
Abstract
denoising 방법과 causal language model task를 혼합해서 학습한 다국어 seq2seq 모델로 여러 태스크에서 decoder-only 모델보다 few-shot에서 좋은 성능을 얻었다. 모델의 이름은 Alexa Teacher Model로 AlexaTM 20B로 사용한다. AlexaTM 20B는 PaLM 540B보다 1-shot summarization에서 좋은 성능을 얻었고, superGLUE, SQuADv2에서 GPT3보다 8배 작은 사이즈이면서도 좋은 성능을 얻었다.
Introduction
- 1 Trillion token에 대해학습. 기존 GPT3의 경우 300B 토큰을 사용해 3배 이상 많은 토큰을 사용.
- seq2seq, 20B사이즈에서 최초의 다국어모델
- AlexaTM의 contribution
- denoising, clm을 결합해서 학습한 라지스케일 다국어 seq2seq 모델.
- 더 큰사이즈의 decoder-only 모델 보다 in-context learning에서 좋은 성능을 보임.
- GPT3보다 8배 작은사이즈인 seq2seq 모델로 SuperGLUE와 SQuAD에서 좋은 성능을 보임.
Model Architecture
AlexaTM 20에서 사용하는 Transformer model architecture

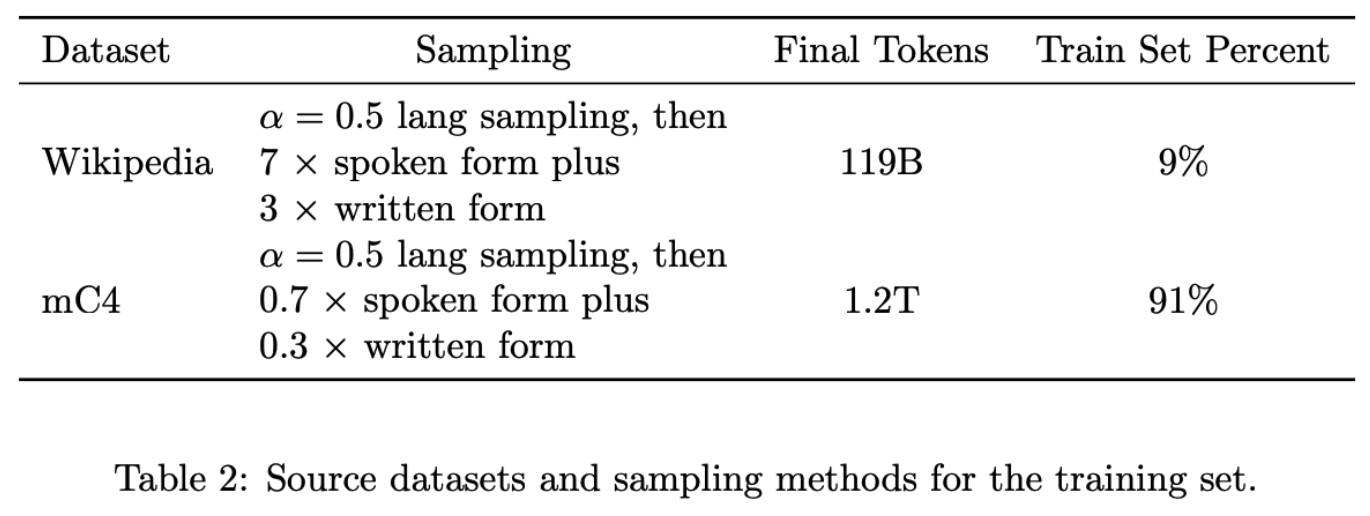
Datasets
12개의 언어로 이루어진 데이터를 사용했으며 1024 subword 단위로 데이터를 패킹하여 사용했다. 관련이 없는 문서에 대해서도 패킹을 했으며, 관련이 없는 문서의 경우 [DOC] 으로 구분했다. 패킹을 사용하는 이유로는 상대적으로 일정한 길이의 데이터를 사용해서 컴퓨팅 효율적이게 된다.
Subword Tokenizer
150K unigram sentencepiece 토크나이저를 사용. 다운스트림태스크에서 사용할 1k의 토큰들을 지정했다.
Training Setup
베이스모델
AlexaTM 20B 모델을 허깅페이스 transformers에서 제공하는 generate함수의 이점을 이용하기 위해 허깅페이스 BART모델을 사용했다. denoisiong objective로는 BART와 동일하게 poison 분포를 따라서 평균 3길이를 가지는 span을 15% 마스킹하도록 하고 그것을 복원하도록 했다.
차별점으로는 denoising시에 Mask 토큰을 삽입하지 않았다. 그 이유로는 pretraining, fine-tuning, inference 시에 일관성을 가지기 위함이며, decoder에게 pre-training하는 동안 더 활동적인 역할을 부여하기 위함이다.
