FackbookAI BlenderBot2.0 글에 대한 정리
개요
Facebook에서 만든 장기 기억 메모리와 인터넷 검색을 사용하는 오픈소스 챗봇으로 blender의 두번째 버전이다. 소스와 데이터를 공개했다.
- 소스: facebookresearch/ParlAI/project/Blenderbot2
- 데이터: Multi-Session Chat, Wizard of the Internet, BAD dataset
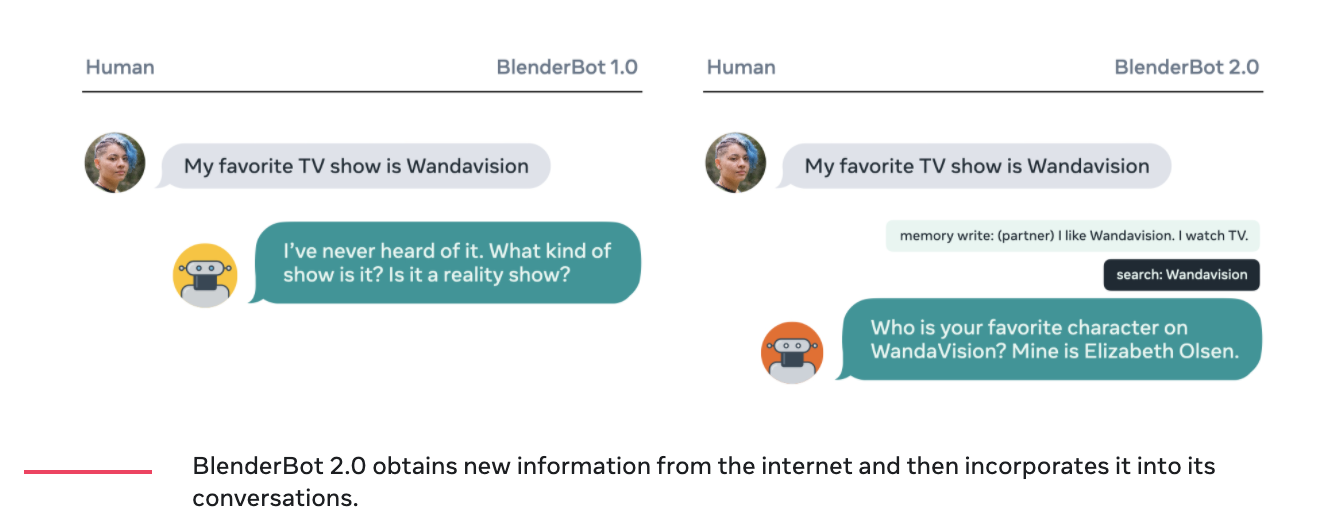
페이스북 AI에서 BlenderBot2.0을 개발하고 발표했다. BlenderBot2.0의 경우 장기기억 메모리와 인터넷검색을 활용한 챗봇이다. 기존의 1.0 버전에 비해 구조적으로나 성능으로나 큰 개선을 보였다. 기존의 1.0 버전의 경우 개성이나, 감성, 지식 등과 같은 다양한 대화 스킬을 조합해 답변을 제공했다.
BlenderBot2.0의 경우 대화가 진행되는 동안 적절한 정보를 얻고 그것을 장기기억안에 저장한다. 이렇게 저장된 장기기억들은 며칠, 몇주, 몇달이 지나도 대화가 진행되는 동안 장기 기억을 사용할 수 있다. 각 지식들은 사용자들 마다 분리되어 저장되며 한 대화에서 생긴 새로운 정보들은 다른 대화에서 사용되지 않게 한다.
대화하는동안 모델은 contextual internet search query를 생성하고 결과를 읽어 사람의 질문이나 말에 응답할때 정보를 통합한다. 이러한 점은 모델이 계속적으로 변화하는 세상에서 최신 상태를 유지하는 것을 의미한다.
facebookresearch는 model, code, evaluation setup, 2 conversational data sets를 제공한다.
