트랜스포머 기반 자연어처리 모델 간략하게 훑어보기
허깅페이스의 transformers 모델 요약 문서를 보고 조금씩 정리하고자 합니다. 페이지 내에서 동영상도 있어서, 간략하게 정리해보고자 할때 유용합니다.
해당 글은 하이레벨 관점에서 모델들의 차이점을 다루며 보다 자세한 내용들은 hugging face model 페이지에서 사전 학습된 파일들을 찾아서 테스트 해볼수 있습니다.
허깅페이스 라이브러리에서 제공하는 모델들은 아래의 다섯 카테고리를 따릅니다.
Transformer
트랜스포머 구조
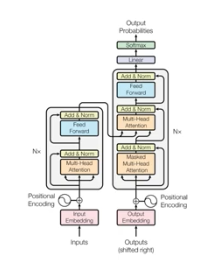
트랜스포머는 Attention all you is need 논문에서 제안된 모델 구조로 인코더와 디코더로 결합된 모델로 위와 같은 형태를 가집니다.
트랜스포머의 추상화된 형태
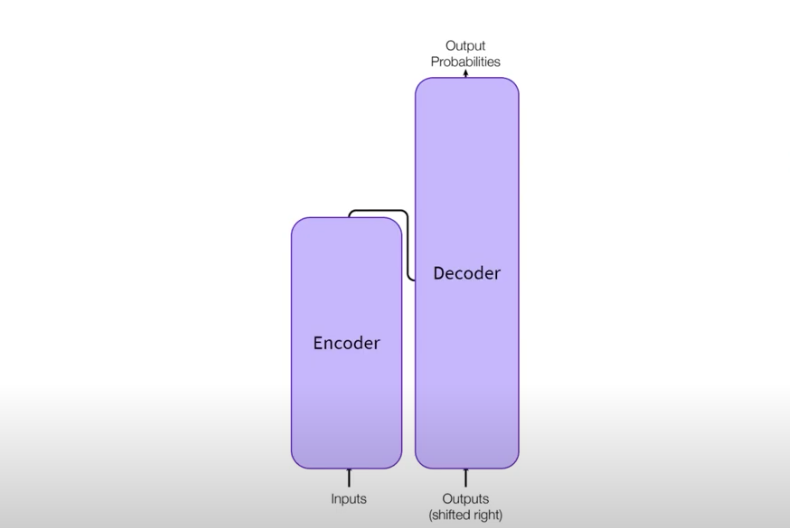
보다 추상적으로 보면 위와 같이 인코더와 디코더 구조로 되어 있는것을 볼수 있습니다.
트랜스포머의 인코더
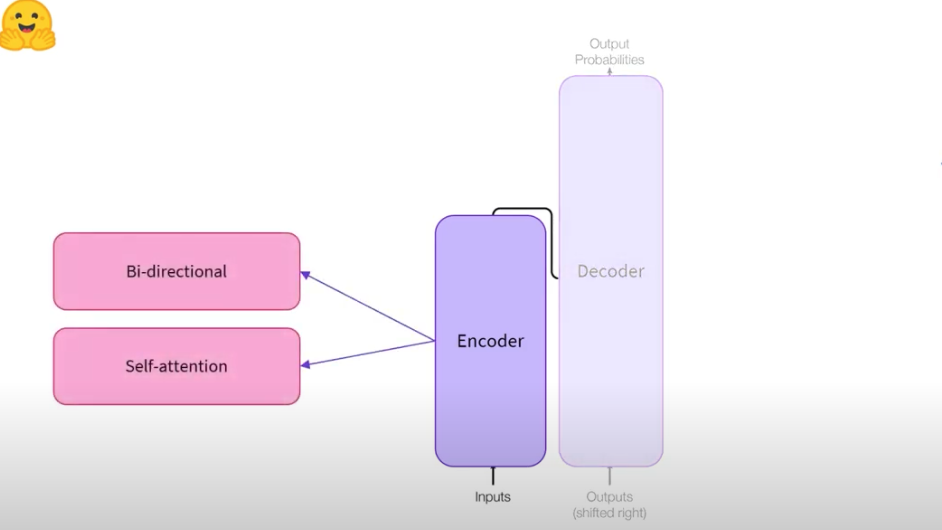
인코더는 말 그대로 텍스트를 숫자들의 representation으로 인코딩하는 역할을 합니다. 이 representation은 Embedding 이나 Features로 부를 수 있습니다.
