Noisy Network
개요
강화학습에서의 Agent는 현재상태에서 reward를 많이 받는 action을 선택하기 위해 exploition을 하지만, 다른 더 좋은
reward를 얻기 위해서는 적절하게 exploration이 필요하다.
exploition: state 에서 지금까지 경험한 action들 중 탐색하는것 <- 기존의 경험 중 보상을 극대화
exploration: 경험한 action이 아닌, 다른 action을 탐색하는것 <- 현재 찾지 못한 보상을 탐색
기존의 Exploration
기존 강화학습에서는 exploration을 하는 방법으로는 agent가 action을 선택할 때, policy를 기반으로 선택하거나
entropy reqularisation을 사용하였다.
문제
기존의 Exploration 방법은 복잡한 state와 action에 대해서 Deep Leaerning을 이용한 Neural network 같은
function approximator에서는 적용이 어려운 부분이 있었다.
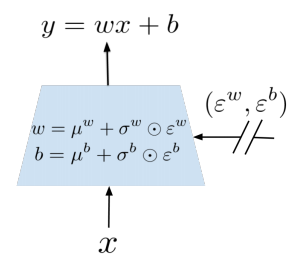
Noisy Network로 극복
기존에 Nueral Network에 Noisy를 추가한것을 Noisy Net으로 부른다. 주요한 부분으로는 Neural Network의
Weight에 Noise를 추가하므로써 Exploration을 한다. 이때 Perturbation(미묘한 변화)은 noisy distribution에서
sample 되어진다.