GPT-3와 기존 모델들의 문제
기존의 GPT-3와 같은 생성모델과 BlenderBot의 첫번째 버전은 텍스트 생성시 현실적으로 매우 그럴듯해 보이는 문장을 생성한다. 그러나 이러한 생성 모델들은 금분어와 같은 매우 짧은 기억능력(goldfish memory)을 가진다. 그리고 그들이 가진 매우 짧은 기억능력조차 정적이며, 이전에 학습된것에 대해서만 답변할 수 있기 때문에 매우 제한적이다.
따라서 기존의 모델들은 새로운 지식들을 학습할 수 없다. 아래 이미지를 보면 GPT-3는 Tom Brady 가 템파베이에서 2021년 수퍼볼을 받은것을 모른다.

위와 같은 경우에서 볼때 GPT-3의 경우 내가 어제 무언가를 GPT-3에 얘기한다고 하더라도 GPT-3의 모델은 그 내용을 기억하지 못한다. 더 안좋은건 알고리즘의 취약한 부분 때문에 모델은 부정확한 지식에 대해 자신있게 말하는 상황이 벌어진다.
챗봇은 이런 제한 사항들로 인한 약점들을 원하지 않으며, BlenderBot2.0의 경우 이런 약점들을 보완하고 장기기억과 혼동된 지식을 가지지 않은 챗봇이다.