대표적인 기능으로는 주어진 입력에 대해 양방향(Bi-directional)으로 셀프 어텐션을 적용해 입력을 인코딩하게 됩니다.
트랜스포머의 디코더
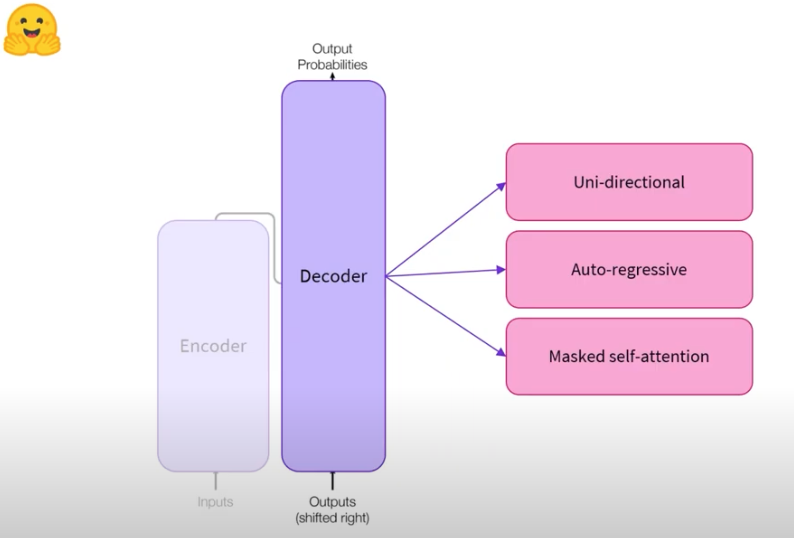
디코더는 인코더로부터 나온 representation들을 디코딩 하는 기능을 합니다. 디코더는 마스크를 사용한 셀프 어텐션인 마스크드 셀프 어텐션을 이용해 단방향으로 Auto regressive하게 학습을 합니다. 이러한 말들에 대해서는 아래에서 보다 자세히 설명하겠습니다 .
시퀀스투시퀀스 모델
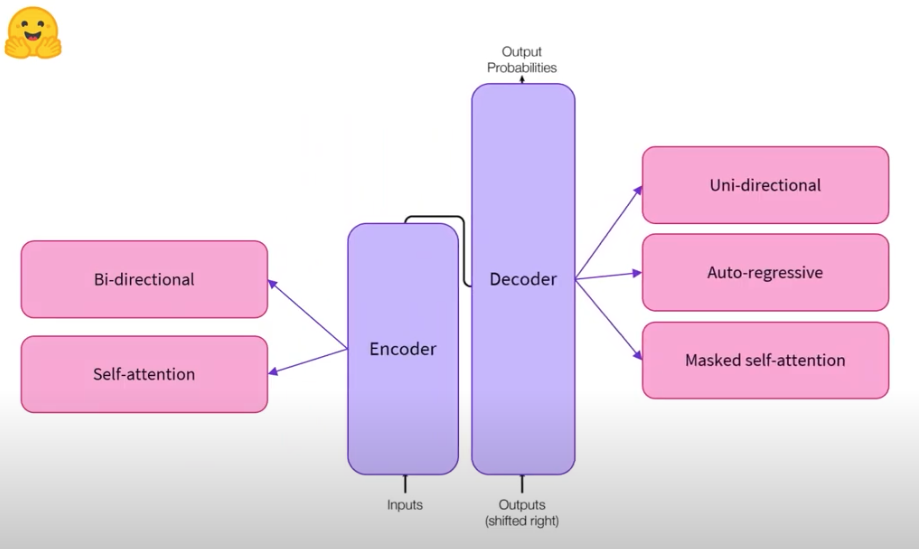
seq2seq 모델의 경우 최초의 트랜스포머 모델에서 제안된 개념으로 인코더와 디코더를 결합한 모델을 말합니다.
