
Pandas🤔?

- 파이썬 라이브러리
- 구조화된 데이터를 효과적으로 처리하고 저장
- 특히 행과 열을 가진 2차원 데이터와 대용량 데이터 처리에 대해 효율적
- 엑셀과 비슷한 데이터 형태
- Array 계산에 특화된 Numpy를 기반으로 설계
- Pandas의 자료형: Series data, Data frame
Series 데이터
- Numpy의 array가 보강된 형태
- Data와 Index를 가지고 있음
- 특수한 dictionary라고 생각하면 쉽다!
import pandas as pd # pandas도 numpy처럼 import해야 사용 가능.
data = pd.Series([1, 2, 3, 4])
print(data)위 코드의 데이터는 아래와 같은 index(연보라색)와 data(민트색) 두개의 정보를 모두 가진다.
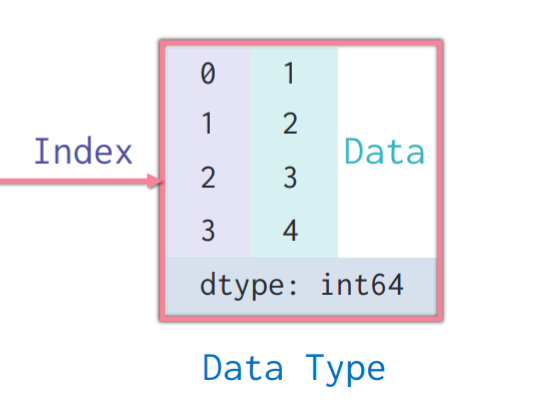
Series의 특징
- 값(value)을 ndarray 형태로 가지고 있음.
import pandas as pd
data = pd.Series([1, 2, 3, 4])
print(data)
# 0 1
# 1 2
# 2 3
# 3 4 | 왼쪽은 index, 오른쪽은 data
# dtype : int 64
print(type(data))
# <class 'pandas.core.series.Series'> | -> "시리즈" 임을 체크!
print(data.values)
# [1 2 3 4]
print(type(data.values))
# <class 'numpy.ndarray'> | -> 값은 배열!- dtype 인자로 데이터 타입을 지정할 수 있음.
data = pd.Series([1, 2, 3, 4], dtype = "float") | [1, 2, 3, 4]는 값(value)
print(data.dtype) # float64
- 인덱스를 지정할 수 있고 인덱스로 접근 가능
data = pd.Series([1, 2, 3, 4], index = ['a', 'b', 'c', 'd'])
data['c'] = 5 # 인덱스로 접근하여 요소 변경 가능
- Dictionary를 활용하여 Series 생성 가능
population_dict = {
'china': 141500,
'japan': 12718,
'korea': 5180,
'usa': 32676
}
population = pd.Series(population_dict) # 나라 이름은 index로, 인구수는 데이터(value)로 들어감.
[실습 1] Series 데이터
문제
- 딕셔너리를 이용하여 국가별 인구 수 데이터를 시리즈로 만들어 country라는 변수에 저장해주세요.
- 그 다음 country 변수를 출력해주세요.
korea : 5180
japan : 12718
china : 141500
usa : 32676
code
import numpy as np
import pandas as pd
# 예시) 시리즈 데이터를 만드는 방법.
series = pd.Series([1,2,3,4], index = ['a', 'b', 'c', 'd'], name="Title")
print(series, "\n")
# 국가별 인구 수 시리즈 데이터를 딕셔너리를 사용하여 만들어보세요.
# 코드 1
country_dict = {
"korea" : 5180,
"japan" : 12718,
"china" : 141500,
"usa" : 32676
}
country = pd.Series(country_dict)
print(country)실행 결과
a 1
b 2
c 3
d 4
Name: Title, dtype: int64
korea 5180
japan 12718
china 141500
usa 32676
dtype: int64

개발자로 시작| 공부한 것을 기록합니다.