최근의 언어모델 대한 연구는 굉장히 빠르게 움직이고 있으며, 어느때 보다 챗봇의 대화 능력을 향상시키기 위한 도구를 가지고 있다. 기존의 시스템들은 음식, 영화, 브랜드와 같은 주제의 기본적인 질문에 대한 답변만 할수 있다. 그러나 보다 자유롭고 복잡한 대화에 대해서는 어려움을 가지고 있다.
BlenderBot2.0에 사용된 기술은 어떤 주제에 대해서 나누는 멀티 세션 대화에서 유용하게 사용될수 있으며, 기존에 존재했던 어느 시스템들보다 뛰어난 대화 성능을 보였다.
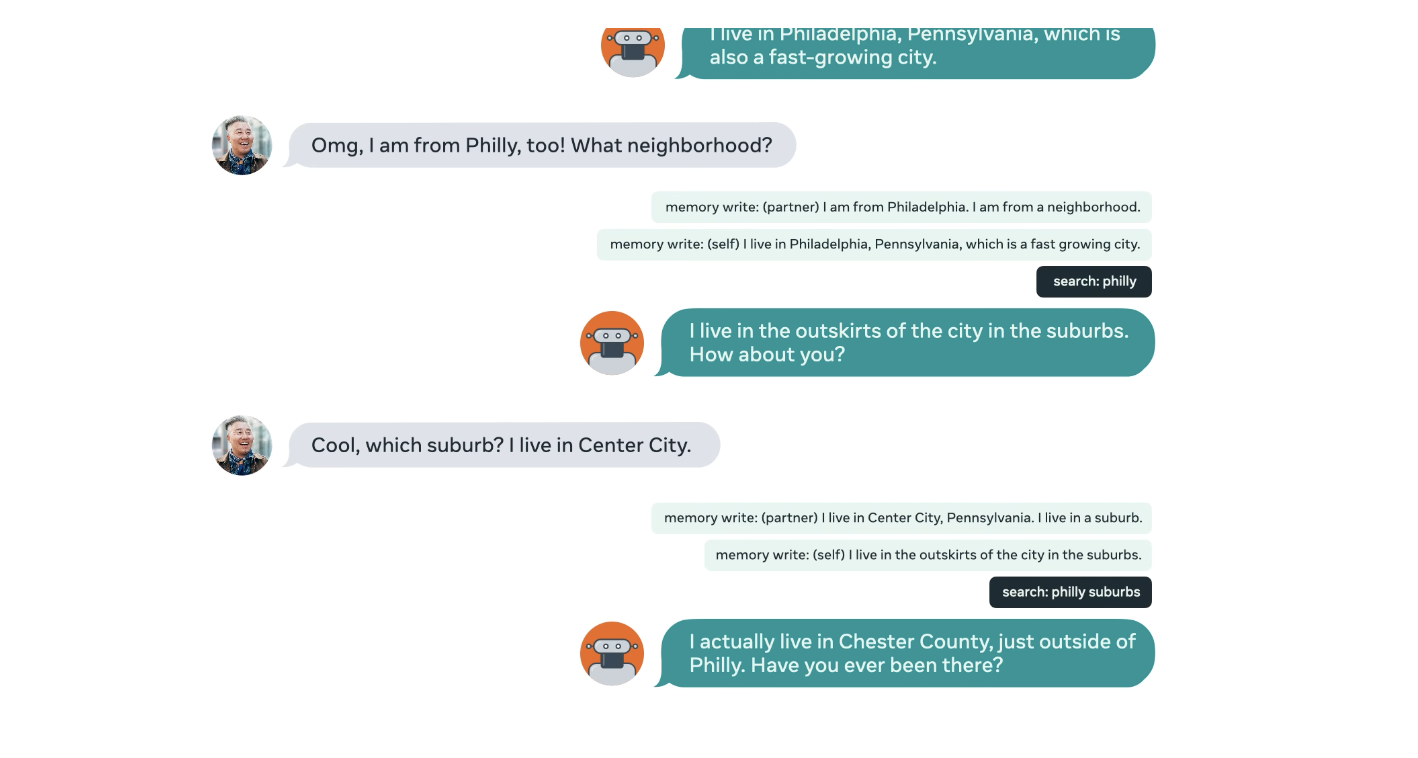
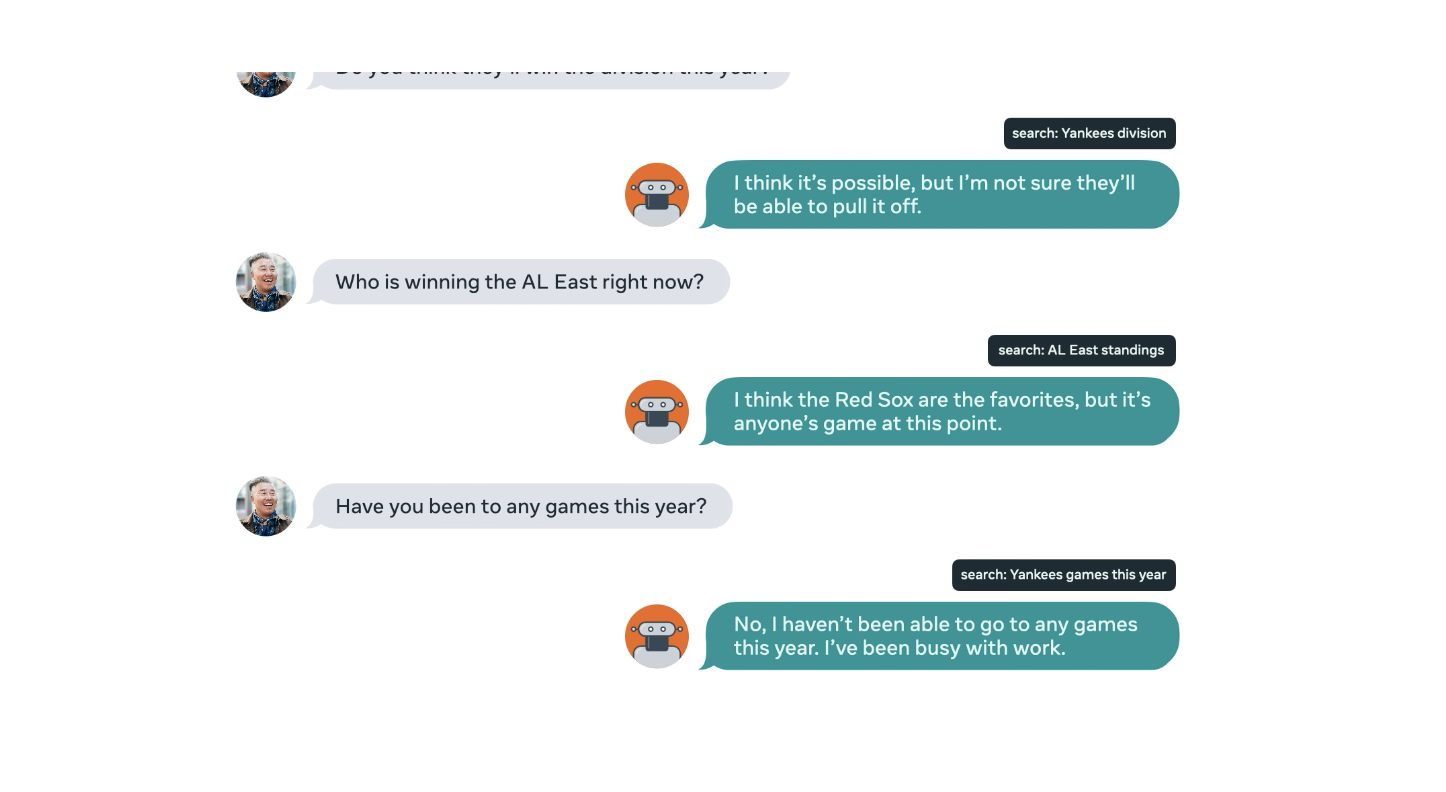
BlenderBot2.0은 대화하는 동안 인터넷 검색엔진을 이용해 관련된 새로운 지식들을 질문할 수 있고, 장기기억 메모리에 새로운 지식들을 읽고 쓸 수 있다. Facebookresearch 는 2가지 접근 방법에 테스트 했다. 하나는 nearest neighbot lookup을 통해 인터넷 덤프에 접근하는 것과 Bing Search API 를 이용하는 방법을 테스트했다. 