인코더는 텍스트 입력을 받아 숫자로 표현될 수 있는 represetaion으로 변환하며, 디코더는 인코더의 출력을 이용해 단방향으로 auto regressive 방식으로 학습하게 됩니다.
대표적인 트랜스포머 모델의 종류
1. Autoregressive Model
오리지날 트랜스포머 모델의 decoder를 사용하며, 이전 모든 토큰들을에 대해 다음 토큰을 예측하는 방식으로 대해 사전 학습 된다. 트랜스포머 어텐션에서 다음 문장을 예측할때, 전체 문장의 윗부분을 마스킹 처리하여, 어텐션 헤드가 예측하고자 하는 다음 토큰 이전까지만 볼 수 있도록 한다. 대표적인 모델로는 GPT 모델이 있으며, 대표적인 예로는 텍스트 생성 태스크가 있다.
2. Autoencoding Model
오리지날 트랜스포머 모델의 encoder를 사용하며, 입력 문장의 토큰들을 변경하여, 이것들을 원본 문장들을 맞추는 방법을 통해 사전학습 되는 모델을 말한다. Autoregressive model과 달리 마스킹이 사용 되지 않아, 입력 문장의 토큰들에 대해 모두 접근이 가능하여, bidrectional representation을 학습한다. 많은 과제들에 대해 좋은 성능을 얻었다.
3. Sequence-to-sequence Model
시퀀스 투 시퀀스 모델의 경우 오리지날 트랜스포머 모델의 encoder와decoder를 모두 사용한 모델이다. 많은 태스크들에 대해 파인 튜닝이 가능하며, 번역, 요약, 질의응답들에 많이 사용된다. 대표적인 모델로는 T5 모델이 있습니다.
4. Etc, 기타
- Multimodal Model: 텍스트 입력과 이미지 등을 혼합하여 학습하는것을 말한다.
- Retrieval-base model
Autoregressive Model
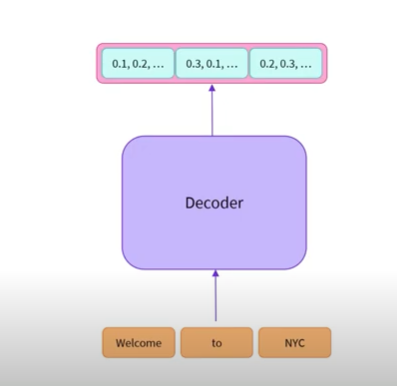
디코더 모델을 입력을 Numerical Representation으로 변환 합니다. 이때 Numerical Representation은 숫자들의 나열로 볼 수 있습니다.
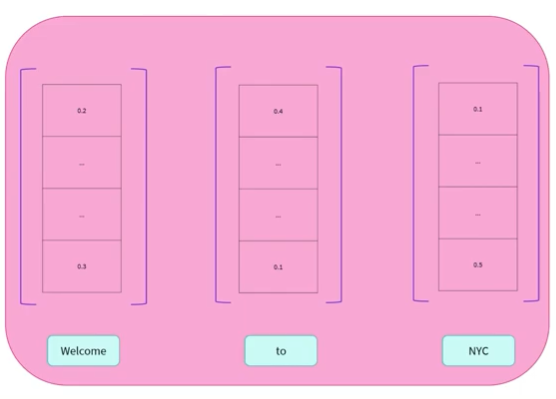
디코더의 출력을 보면 위와 같이 Numerical Representaion으로 변환 되는 것을 볼수 있습니다.
이때 Auto Regressive Model의 경우 Masked Self attention을 이용해 학습하며, 대표적으로는 GPT 계열의 모델들이 있으며, 문장 생성에 좋은 성능을 보입니다.
Causal Language Model
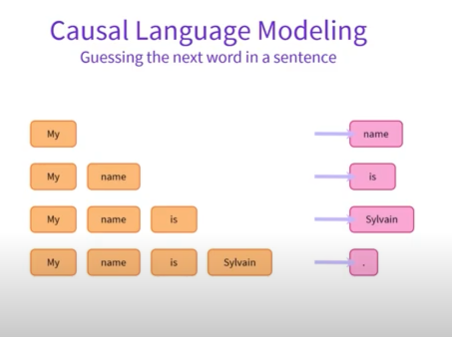
Causal languge model의 경우 autoregressive model의 또 다른 말로 문장에서 단방향 모델을 통해 다음 단어를 예측, 추측하는 언어모델을 말합니다.
