GPT-3의 모델
접근 방법
GPT-3의 접근 방법은 기존의 GPT-2와 모델, 학습데이터, 학습 방법 등에서 유사하다. GPT2에서 추가로 확장하여, 모델의 사이즈와 데이터의 사이즈를 확대했으며, 데이터의 다양성을 증가했고, 학습 길이도 증가시켰다.
in-context learning 또한 이전의 GPT-2와 유사하게 진행되었고, 학습에서 다양한 세팅을 체계적으로 찾는 실험을 하였다. 제로샷, 퓨샷, 원샷 학습을 진행하면서 각 nlp 태스크들이 얼마나 데이터에 의존적인지도 알수 있다.
Setting
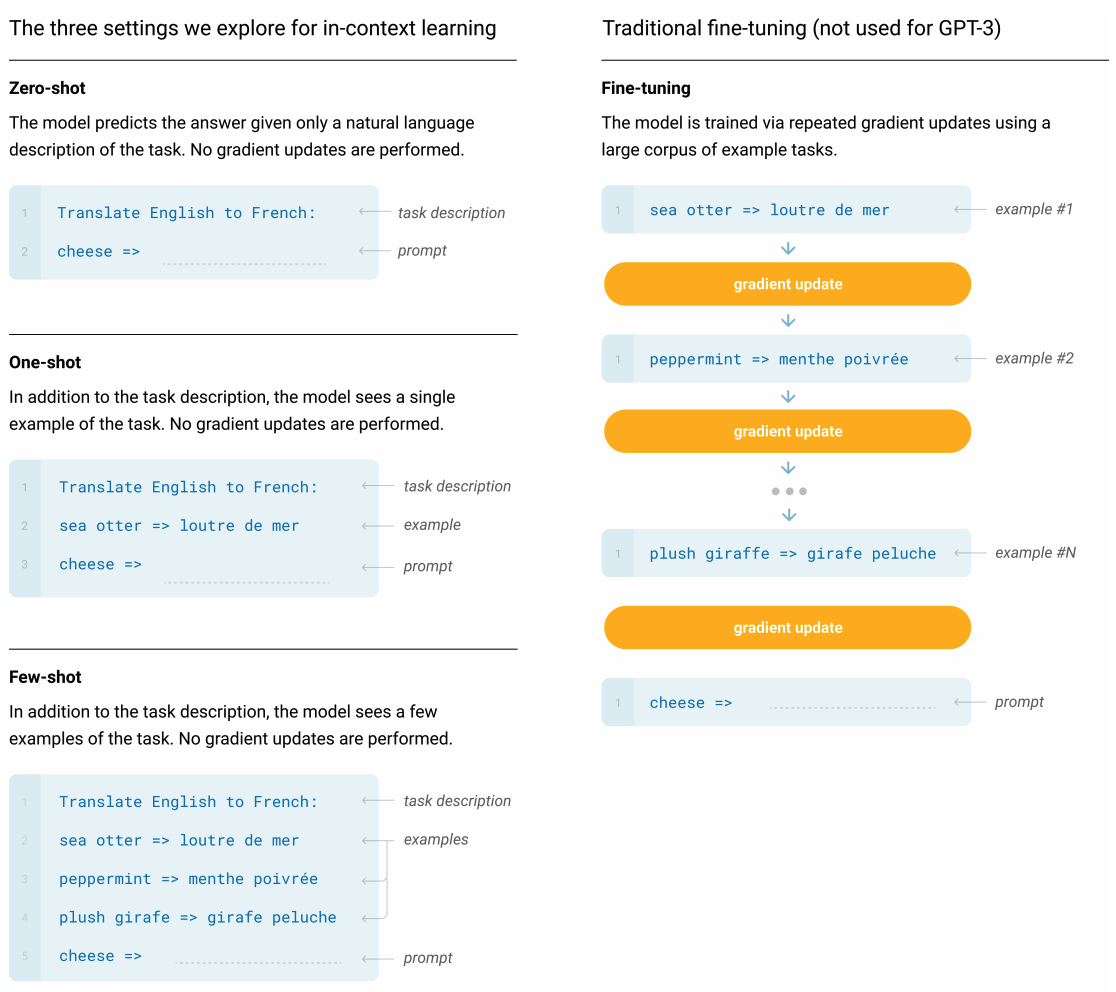
GPT-3에서는 궁극적으로 원샷 또는 제로샷 방법이 사람이 자연어를 사용하는 방식과 유사하다고 생각하며, 이런 방법이 가장 공정한 비교로 생각한다. 따라서 제로샷 원샷 방법이 앞으로의 작업에 주요 목표가 된다.
