
1. Reformer 개요
Illustrating the Reformer를 보며 정리.
리포머 모델을 2020년에 발표된 모델로 기존 트랜스포머 구조를 개선한 모델이다. Local Sensitve Hashing과 Reversible residual network를 이용해 이전 트랜스 포머 보다 더 많은 입력을 사용할 수 있으며, 낮은 메모리 사용량을 가지면서 거의 유사한 성능을 내는 모델이다. 논문의 저자는 텍스트 뿐만아니라 이미지에도 실험해보았다.
트랜스포머 모델 구조의 단점.
트랜스포머 모델이 뛰어난 성능을 가지더라도. 뛰어난 성능을 내는 모델들은 매우 뛰어난 컴퓨팅 능력을 가진 컴퓨터에서만 학습을 할 수 있고, GPT-2 모델과 같이 1.5B의 파라미터를 가진 모델의 경우는 단일 GPU로는 fine-tuning 조차 할 수 없다.
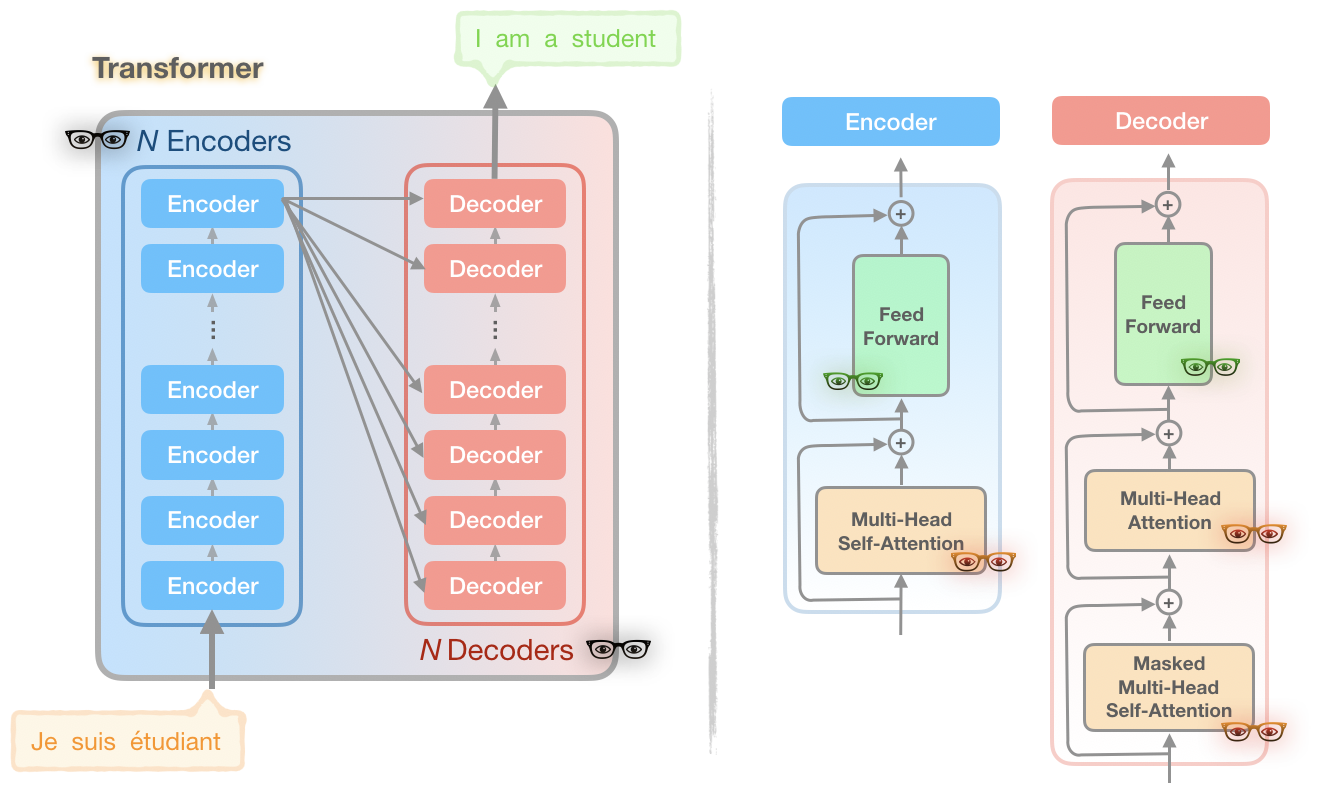
위 그림에서 3가지 색이 다른 안경을 통해 트랜스 포머가 가진 이슈들을 설명한다.
문제1. 빨간 안경 - 어텐션 계산
길이 을가진 문장의 어텐션을 계산할 때, 의 메모리와 시간 복잡도를 가진다.
문제2. 검은 안경 - 많은 수의 레이어
N개의 레이어는 N배 많은 메모리를 사용한다. 그리고 각각의 레이어는 역전파 계산을 위해 그 값들을 저장해둔다.
문제3. 녹색 안경 - 피드포워드 레이어의 깊이
피드포워드레이어가 어텐션의 액티베이션 깊이보다 더 클 수 있다.
Reformer에서의 해결
리포머 모델은 트랜스포머를 개선하여, 단일 가속기와 16GB 메모리를 이용해서 백만 단어에 이르는 context window를 다룰 수 있다.
2. Reformer LSH(Locality sensitive hashing)
어텐션과 근접 이웃(attention and nearest neighbors)

