
Unifying Language Learning Paradigms
참고
- https://github.com/google/flaxformer
- https://github.com/google-research/t5x
Abstract
현재까지의 언어모델들은 특정한 유형에 맞춰져 있다. 하지만 어떤 구조가 가장 적합한지, 어떤 세팅이 되어야 하는지 아직 정해진 것들이나 업계 전반에 합의된 것은 없다.
이 논문에서 pretraining을 위한 통합된 프레임워크를 보이고자 하며, 프레임워크는 세팅과 데이터셋에 국한되지 않고 넓게 적용 될수 있다.
우리는 pre-training objectives에 대해 아키텍처적인 원형을 분리하고 NLP에서 self-supervision에 대한 일반화되고 통합된 관점을 보이고자한다. 그리고 서로다른 objective 들 간에 캐스팅 될수 있음을 보이고 효율적으로 interpolating 하는 방법들을 보인다.
논문에서는 다양한 pretraining 패러다임들을 통합하는 Mixture-of-Denoiser(MoD) 를 제안한다.
그리고 나아가서 특정한 pre-training scheme들과 관련 있는 다운스트림 태스크에서 각 모드를 전환하는 개념들을 제시한다. 그리고 다양한 pre-training objective들에 대해서 비교하고 여러 세팅에서 T5, GPT계열의 모델들을 뛰어넘는 성능을 얻었다.
최종적으로 모델은 20B parameter를 가진 모델까지 크기를 키웠고, generation, understanding, classification, qa, information retrieval, text reasoning 등을 포함한 여러가지 50가지 태스크들에 대해서 SOTA를 기록했고 in-context learning에서도 좋은 성능을 보였다.
superGLUE에서 GPT-3 175B 제로샷 성능을 능가하고 1-shot 요약에서는 T-XXL의 성능을 3배 향상시켰다.
Introduction