이전에 AlexaTM에서 학습한 10B encoder 모델을 활용하기위해 AlexaTM 20B에서 사용한 encoder는 이전 논문에서 사용한 AlexaTM 10B encoder로 초기화 해서 학습했다.
그리고 encoder의 임베딩으로 decoder의 임베딩과 lm-head의 임베딩을 초기화 했다. pre-training 시에 100k step 동안은 encoder를 frozen 하고, 그 후에는 unfrozen 해서 사용했다.
GPU 및 학습시간
AlexaTM 20B 모델은 500k step을 사용하는데 A100 GPU를 128 장 사용하여 120일 동안 학습했다. 배치사이즈는 최종 1 trillion token을 학습하기 위해 2M token을 batch로 사용했다(512로 나누면 대략 4K).
Optimizer
옵티마이저로는 Adam을 사용했으며, lr=1e-4 에서 lr=5e-6까지 linear decay로 학습했다. weight decay의 경우 biases와 layernorm을 제외하고 0.1을 사용. 그리고 모델 학습시 안정성을 위해 BF16을 사용해 학습했다.
ZeRO
Deepspeed ZeRO stage3를 사용해서 모델웨이트, 옵티마이저스테이트, 그레이언트들을 모든 GPU워커들에 대해서 분할해서 학습했고, 내부에서 사용하는 Deepspeed를 사용해 학습했다.
