DeepSpeed Pipeline Parallelism
딥스피드에서 사용하는 Pipeline Parallelism에 대해 정리
딥스피드 v0.3에서부터 pipeline paraelleism을 지원한다. Pipeline Parallelism은 모델의 레이어를 분할하여 딥러닝 학습에서 메모리와 컴퓨팅 효율성을 높인다. 딥스피드 트레이닝 엔진은 pipeline parallelism과 데이터를 함께 제공하며 Megatron-LM과 같이 모델 Parallelism을 결합할 수 있다. 딥스피드팀은 최근 3D 병렬화를 통해 trillion 파라미터를 학습할 수 있음을 보였다.
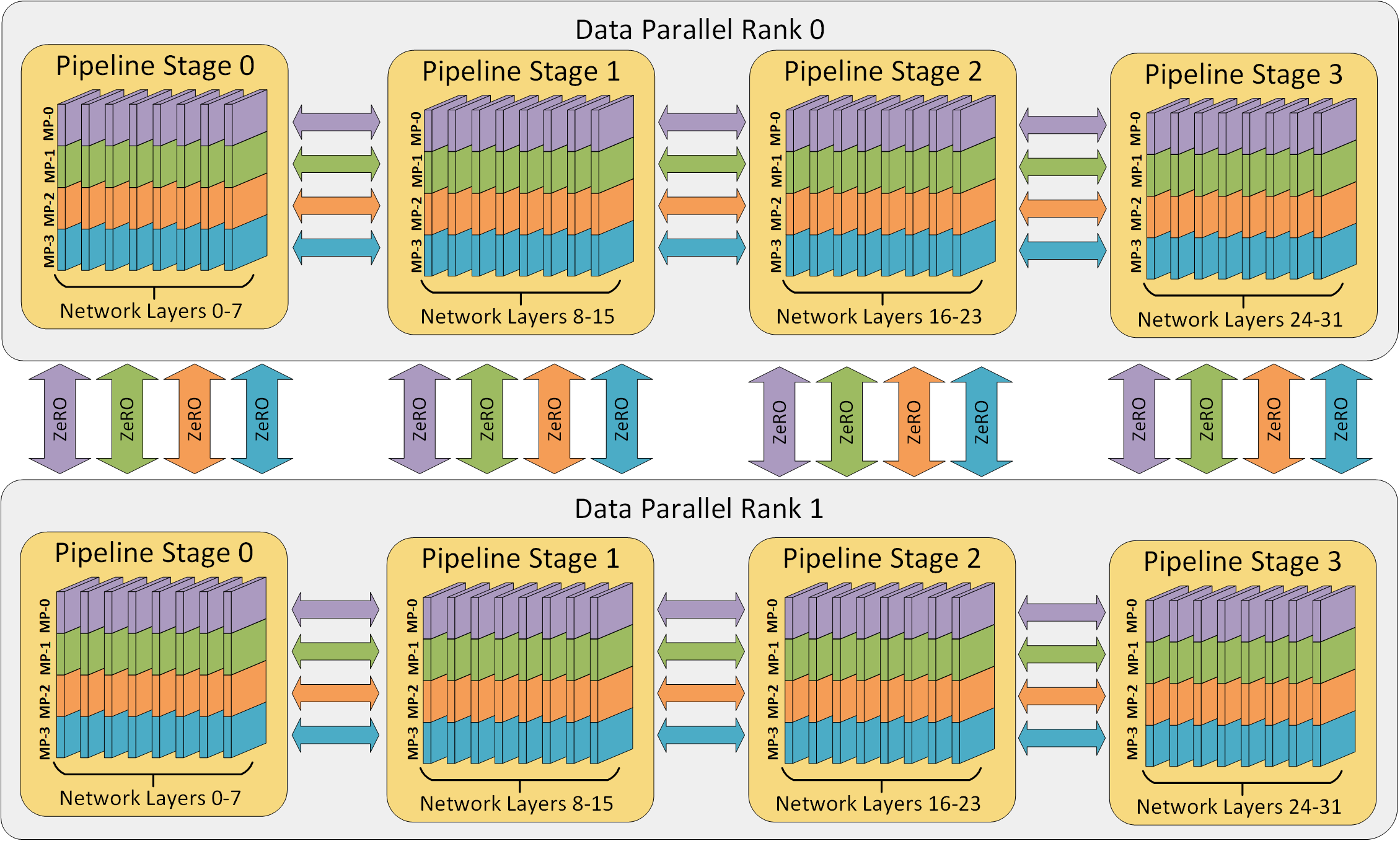
딥스피드는 gradient accumulation을 pipeline parallelism을 추출하기 위해 사용한다. 학습에 사용되는 배치(batch)는 마이크로 배치(micro-batch)로 나누어 지며 이 마이크로 배치들은 pipeline stage에 따라 병렬로 처리된다. 마이크로 배치에 대해 forward pass가 stage에서 완료되면 activation memory는 파이프라인 안에서 다음 stage와 통신한다. 다음 stage에서 micro-batch에 대해 backward pass가 완료되면, activation에 대한 gradient는 파이프라인을 따라 뒤로 통신한다. 각 backward pass는 gradient를 지역적으로 축적하고, 그 다음 모든 데이터 병렬 그룹은 gradient를 병렬로 reduction을 수행한다. 마지막으로 optimizer가 모델의 웨이트들을 업데이트 한다.