NLP 태스크에서는 BERT, GPT-3, T5, GPT, Prefix LM, XLNet, LaMDa, PaLM 등 많은 모델들이 있고 어떤 모델들을 쓸지는 항상 어떤 태스크 이냐 라는 질문이 따르게 된다. 그리고 이어서 ‘encoder-only’냐 ‘encoder-decorder’, ‘span corruption’ 이냐 ‘language model’이냐 라는 질문들이 따르게 된다. 이런 것들을 넘어서 여러 태스크들에서 잘 할 수 있는 모델을 학습 시킬지에 대한 문제가 잇었다.
이러한 문제들에서 UL2라고 불리는 Unifying Language Learning Paradigms 이라는 프레임워크를 제안한다.
UL2가 트레이드 오프 없이 여러가지 태스크(superGLUE)에서 좋은 성능을 보이는 것을 알수 있다.
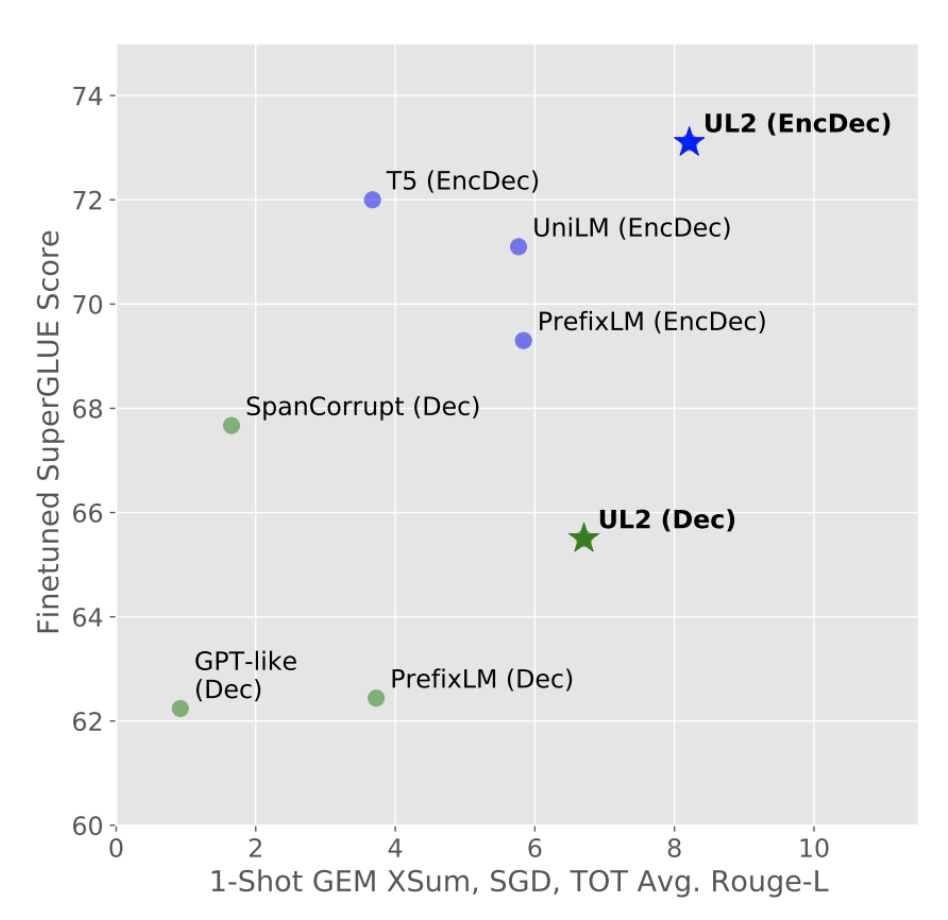
이런 universal model이 필요한 명백한 이유는 개선 시키기 위한 노력을 집중할수 있고, 단일 모델을 확장하는데 집중할 수 있다.(N 개의 모델에 드는 비용보다.)
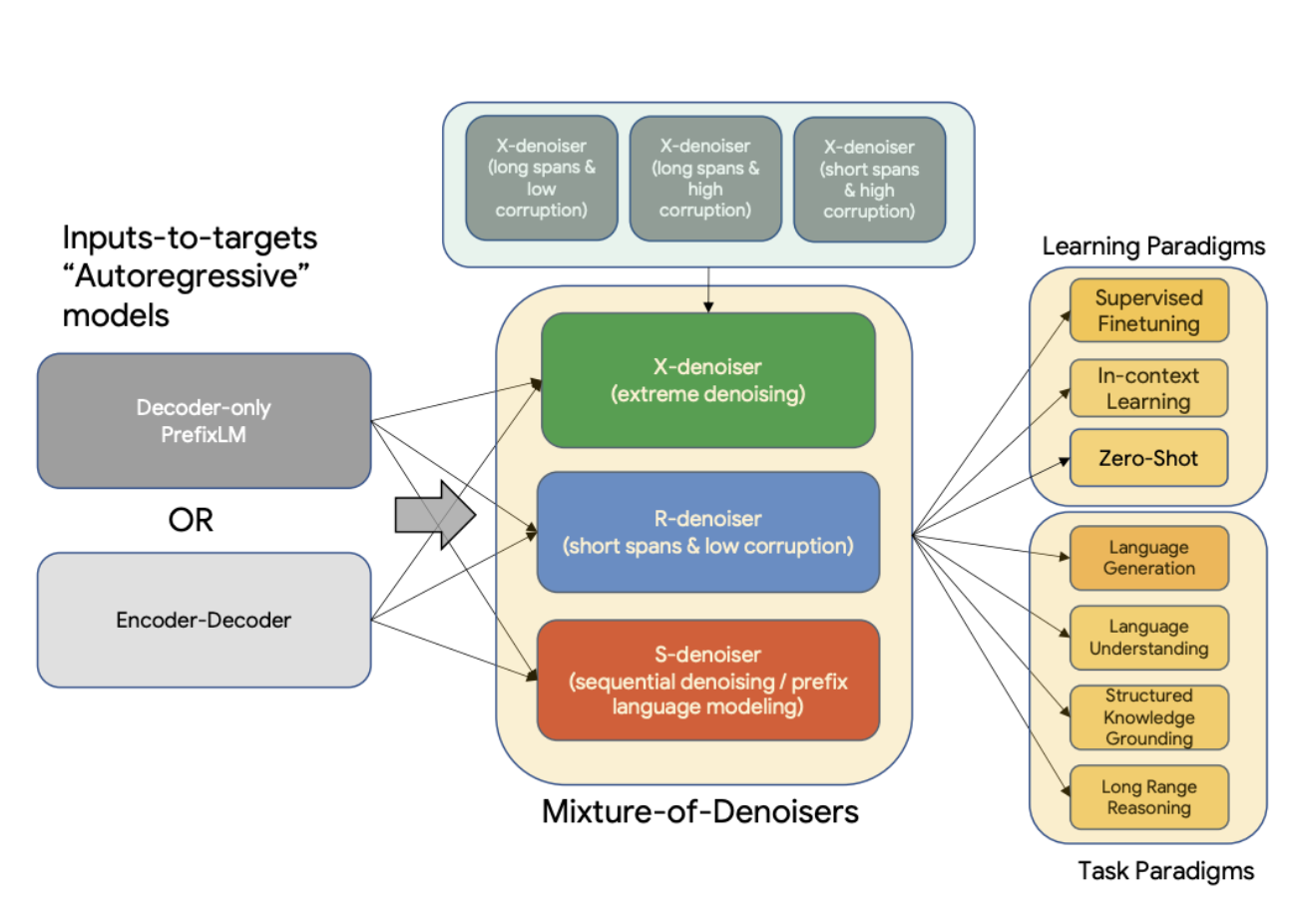
UL2의 핵심적인 부분은 MoD(Mixture-of-Denoiser)라는 개념으로 MoD는 여러 태스크에 걸쳐서 좋은 성능을 낼 수 있도록 한다. MoD는 잘 계획된 여러가지 denoising objective들을 하나로 합치는 개념이다. MoD의 개념은 아래와 같으며 개념적으로는 간단하지만 다양한 세팅과 태스크들에서 매우 효과적이다.
MoD(Mixture-of-Denoiser)

- X-denoising(extreme denoising): 극단적인 span 길이와 corruption rate
- S-denoising(sequential denoising): 시퀀스의 순서를 strictly 따르는것
- R-denoising(regular denoising): T5에서 소개된 일반적인 방식의 span corruption