위 이미지에서 볼 수 있듯 My name is Sylvain을 Causal Languge Model을 통해 문장에서 다음 단어를 예측하는 방법을 보여줍니다 .
GPT
- Improving Language Understanding by Generative Pre-Training, Alec Radford et al.
- 트랜스포머 기반의 첫 autoregressive model이다. 데이터로는 Book Corpus 데이터를 사용해 사전 학습 하였다.
GPT-2
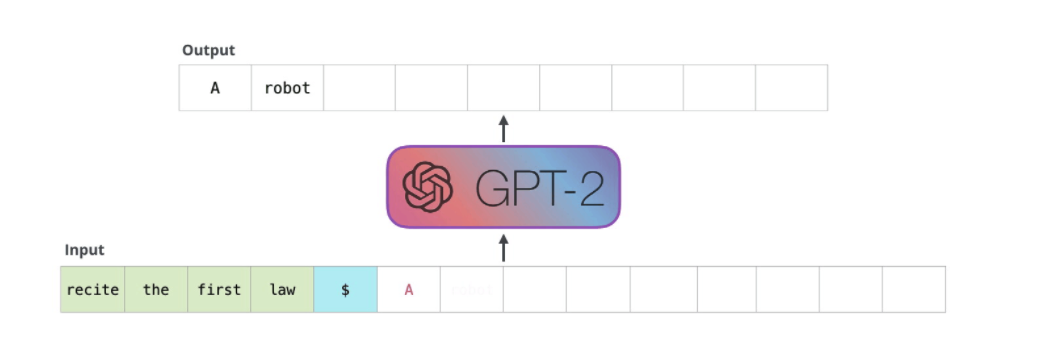
- Language Models are Unsupervised Multitask Learners, Alec Radford et al.
- GPT 보다 더 크고 더 나은 버전의 사전 학습된 언어 모델이다. WebText를 사용해 학습 되었고, 래딧의 3 karmas 이상인 외부 링크인 페이지들로 구성되었다.
CTRL
- CTRL: A Conditional Transformer Language Model for Controllable Generation, Nitish Shirish Keskar et al.
- GPT와 같은 모델에
control codes에 대한 아이디어를 추가한 모델. 어떤 프롬프트(비어있을 수 있음)나control codes들 중 하나로부터 텍스트를 생성할수 있다.control codes의 경우 텍스트 생성을 잘 하기 위해 사용 되며, 위키피디아, 책, 영화리뷰같은 스타일로 생성할 수 있다.
Transformer-XL
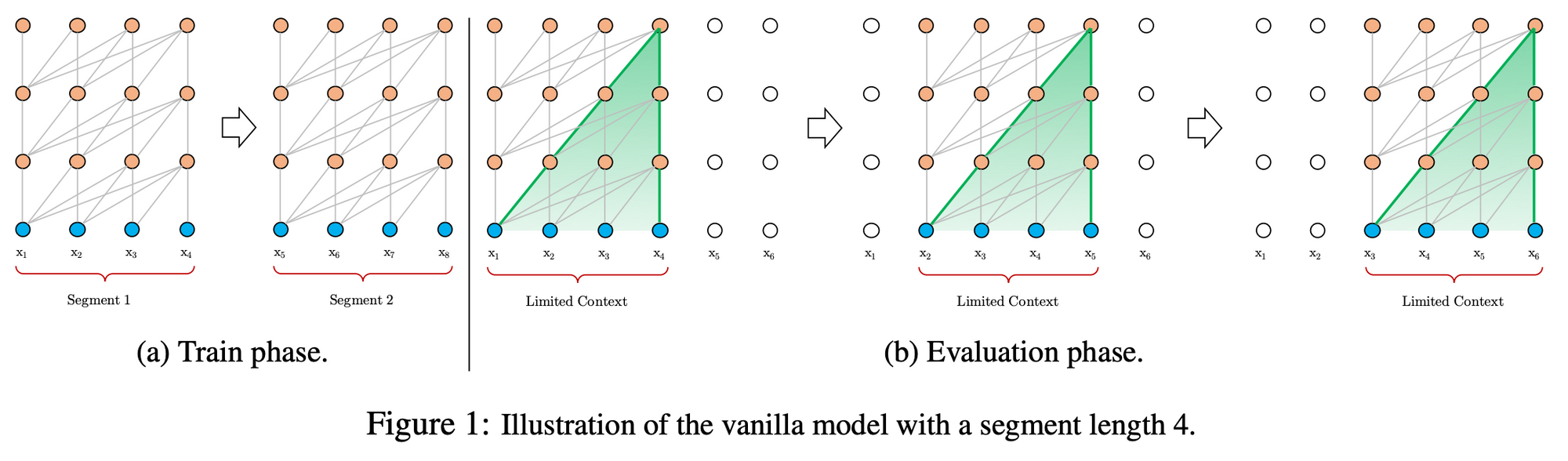
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai et al.