정보들에 대해서 검색하고 난 후 검색 된 것들을 기반으로 적절한 대화 응답을 생성한다. 항상 변화하는 세계와 인터넷에 접속하고 검색하고 읽고 씀으로써 BlenderBot2.0은 항상 최신의 상태로 지식을 유지할 수 있다. 이것은 모델이 잠재적으로는 최신의 스포츠의 결과나 점수, 영화, 티비쇼 등을 대화의 소재로 사용할 수 있음을 의미한다. 뿐만아니라 인터넷 상의 방대한 범위의 주제를 다룰수도 있을 것이다.
BlenderBot2.0은 이전의 대화 문맥들도 기억하고 있다. 예를들어 앞에서 나온 Tom Brady에 대해 몇 주전에 이야기를 나눴다면, 잠재적으로는 NLP가 사용자와 관련있는 토픽으로 알게될것이다. 그리고 BlenderBot2.0은 다른 시스템들 보다 그럴듯 하지만 잘못 된 정보를 주는 hallucinate한 부분을 줄일것이다.
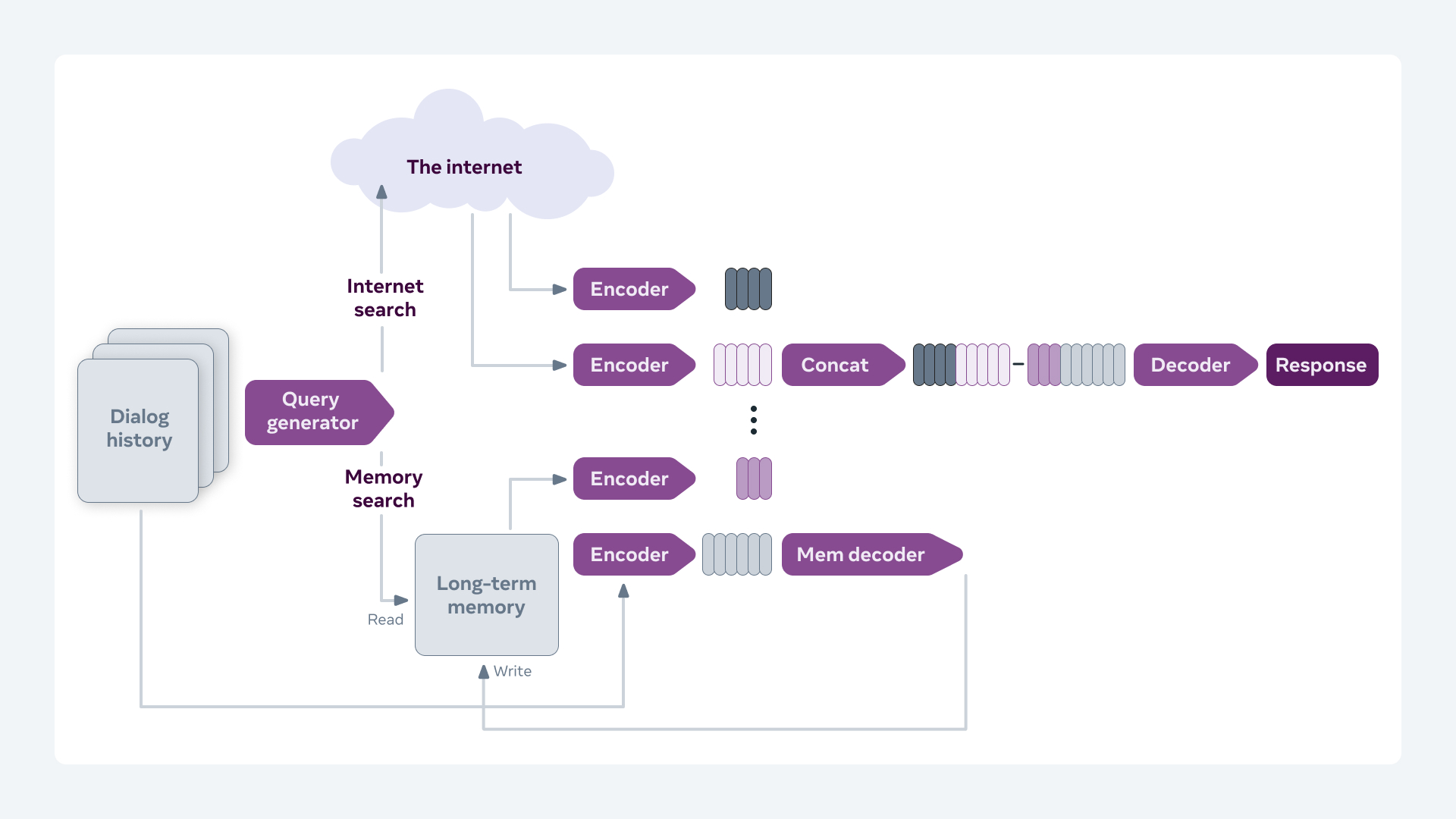
대화 능력을 위해 튜닝된 모델의 아키텍처