Model & Architectures
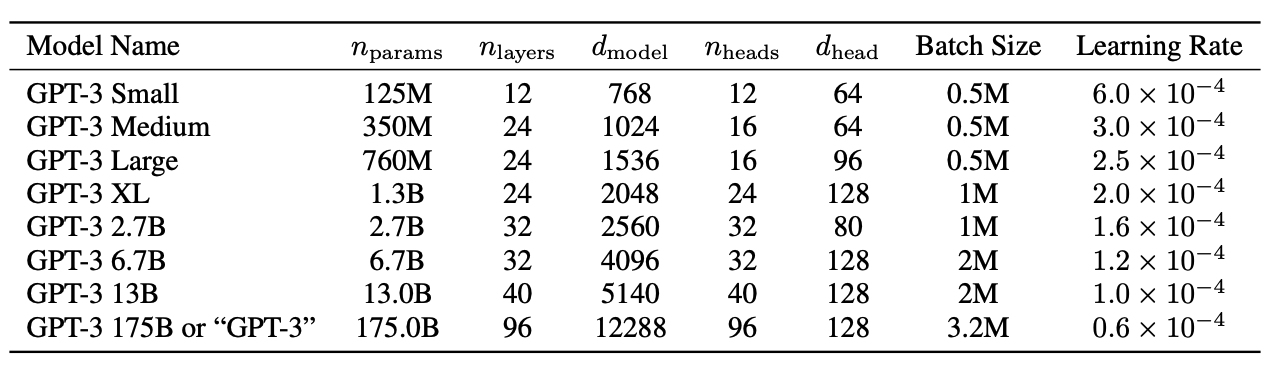 위 모델들은 학습 시 사용되는 하이퍼파라미터를 나타내며, 모든 모델은 300 Billion 토큰을 학습하는데 사용했다.
위 모델들은 학습 시 사용되는 하이퍼파라미터를 나타내며, 모든 모델은 300 Billion 토큰을 학습하는데 사용했다.
- : 학습 가능한 파라미터의 총 수
- : 전체 레이어 수
- : bottleneck layer의 유닛수
(GPT-3에서는 언제나 bottleneck layer의 4배 크기의 레이어를 사용한다. = )
- 모든 모델은 =2048의 context window를 사용
- 각 노드간의 데이터 이동을 최소화하기 위해 width와 depth의 dimension에 따라 간에 모델을 나눈다.
- : 학습 가능한 파라미터의 총 수
모델
GPT-3에서는 GPT-2와 같은 모델과 구조를 사용했고, 수정된 initialization, pre-normalization, reversible tokenization들을 사용했다. 다만 Transformer레이어에서 와 유사한 alternating dense와 locally banded sparse attention을 사용했다. 그리고 8가지 크기의 모델사이즈에 대해 실험하였다. 이때 모델의 사이즈는 125M에서 175B까지 범위로 실험하였다.
Training Dataset
언어 모델의 데이터셋은 빠르게 확장 되고 있다. Common Crawl 데이터셋을 통해 약 1조 단어의 데이터가 축적 되었다. 1조 단어의 데이터 셋은 GPT-3의 큰 모델의 학습시키는데에 충분했다. 이 데이터셋은 동일한 시퀀스를 2번 업데이트 하지 않고도, 가장 큰 모델을 교육하기에 충분했다.
하지만 Common Crawl데이터는 필터링 되지 않거나, 가볍게 필터링 되었기 때문에 정제된 데이터들 보다 낮은 퀄리티를 보였고, 그래서 3단계를 거쳐서 데이터 셋의 평균 퀄리티를 높이고자 했다.