MoD에 대한 접근 방법은 잘 연구된 pre-training objective들이 context(model is conditioned)의 유형에 따라 다르다는 점을 이용한다. span corruption objective는 prefix language model 분야에서 언급된것과 유사하다. 저자들은 서로다른 paradigm(span corruption, language model, prefix language model)들의 인사이트를 이용해 pre-training 방법들을 잘 결합 할 수 있었다.
Mod 에서 제안하는 denoising 방법론들은 각각 다른 방법에서 어려운것을 알 수 있으며, span corruption 과 같은 태스크 들은 fact completion과 유사하다. 반면에 PrefixLM/LM objective들은 보다 ‘open ended’ 이다. 이런 양상들은 다른 denoising objective들이 cross entropy loss들을 모니터링 하면 쉽게 관찰 할수 있다.
UL2에서는 mode switching 개념을 도입하여 다운스트림 태스크에서도 강점을 가진다. mode switching 개념은 프롬프트의 분리와 지정된 sentinel toke들을 사용하는 것을 통해 각각의 pretraining task 들을 오고 갈수 있다.
이전의 연구들에서는 모델의 구조가 decoder-only, encoder-decoder 중 어디에 속하는지가 더 중요하다고 알려졌었지만 논문에서는 denoising 방법들이 더 중요한것을 발견했다.
성능 비교에서 UL2는 베이스라인으로 삼은 T5와 GPT계열의 모델들 성능을 뛰어 넘었고, 20B까지 모델을 향상 시켰다. 모델은 Flax 기반의 T5X로 학습한 체크포인트로 공개했다.
UL2는 C4 데이터 셋으로 학습하였으나 높은 성능을 보였다. C4는 (Du et al., 2021; Chowdhery et al., 2022) 보다 비효율적으로 알려짐.
Implementation
- JAX/Flax 내 공개 되어 있는 T5X Framework 와 Flaxformer 사용.
