
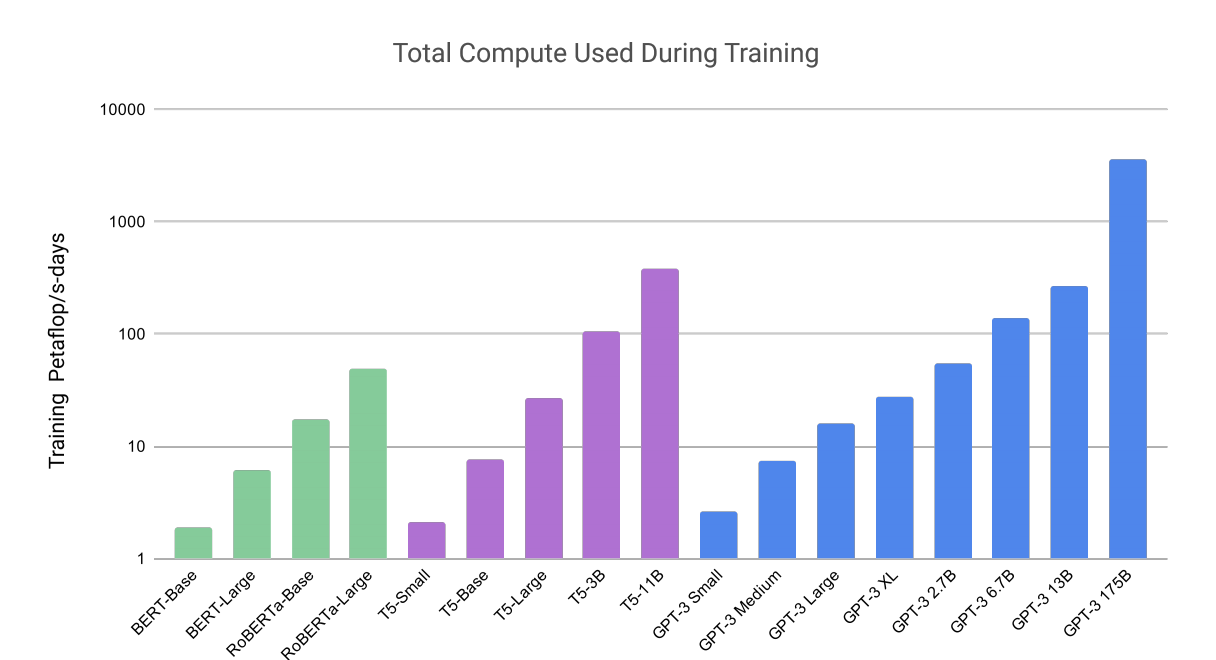
갈수록 커지는 모델의 크기;;;
들어가기 전에..
최근 거대한 크기의 GPT3 모델이 발표 되었다. 개인으로써 가지고 있는 GPU 성능이 부족하기 때문에 항상 좀더 적은 크기의 언어 모델로 학습을 할 수 있을까에 대한 고민이 있었다. 이러한 방향은 갈수록 커지는 모델들과의 괴리가 있었고, 이러한 부분을 GPT-3를 살펴보는 과정을 통해 어떠한 이유에서 갈수록 모델이 커지게 되는지 살펴본다.
72페이지에 이르는 논문을 바탕으로 천천히 살펴보면서 정리해나간다.
개요
최근에는 대규모의 텍스트를 가지고 사전학습 후 파인튜닝을 거치면서 여러 NLP 과제들에 대해서 좋은 성능을 얻었다. 하지만 인간의 경우를 생각해보면 적은 수의 예를 가지고 여러가지 과제들을 처리할 수 있는데, NLP 시스템은 여전히 많은 라벨링된 데이터를 필요로 한다. 이러한 부분은 최신 NLP 시스템과 사람의 차이는 여전히 나타낸다.