트랜스포머 모델에서는 위와 같이 3종류의 어텐션이 있다. 어텐션의 과정을 그림으로 보면 아래와 같다.
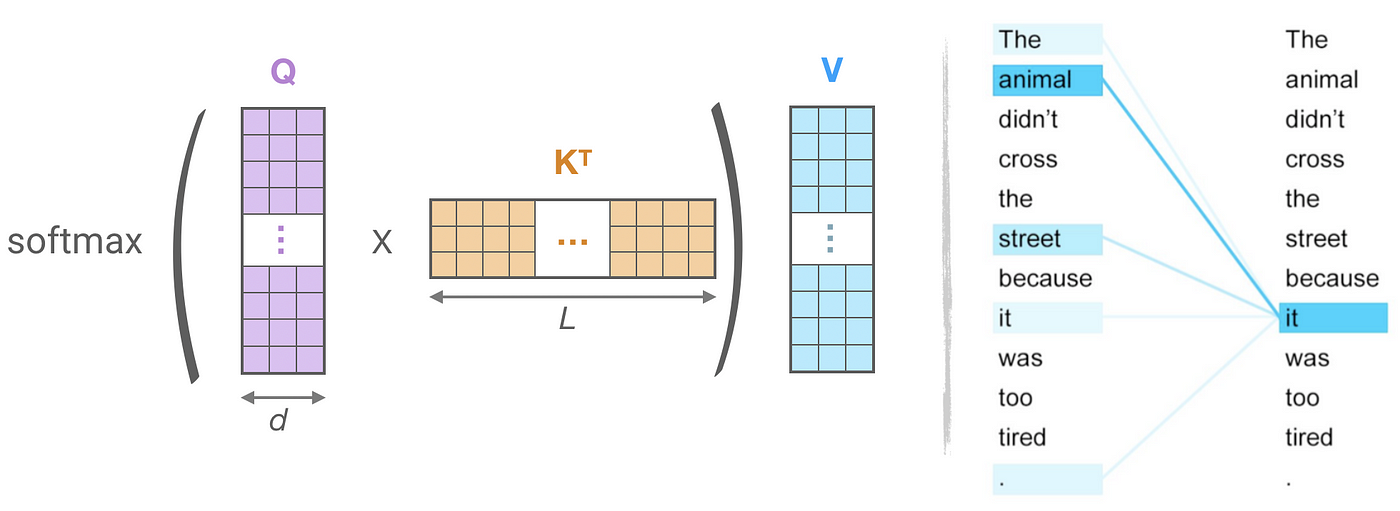
이때 우측에 it의 어텐션을 모습을 보면 5개를 제외하면, 어텐션을 받지 못했는데, 이때 나머지 didn't,cross 등과 같은 단어들은 어텐션을 받지 않아, 실제로 행렬의 모습은 sparse 하게 된다.
따라서 우리는 쿼리 에 대해 밀접한 연관을 가진 에 대해서만 어텐션을 하면 된다. 하지만 기존 트랜스포머의 구조는 이부분을 비효율적으로 찾고, 이 부분을 리포머에서 개선한다.
리포머에서는 Dot-Product 어텐션을 locality-sensitive hasing(LSH)로 대체하면서 를 로 개선했다.
LSH 소개
LSH는 고차원 데이터에 대해 nearest neighbor 알고리즘을 효율적으로 근사하는 방법으로 알려져있고, 두 점 p, q가 충분히 가깝다면 해시 함수를 거친 결과가 hash(p) == hash(q)으로 가정한다.