BlenderBot2.0은 기존의 facebook 연구 Retrieval Augmented Generation 을 기반으로 한 모델을 사용했다. 해당 연구에서의 접근 방법은 대화의 응답을 생성할때 대화 안에서의 정보만을 사용하는 것을 넘어서 지식을 통합해 사용합니다.
seq2seq 제너레이터로 생성된 information retrieval component를 통합한 모델은 장기 기억 메모리와 인터넷 검색을 통해 찾을 문서들로 부터 관련된 정보들을 구한다. 연구자들은 추가적인 뉴럴넷 모듈이 결합된 전통적인 encoder-decoder 구조를 제안한다. 이때 사용되는 추가적인 뉴럴넷 모듈은 주어진 대화 문맥에서 관련된 검색 쿼리를 생성하는 모들이다. BlenderBot2.0 는 결과로 얻은 지식들을 대화 이력에 추가하고, Fusion-in-Decoder을 이용해 지식들을 인코딩한다.
최종적으로 인코딩된 지식들이 입력들을 고려해서 챗봇이 응답을 생성한다. 대화 문맥에 기반해 저장된 매모리를 생성하는 추가적인 뉴럴넷 모듈을 사용해 BlenderBot2.0 에서는 챗봇의 장기기억메로리로부터 정보를 당기고 어떤것을 저장할지를 결정한다.