Evaluation
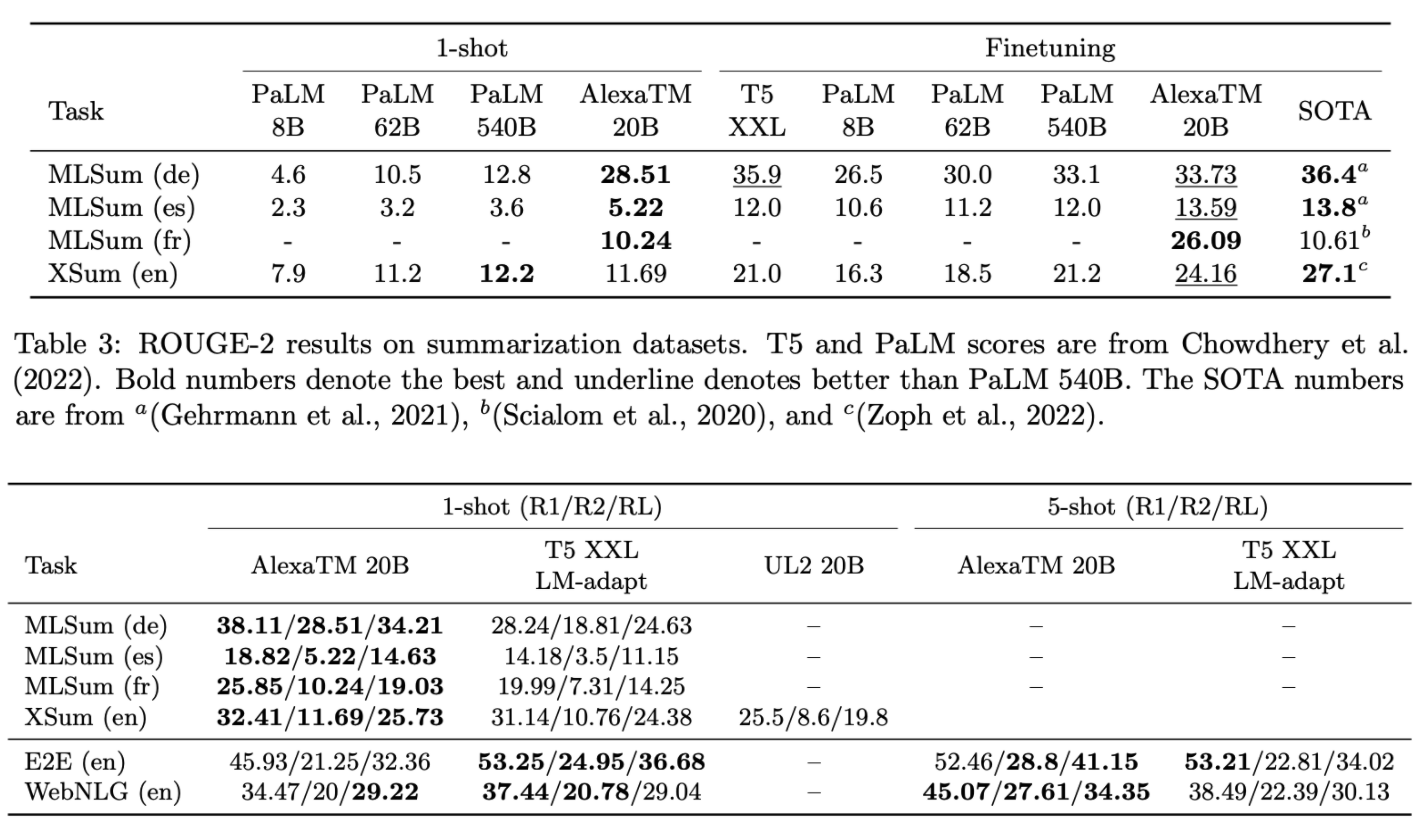
Multilingual Natural Language Generation
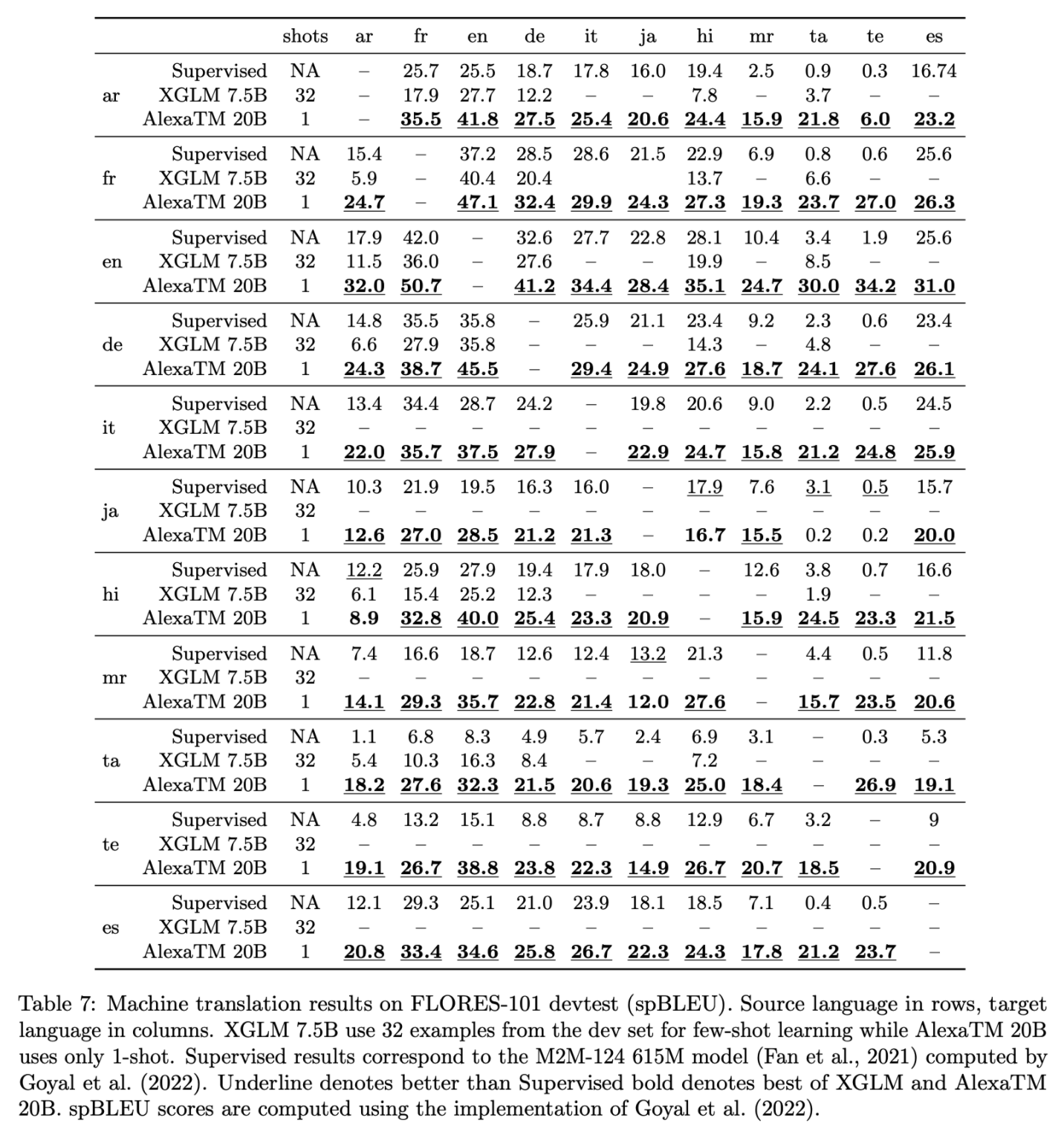
Machine Translation
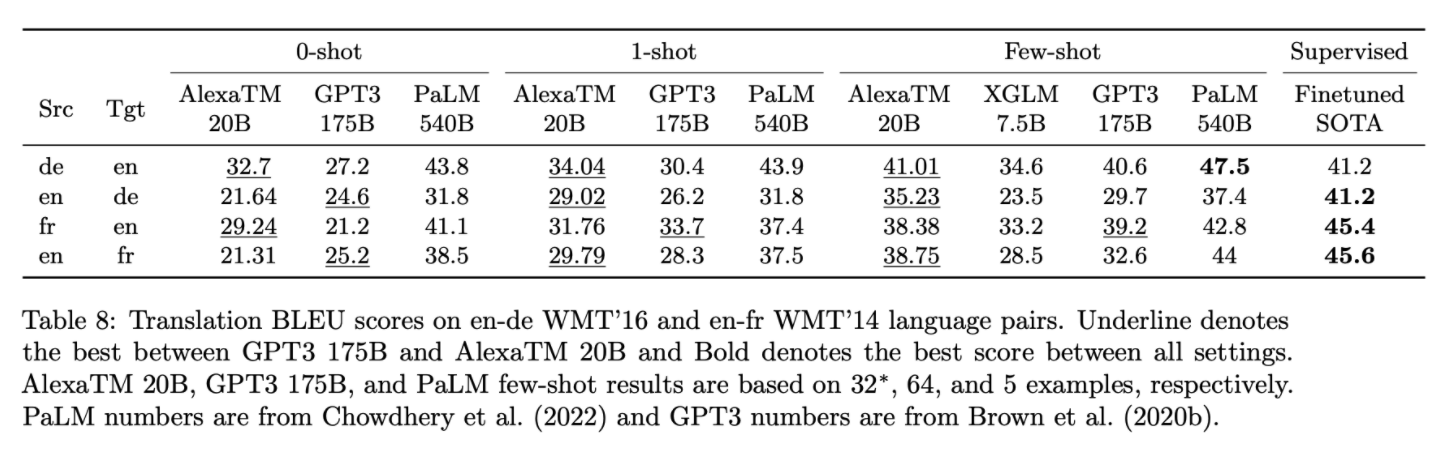
English NLP Task
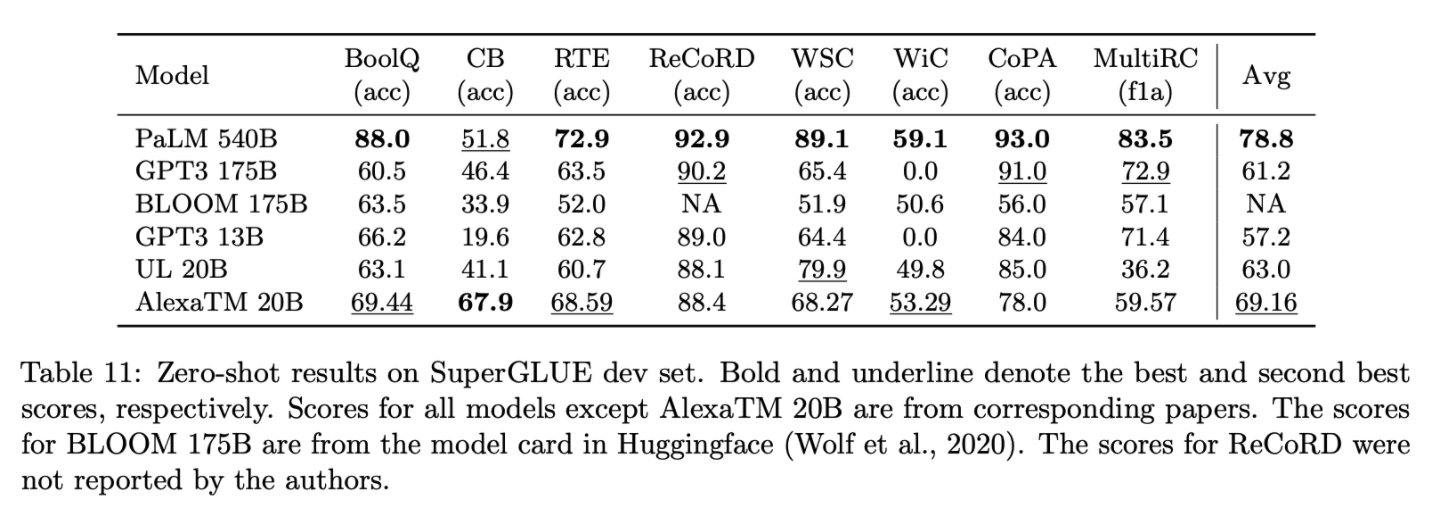

PaLM은 깡패인듯..