임의의 직선 h1, h2, h3를 그어 영역에 따라 0과 1로 분류 한다. 각 포인트는 3개의 해시 값을 가지게 되고, 그 해시값이 버켓이라고 보면 된다. 이때 각 충분히 가까운 포인트는 거의 같은 버켓에 들어갔을음 볼 수있다.
Angular LSH

Angular LSH는 기존 LSH의 변형의 일종이다. 포인트들은 이미 정의된 지역으로 나누어진 단위 구 안에 투영된다. 이때 포인트들을 연속으로 랜덤으로 회전 시키게 되면 포인트가 속하는 버킷을 위와 같이 알 수있다. 위 그림은 3번 랜덤 회전을 하는 모습이고, 두 포인트간의 거리가 떨어져 있어 랜덤으로 회전 시, 같은 버켓에 잘 들어가지 않는 모습을 볼수 있다.
아래 그림의 경우 두 포인트가 충분히 가까운 경우 같은 버켓에 들어가는 것을 볼수 있다. 우측의 주황색 해시 값이 보라색과 같이 021로 나와야 하는데 321로 나오는것은 그림이 잘 못된 부분 같다

3. LSH Attention
1. LSH 어텐션의 절차
- Q와 K 매트릭스의 LSH 해시를 찾는다
- LSH를 거쳐서 같은 버켓 안에 있는 와 에 대해서 아래 어텐션을 계산한다.

Multi-round LSH attenstion
충분히 가까운 항목들이 다른 버켓에 빠지지 않도록, LSH를 여러번 반복한다.
2. LSH Attention 전체 과정