따라서 GPT-3의 경우 이전의 non-sparse언어 모델보다 10배 큰 파라미터인 1750억개의 파라미터를 가진 모델을 사전학습 후 파인 튜닝 없이 auto-regressive 방식으로 학습 한 후에 그래디언트 업데이트나 파인튜닝 없이, few-shot 학습 방법을 통해 여러가지 NLP 태스크에 대해 강력한 성능을 얻었다. 몇가지 부분에 대해서 GPT-3의 few-shot 학습이 좋은 성능을 발휘하지 못하는 부분도 있지만, 기사 작성에 대해서 인간 평가자들이 인간 기자와 GPT3의 차이를 발견하기 어려워 했다.
few-shot 학습 방법이란
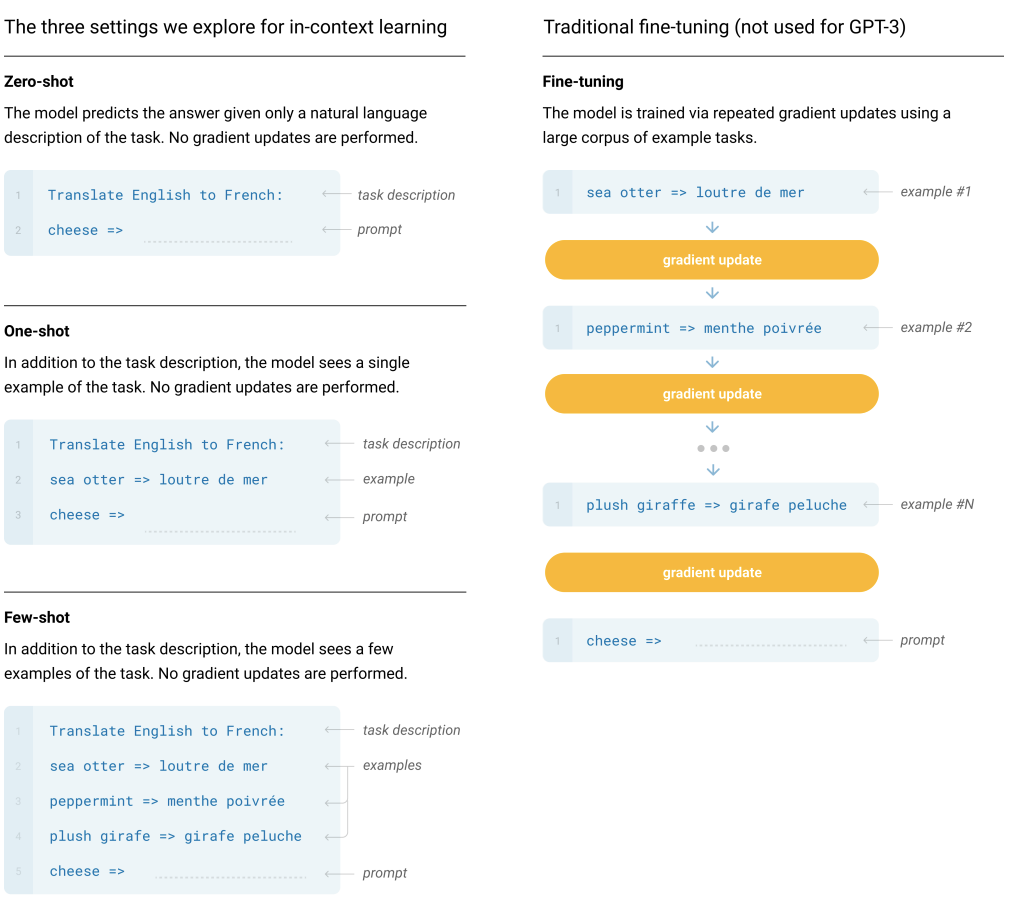
zero-shot, one-shot, few-shot, fine-tuning의 여러 학습 방법 중의 하나로 몇가지의 학습 예를 바탕으로 학습을 하는것으로 보면 된다.
처음에는 몇가지의 학습 데이터로 학습한다는게 무슨 의미인지 처음에는 잘 몰랐다. GPT-3를 살펴보다 보니, 최근의 NLP 태스크들은 사전학습 후에 추가로 대용량의 라벨링된 데이터들을 파인튜닝하는 과정을 통해 해결하려고 하는데, 활용 측면으로 보았을 때 다양한 NLP 태스크들에 대해서 큰용량의 라벨링된 데이터를 얻는건 어려움이 있을 것이기 때문에 인간의 학습 방법과 유사하게 학습하기 위해 Few-Shot, Zero-Shot등의 학습이 대해 계속적으로 연구하는 것으로 보인다.
Contents
- Introduction
- Approach
- Result
- Measuring and Preventing Memorization Of Benchmarks
- Limitations
- Broader Impacts
- Related Work
- Conclusion
etc. 기타 디테일한 사항들