데이터셋 퀄리티를 높이기 위한 방법
1,2번의 Common Crawl에 대한 자세한 내용은 부록에 있다. 3번의 항목에 대해서는 고퀄리티 데이터를 추가하기 위해 여러가지 선별된 데이터셋을 추가했으며, 의 확장된 버전, 오랜기간 동안 스크래핑한 데이터, 인터넷 기반의 책(Book1, Book2), 영어 Wikipedia 들을 데이터로 사용했다.
1. 고품질의 참조 말뭉치 범위와 유사한 Common Crawl를 다운드하고 정제했다.
2. Document Level에서 `fuzzy deduplication`을 수행함으로써 중복을 방지하고, 오버피팅의 정확한 측정으로써 validation set의 무결성을 보존한다.
3. 유명한 고퀄리티 말뭉치들을 추가하여 다양성을 높인다.CommonCrawl의 경우 2016~2019년 기간의 데이터를 사용했으며 전처리 되기 전에는 45TB의 텍스트로 구성되어 있었고 전처리 후에는 570GB의 용량을 가진다.
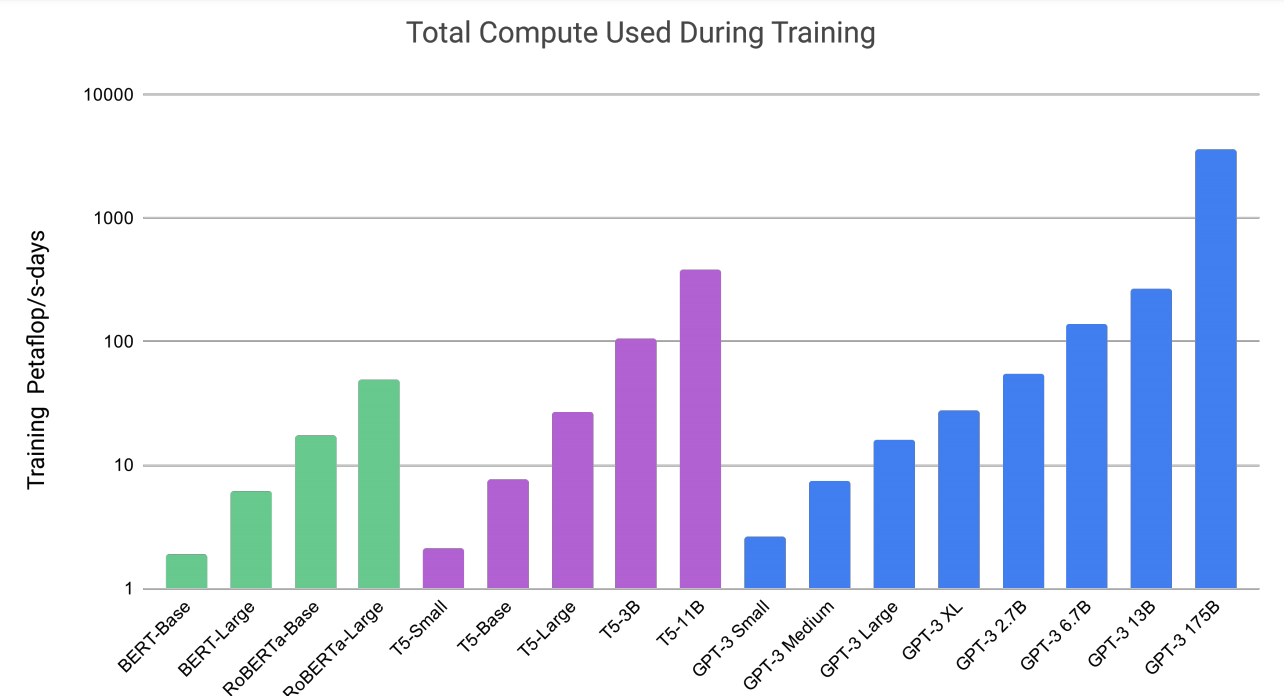
모델 별 학습하는데 사용되는 컴퓨팅
학습 과정에서 데이터 관련 잠재적 이슈 부분
사전학습 중에 테스트 데이터와 개발 데이터에 중복이 있을수 있다. 이런 데이터 중복에서 잠재적인 오염이 있을 수 있다. GPT-3 저자들은 개발 및 테스트 데이터에서 중복을 찾아 제거하기 위해 노력했다.