- LSH로 query, key들에 대해 버켓팅
- 버켓에 따라 정렬
- 청크 단위로 분리
- 같은 버켓 안에 있는 자기 자신과 이전 요소들에 대해서 attention
4. Reversible Transformer
RevNet, Reversible residual Network
트랜스포머에서 인코더와 디코더 레이어를 여러개를 쌓을 때, Residual Network에서 역전파를 위해 그래디언트 값들을 저장하고 있다. 이때 저장하고 있는 값들이 매우 많아, 큰 트랜스포머 모델을 사용할때 메모리 부족 현상이 쉽게 나타난다. 이러한 문제를 RevNet을 이용해 메모리를 계산 문제로 바꿔서 해결을 시도한다.
각각의 피드포워드레이어와 인코더, 디코더 블록의 경우 Residual Network를 사용하는데, 메모리 부족을 reversible block으로 구성된 reversible residual network (RevNet)로 해결한다. RevNet의 경우 아래와 같이 ResNet을 재구성한다.
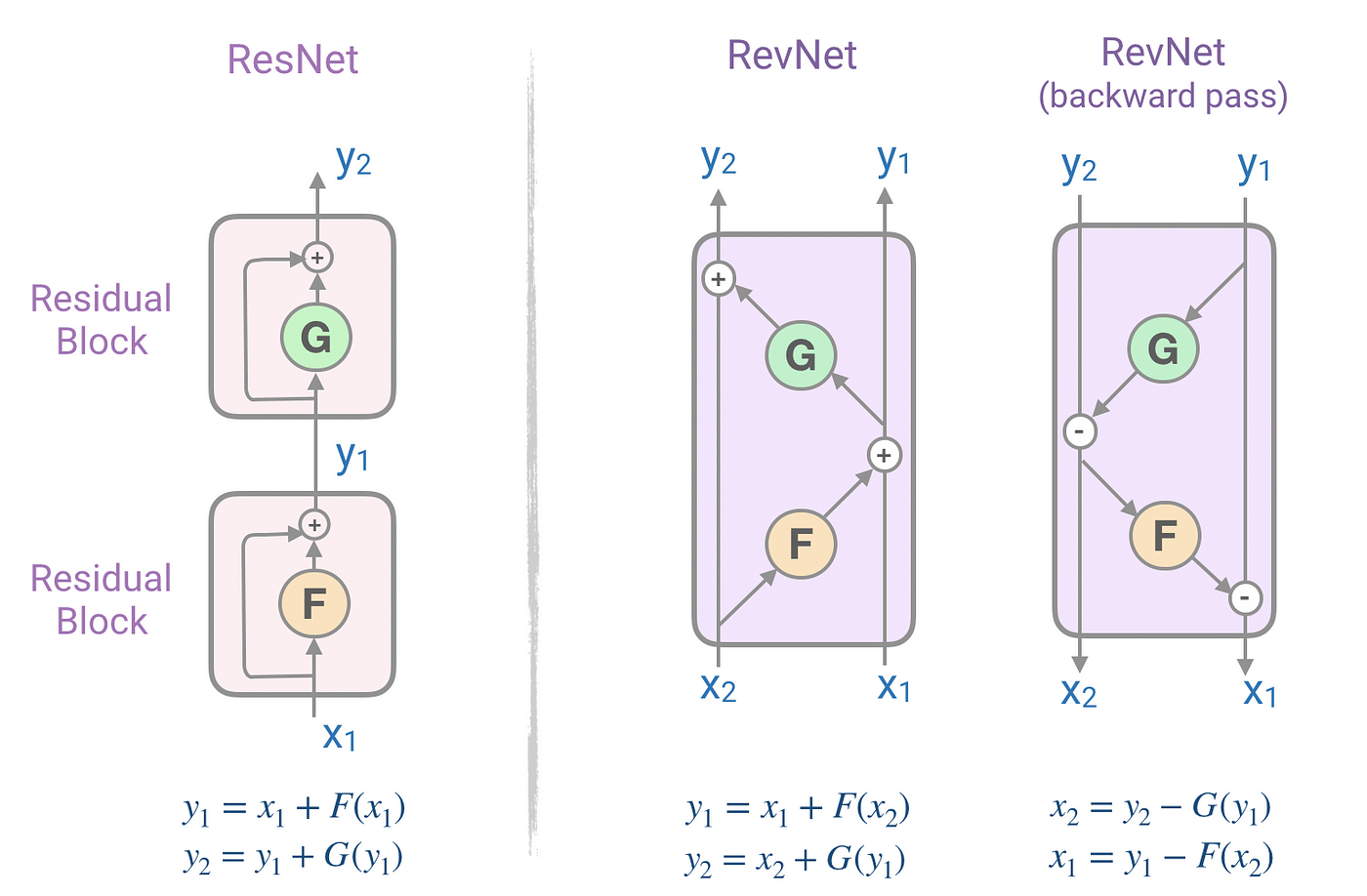
Reversible Transformer
리포머는 RevNet의 아이디어를 트랜스포머에 적용했다. 어텐션과 피드포워드 네트워크를 아래와 같이 바꾸었다.
위와 같이 RevNet으로 변경 하면서, 기존에 학습 하면서 사용했던 메모리를 레이어 N개 일때, 으로 줄이게 되었다.
5. Chunking
1. 내용

리포머는 피드포워드 레이어의 4K 이상 갈수 있는 고차원 벡터들의 메모리를 줄인다. 피드포워드레이어의 각 부분은 위치와 관계없이 독립적이기 때문에 청크 단위로 잘라서 계산이 가능하다. 따라서 메모리에 올라갈때, 청크 단위로 메모리에 올라가게 되어 메모리 효율을 개선할 수 있다.