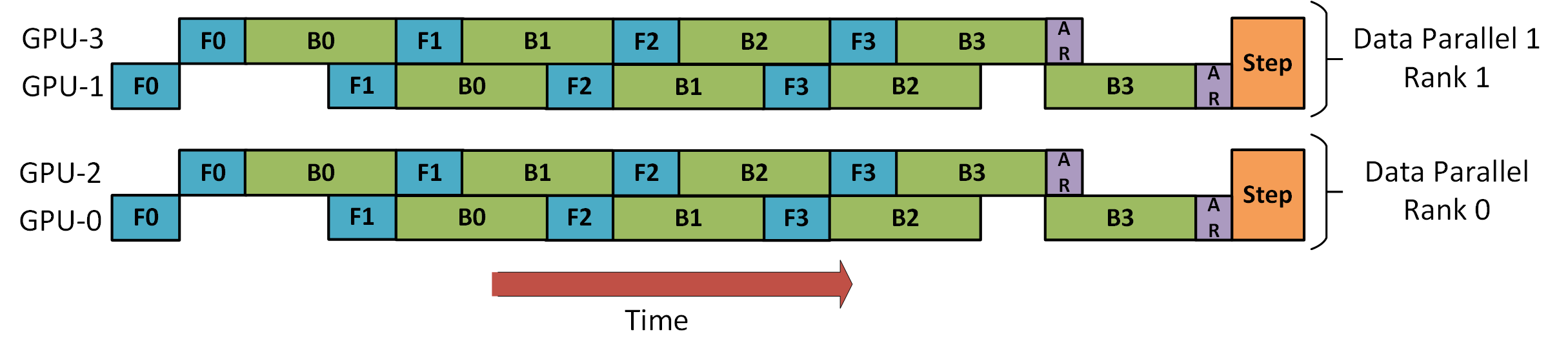
위 그림에서 딥스피드가 배치를 8개의 마이크로 배치로 2-way data parallelism과 2-stage pipeline parallelism을 이용해 학습하는 것을 보인다. GPU0과 2는 pipeline으로 병렬화 되며, forward F와 backward는 B가 번갈아서 진행되며 gradient가 data 데이터 병렬화 되었던 GPU1,3의 값들과 함께 all-reduceAR 된다.
Pipeline Prallelism 시작하기
딥스피드는 pipeline parallel 학습 프로세스를 단순화 하고 빠르게 하는것을 추구한다. 아래의 내용에서 AlexNet 모델을 통해 딥스피드에서 하이브리드 데이터와 pipeline parallel학습에 대해 다룬다.
Expressing Pipeline Models
Pipeline parallelism을 위해서는 layer들의 Sequence로 표현되어야 한다. forward pass에서 각 레이어는 이전 레이어의 output을 입력으로 사용해야 하며, pipeline parallel을 위해서 아래와 같은 폼을 따라야한다.
Basic
def forward(self, inputs):
x = inputs
for layer in self.layers:
x = layer(x)
return xpipeline parallel model을 위해 torch.nn.Sequential은 편리한 컨테이너로 딥스피드에서 수정없이 병렬화를 사용할수 있다.
net = nn.Sequential(
nn.Linear(in_features, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, out_features)
)
from deepspeed.pipe import PipelineModule
net = PipelineModule(layers=net, num_stages=2)PipelineModule모듈은 layers 인자를 통해 모델을 구성하는 레이어의 시퀀스로 사용하며, 초기화 이후에 net는 두 pipeline stage로 나누어져 그에 대응하는 GPU로 옮겨진다. 2개의 GPU보다 더 많은 GPU가 있는 경우 딥스피드는 하이브리드 데이터 병렬화를 사용한다.
GPU의 전체 수는 파이프라인 스테이지의 수로 나눌수 있어야 한다. (전체 GPU 수/ 파이프라인 스테이즈 수)
메모리 효율을 위한 모델 개발: Memory-Efficient Model Construction 참고