- 일반적인 GPT 모델과 동일하며 2개의 연속적인
segment들을 이용해 Recureence 구조를 사용한 모델이다. 두개의 연속적인 입력을 사용하는 일반적인 RNN 구조와 비슷하며, 이때segment는 연속적인 토큰들의 수(예 512 개의 토큰)를 말하며, 모델에 순서대로 들어간다.
Reformer
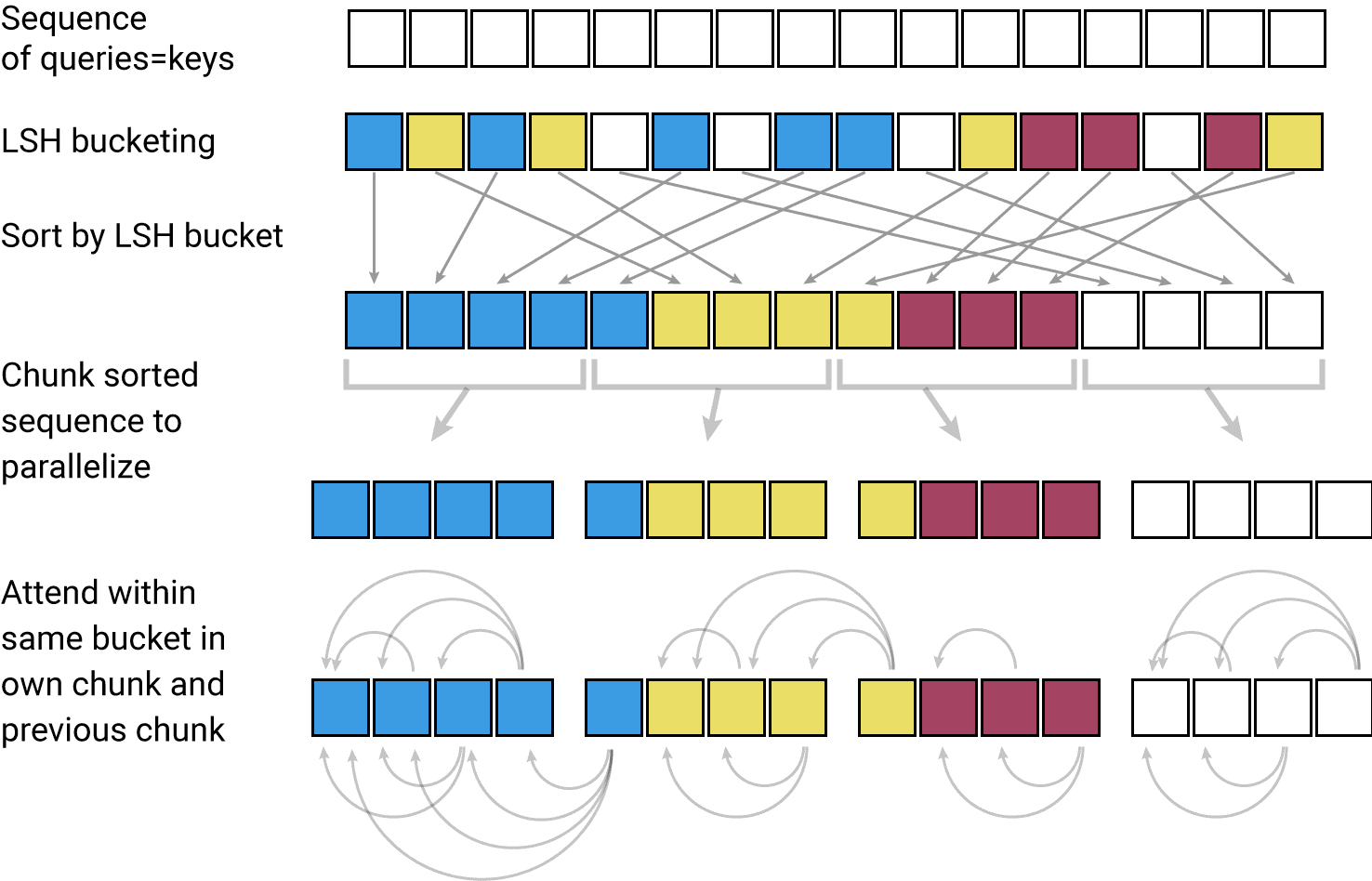 리포머는 트랜스포머의 메모리를 절약하고 컴퓨팅 시간을 줄위기 위한 모델입니다. Axial Positional Encoding, LSH Attention, Reversible Network, Chunk 단위 계산을 사용해 트랜스포머가 가지는 메모리와 컴퓨팅 문제를 해결하고자 했습니다. 리포머를 이용해 더 긴 시퀀스를 가진 입력을 받을 수 있으며, 인코더 디코더 상관없이 적용할 수 있습니다.
리포머는 트랜스포머의 메모리를 절약하고 컴퓨팅 시간을 줄위기 위한 모델입니다. Axial Positional Encoding, LSH Attention, Reversible Network, Chunk 단위 계산을 사용해 트랜스포머가 가지는 메모리와 컴퓨팅 문제를 해결하고자 했습니다. 리포머를 이용해 더 긴 시퀀스를 가진 입력을 받을 수 있으며, 인코더 디코더 상관없이 적용할 수 있습니다.
