Nvidia Apex를 이용한 모델 학습 최적화
Language Model Pretraining을 Colab에서 하다 보면, 학습시간도 단축하고 싶고, 배치 사이즈도 늘려서 학습하고 싶다는 생각이 들게 됩니다.
자료를 찾아보다가 위와 같은 문제를 단 몇줄의 코드로 해결해주는 Nvidia의 APEX를 알게 되어 정리합니다.
이전에 언어모델 Pretraining 코드에서 apex, amp, fp16 등과 같은 키워드 들을 보면 뭔지 몰라서 스킵 하다가 결국에 그 부분들을 다시 찾아보게 되는것을 보면 처음에 꼼꼼하게 보는것이 장기적으로는 시간을 줄여준다는 생각을 가지게 됩니다.
APEX와 AMP
APEX란 A Pytorch Extension의 약자로 pytorch에서 쉽게 분산학습과 mixed precision을 사용할수 있게해주는 Nvidia의 툴입니다. APEX 안에 Amp(Automatic Mixed Precision)을 사용해 배치 사이즈를 늘리고 학습시간을 단축시키고자 합니다
AMP (Automatic Mixed Precision)
amp는 apex 에서 단 3줄만으로 mixed precision으로 학습 할수 있게 만들어주는 도구입니다. mixed precision 학습을 통해 배치 사이즈 증가, 학습시간을 단축, 성능 증가의 장점을 얻을 수 있습니다.
Mixed Precision이란? 처리 속도를 높이기 위해 FP16(16bit Floating Point) 연산과 FP32(32bit Floating Point)를 섞어서 학습하는 방법입니다. FP32 대신 FP16을 사용하게 되면
절반의 메모리 사용량과8배의 연산처리랑의 이점을 가진다고 합니다.
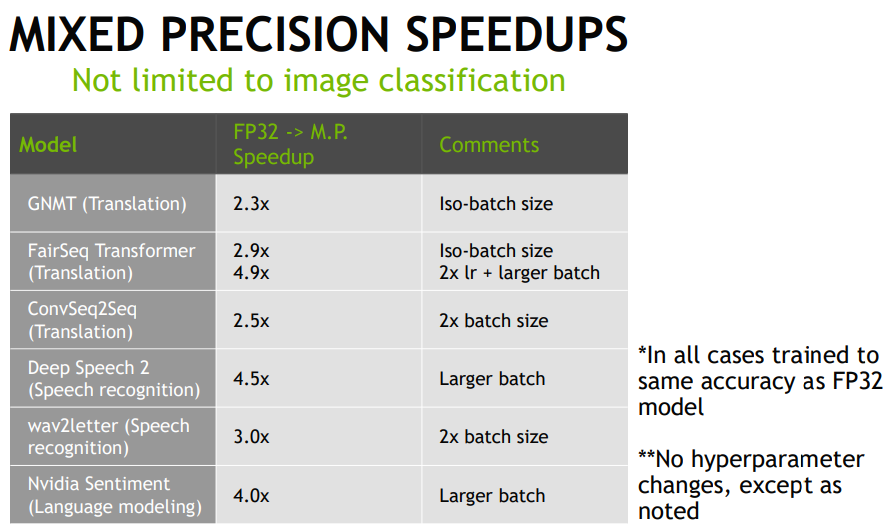
속도 비교
기존 FP32에서 mixed precision 학습을 사용한 경우에 속도 비교입니다.
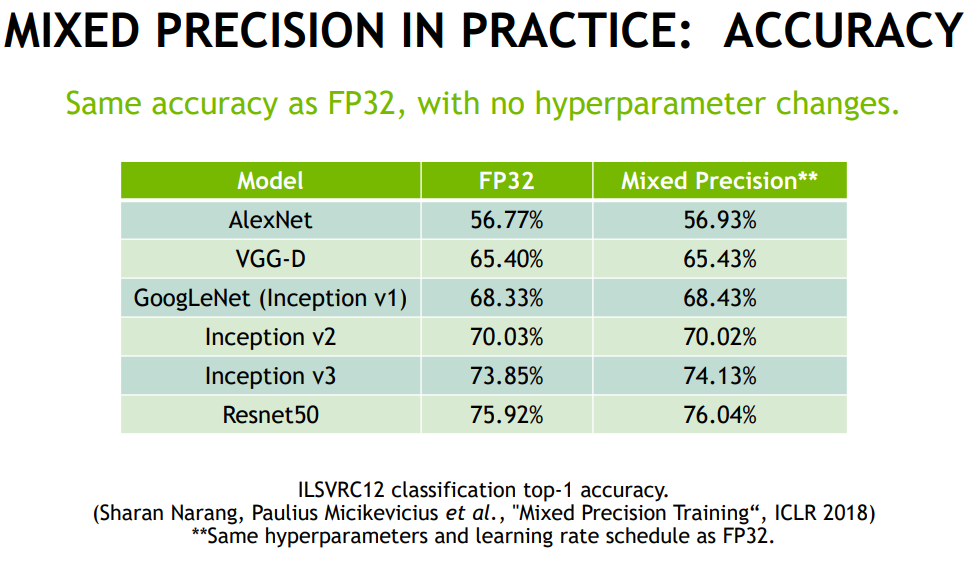
정확도 비교
기존 FP32에서 mixed precision 학습을 사용한 경우에 정확도 비교입니다. 성능 향상의 경우 배치사이즈 증가로
예제 코드
저의 경우 ELECRA를 사전학습시키는데 apex.amp를 적용하고자 했습니다.