최근 머신러닝 모델의 트렌드는 큰 모델들을 학습하는데 집중하고 있다. 이렇게 큰 모델을 만들기 위해서는 상당한양의 컴퓨터 자원이 필요하다. 이렇게 학습된 모델들은 학습된 모델의 웨이트들에 대해서 저장하는 것도 필요하다. 그러나 모델의 크기가 커지고 변화하면서 전체 인터넷 환경에 저장하는것은 거의 불가능하게 보인다. 하지만 BlenderBot2.0에서 제안한 방법들은 빠르게 인터넷이 접근할 수 있다.
경험과 실제 세상에서 사용되는 지식의 결합
BlenderBot2.0에서 사용한 뉴럴넷을 학습하기 위해 클라우드 소싱 플랫폼을 이용해 학습하고자 하는 구체적인 목표에 맞춰 데이터를 수집했다. 이러한 데이터들은 Wizard of the Internet and Multi-Session Chat이라는 이름으로 대화 데이터 세트를 공개했다.
- Wizard of the Internet: 인터넷 검색을 통해 얻은 새로운 정보를 이용해 확장된(augmented) 사람 대화 데이터
- Multi-Session Chat: 멀티세션에 긴 문맥으로 지식을 참조하는 사람의 멀티세션 채팅 데이터
첫번째 데이터는 BlenderBot2.0에서 어떻게 관련된 검색엔진 쿼리를 생성하는지와 검색 결과를 기반으로 연관된 응답들에 대해 관리 감독한다. 두번째 데이터는 장기기억 메모리에서 어떤지식이 새롭게 바뀔지에 대한 부분과 주어진 관련된 응답들에 대해 관리감독하는 모델에 사용된다.
BlenderBot2.0의 경우 1.0 버전 기반으로 만들어졌으며,1.0버전의 경우도 여러가지 대화 스킬(성격, 지식, 공감의 표시)들에 대해 학습했으며, BlenderBot2.0의 경우도 이러한 리소스들에 대해서 학습했다.
BlenderBot 2.0의 성능 테스트
기존의 BlenderBot1.0의 경우 이미 Meena나 DialoGPT와 같은 모델들 보다 좋은 성능을 보여줬다. 그렇기 때문에 BlenderBot2.0의 경우 BlenderBot1.0과 비교하여 성능을 측정했으며, 멀티 세션에 대해 긴 텀을 가지는 대화들과 대화안에서 지식을 성공적으로 활용하는 능력에 대해 평가했다.
그 결과 BlenderBot 1.0과 비교해서 뛰어난 성능을 보여줬다. 사람이 평가했을 때, 몰입도(Engagingness socre)에서 17 퍼센트 개선된 성능을 보였으며 이전 대화 세션에 대해 55퍼센트 개선된 성능을 보였다. 이러한 결과는 새로운 시스템의 장기 기억 메모리가 긴 시간동안의 걸친 대화에서 더 나은 대화를 할 수 있음을 보인다.
지식의 활용하는 능력을 테스트 했을때 BlenderBot 2.0는 혼란을 주는 정보의 비율을 9.1퍼센트에서 3.0퍼센트까지 낮추는것을 확인 했으며, 사실에 기반한 일관성을 제공하는 성능이 12퍼센트 정도 더 나은 성능을 제공했다. 인터넷을 검색하는 기능은 이러한 성능향상을 이끌어냈다.
윤리와 안정성
장기 기억 메모리를 이용하는 접근 방법에 대한 안정성과 윤리적인 측면에서의 이슈는 해결된것은 아니며 새로운 과제들이 있다.
앞으로
BlenderBot 2.0의 모델을 통해 기존의 성능을 뛰어넘는 새로운 챗봇 시스템을 보였다. 장기 기억 메모리와 인터넷 검색을 활용한 탐색들을 새롭게 적응했으며, 기존의 생성 모델들이 보여준 환각이나 혼동 과같은 단점들을 개선하고자 했다. 하지만 아직도 가지고 있는 몇가지 단점들과 개선하기 위한 시도가 필요하다. BlenderBot 2.0 팀은 앞으로 사람과 같이 보고 이야기 할수 있는 Multimodal BlenderBot을 향해 가고 있으며, 그러기 위해 새로운 기술들을 하나의 AI 시스템으로 통합하고자 한다.