XLNet
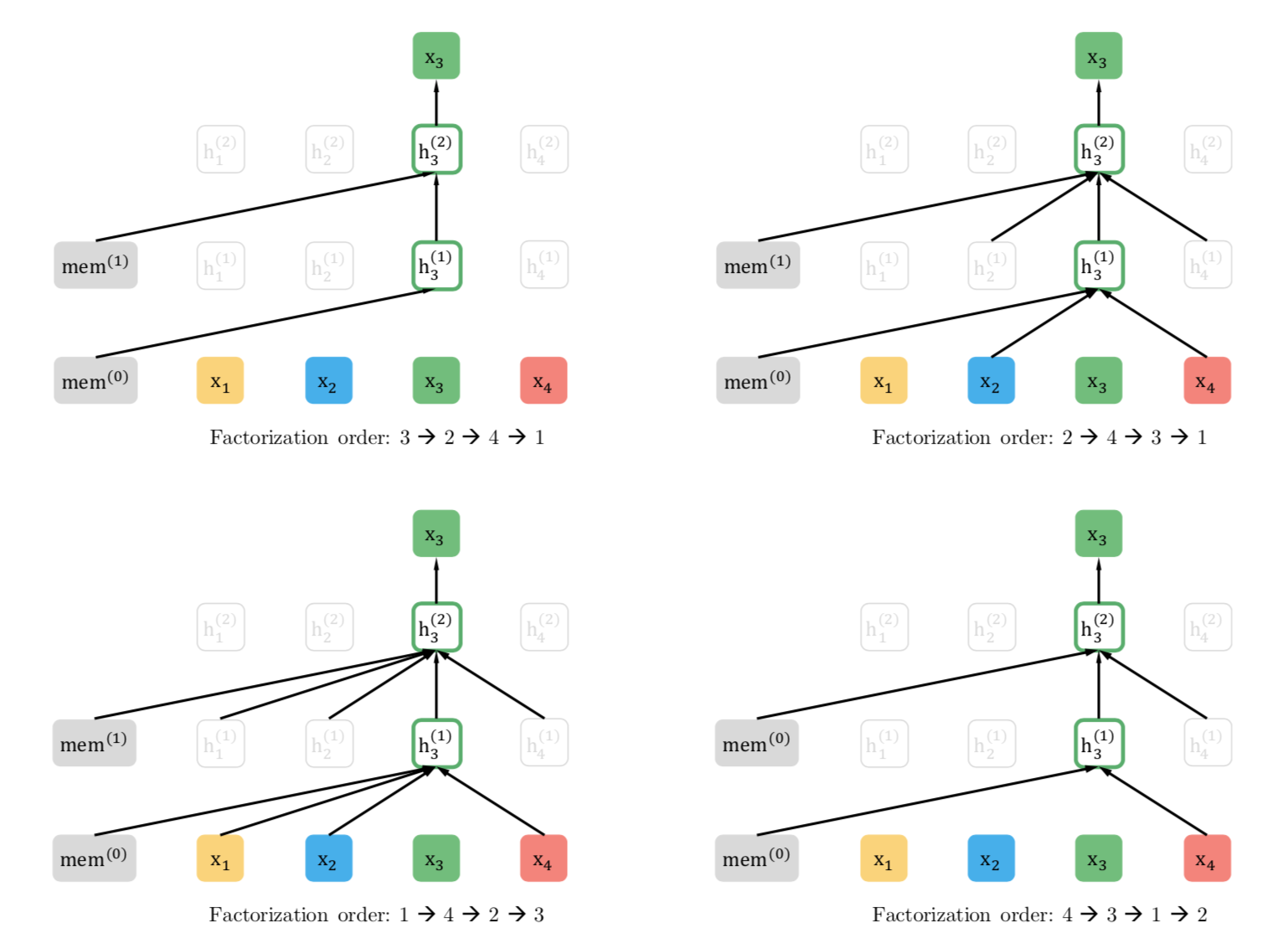
transformer-XL과 동일한 구조를 사용해 긴 문장에 대해서 다룰 수 있는 모델로 GPT와 BERT의 장점을 결합한 Generalized AR Pretraining Model을 제시했습니다.
토큰의 순서를 변화시켜 학습하는 Permutation Language Model과 Two-stream Attention을 제안했습니다.
Autoencoding Model
트랜스포머 인코더에 기반한 모델들을 살펴본다. 프리트레이닝 과정에서 target은 원래의 문장을 사용하고, input으로는 입력을 마스킹하는 방식과 같이 노이즈나, 변경, 또는 수정해서 입력을 인코더에 넣는다.
BERT
BERT는 자연어 처리에서 굉장히 중요한 모델로, 랜덤하게 input을 마스킹을 하여 원래의 문장을 맞추는 Pretraining과정을 거친다. 버트는 일반적으로 15%의 토큰에 대해 마스킹 과정을 거친다:
- 80%는 [MASK] 토큰으로 변경
- 10%는 다른 랜덤 토큰으로 변경
- 10%는 기존 토큰을 사용.
