런수를 바꾸어 보거나, 학습 반복 횟수인 epoch 값을 변경해 볼 수 있다.
# 바꿔 볼 수 있는 하이퍼파라미터들
n_channel_1=16
n_channel_2=32
n_dense=25
n_train_epoch=10
model=keras.models.Sequential()
model.add(keras.layers.Conv2D(n_channel_1, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(keras.layers.MaxPool2D(2,2))
model.add(keras.layers.Conv2D(n_channel_2, (3,3), activation='relu'))
model.add(keras.layers.MaxPooling2D((2,2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(n_dense, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델 훈련
model.fit(x_train_reshaped, y_train, epochs=n_train_epoch)
# 모델 시험
test_loss, test_accuracy = model.evaluate(x_test_reshaped, y_test, verbose=2)
print("test_loss: {} ".format(test_loss))
print("test_accuracy: {}".format(test_accuracy))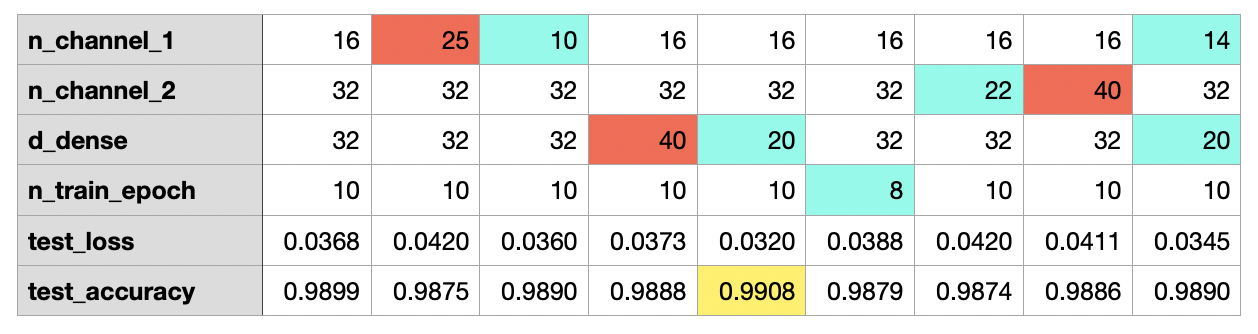
테스트 해보았더니, 나머지 값은 그대로 두고, d_dense = 20 으로 변경했을 때 가장 높은 99.08이 나왔다.