# 1. Model & Optimizer
model = Electra(
config=train_config,
gen_config=gen_config,
disc_config=disc_config,
num_tokens=tokenizer.vocab_size,
)
optimizer = AdamW(optimizer_grouped_parameters,
lr=learning_rate,
eps=adam_epsilon)
...
# 2. AMP Initailize
if fp16:
model, optimizer = amp.initialize(model, optimizer, opt_level=fp16_opt_level)
...
# 3. Loss Compute
loss = loss / gradient_accumulation_steps # divide loss into gradient accumulation step
if self.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
...
# 4. Weight Update
if global_steps % gradient_accumulation_steps == 0:
if self.fp16:
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), max_norm=1.0)
OPT_LEVEL 설정
amp를 설정할때 opt_level을 설정해야합니다. 이때 사용하는 opt_level 4가지(O0, O1, O2, O3)에 대해 살펴봅니다.
model, optimizer = amp.initialize(model, optimizer, opt_level=fp16_opt_level)① O0 : 기존 FP32
AMP 적용없는 버전
② O1 : 가장 기본으로 사용하는 opt_level
Tensor Core에서 사용하는 연산은 FP16으로 계산하고, 정확한 계산이 필요한 경우 FP32로 계산하는 옵션입니다. 특별히 설정하지 않는 경우 dynamic loss scaling으로 학습하기 때문에 Model weights를 FP32로 유지시키기 위해서는 Loss를 Scaling 해야합니다.
③ O2 : O1 설정보다 더 FP16 사용하는 설정
Batchnorm Weights를 제외한 Model Weight를 FP16으로 캐스팅합니다. Batchnorm과 Master Weight는 FP32로 유지시키기 위해 Dynamic Loss Scaling이 필요합니다.
④ O3 : 오로지 FP16을 사용하는 속도만을 위한 설정
FP16만을 사용한 속도만을 위한 설정입니다.
FP16과 FP32 차이
FP16과 FP32에 대해 알아보고자 합니다. 컴퓨터는 숫자를 부동소수점으로 표현하여, 일련의 1과 0의 이진 형태로 저장합니다.
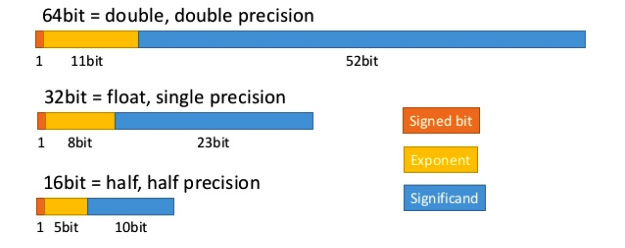
Single Precision 32비트 형식에서는 양음을 나타내는 비트 하나와 지수를 위한 비트 8개, 숫자를 나타내기 위한 23비트로 구성됩니다. Half Precision의 경우 양음 1비트, 지수 5비트, 유효비트 10비트를 사용합니다.

혼합정밀도 컴퓨팅은 단일 작업 내에서 다른 정밀도 수준을 사용하여, 정확도를 유지하면서도 계산 효율성을 가지는 컴퓨팅 방법입니다. 혼합 정밀도에서는 빠른 행렬 연산을 위해 half precisiono으로 계산하고, 계산 결과는 더 높은 정밀도로 저장되게 됩니다. 그 예로 16비트 행렬의 곱은 32비트로 저장됩니다.
이러한 기술은 최대 25배까지 계산 가속이 가능하며, 필요한 메모리 및 전력소비를 줄이는 장점을 가집니다.