버트 모델을 Masked Language Model 과 Next Setence Prediction을 이용해 pretraining을 거친다. NSP의 경우 버트에 입력되는 두 문장이 연속적인지 아닌지에 대해 binary classification을 통해 맞추는 task로 학습니다.
하지만 다른 논문들에서 NSP가 불필요하다는 견해도 있으므로 참고.
ALBERT
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, Zhenzhong Lan et al.
버트와 같지만 몇몇 부분에서 다른 점을 가진다:
- Embedding size E와 hidden size H의 크기가 서로 다르다. 임베딩의 경우 벡터 representation이 하나의 토큰을 표현하기 때문에 문맥에 독립적이고, 반면에 hidden size의 경우 하나의 hidden state가 토큰들의 시퀀스를 나타내기 때문에 문맥에 의존적이다. 따라서 보다 논리적으로 H>>E인것이 합리적이다. 그리고 H>>E 이면, 일반적으로 임베딩 레이어의 경우 (vocab_size, embedding_size)의 크기를 가지기 때문에 보다 적은 파라미터를 사용할수있다.
- 레이어들을 그룹으로 나뉘어져 파라미터를 공유해 메모리를 절약할 수 있다.
- BERT의 NSP는 SOP(Sentence Order Prediction)으로 대체되어 학습되었다.