- Pretraining: 500K step (128 Batch/ 512 input/ 512 target/ C4 dataset)
- 64, 128 TPUv4 Chips
- Adafactor optimizer
- inverse square root learning rate
- activation: SwiGLU
- 32K sentencepiece
Ablation
Decoder Vs Encoder-Decoder
둘사이의 비교는 어렵다. 따라서 compute-matched setup과 parameter-matched setup을 비교한다. enc-dec 모델의 경우 decoder only 모델 보다 2배 파라미터를 많이 사용하지만 속도는 비슷핟.
Evaluation
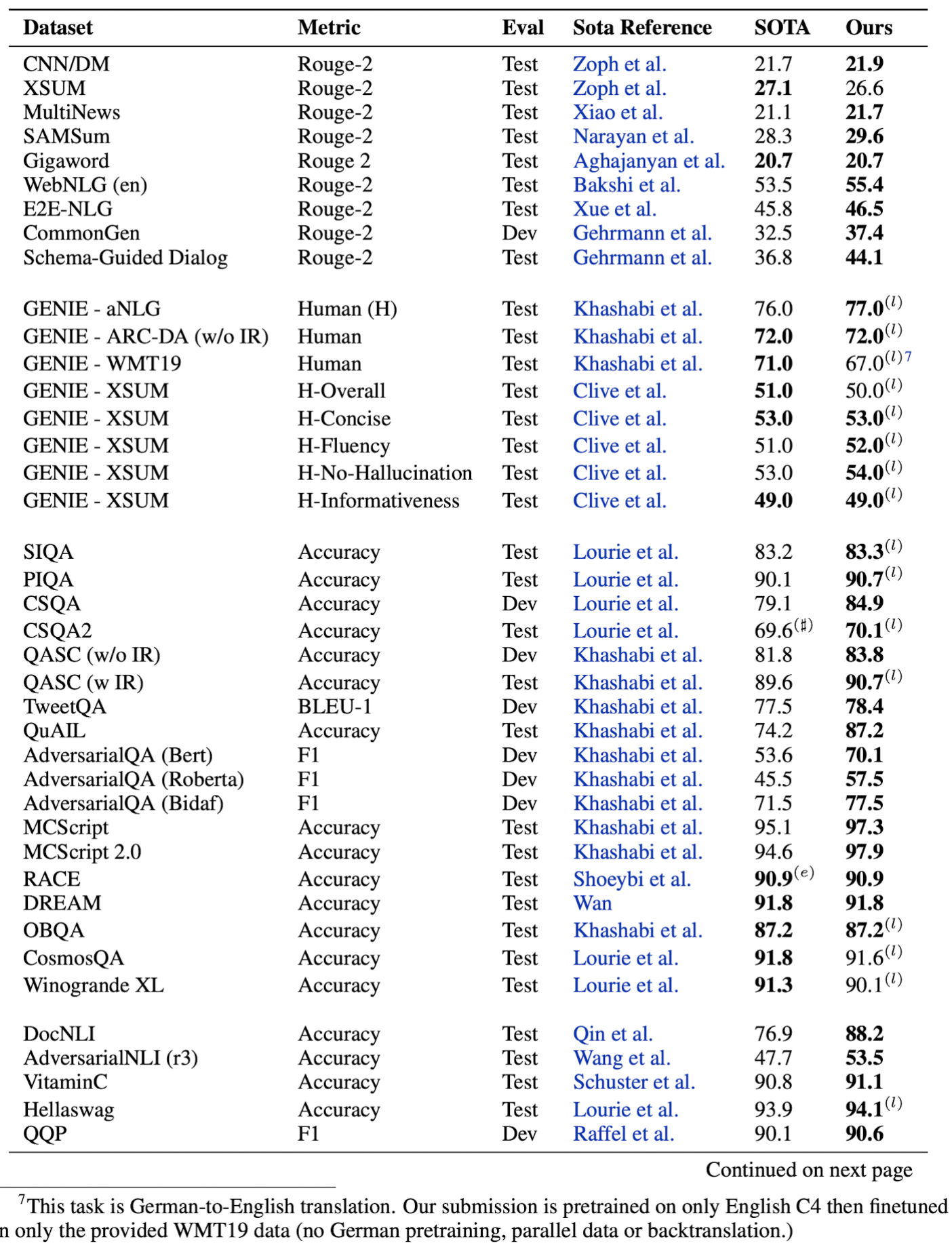
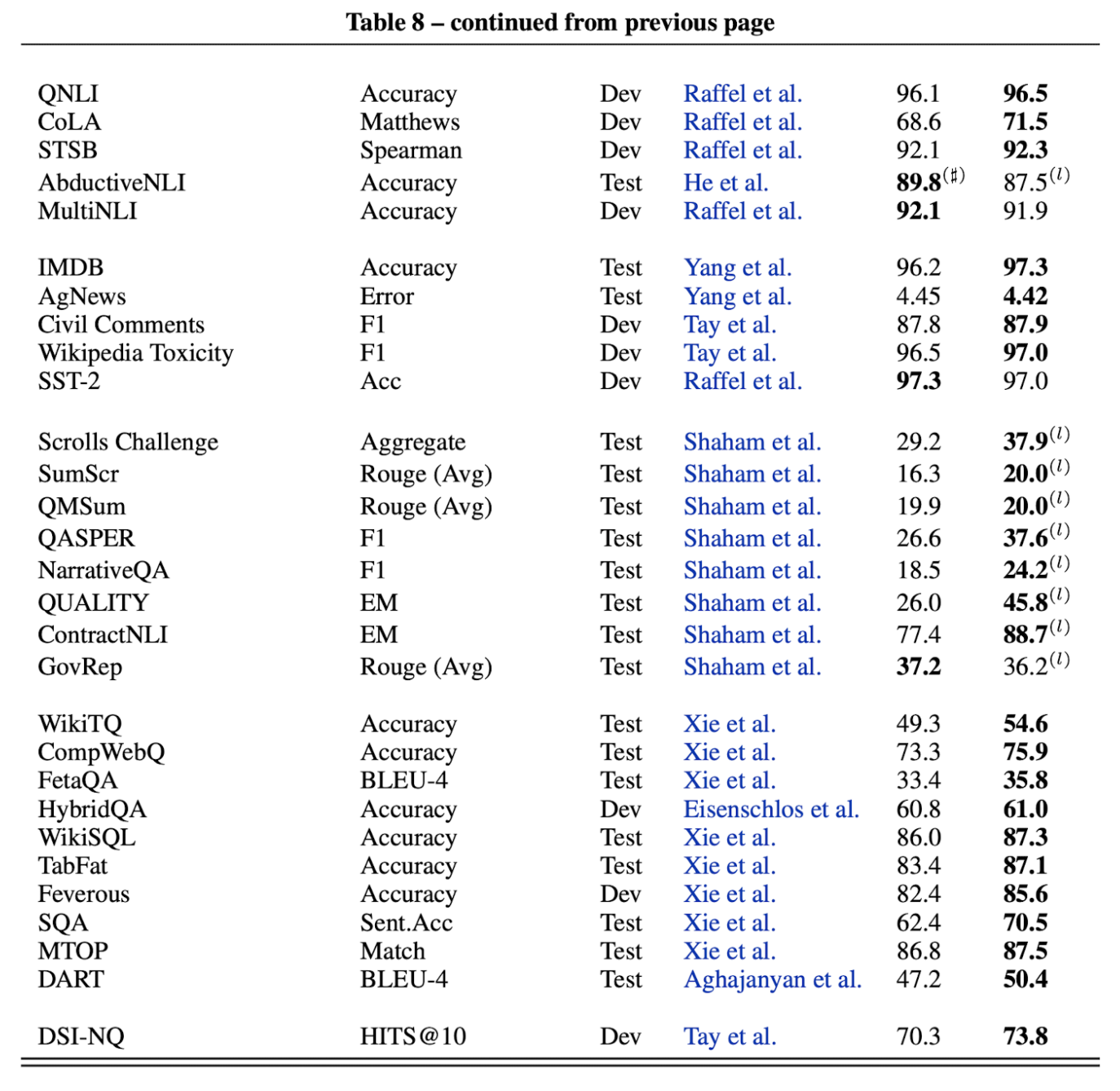
- 20B 모델의 성능
- 기존 SOTA 들과 비교
Table 8: Summary of UL20B results compared to state-of-the-art. (l) denotes leaderboard submission. (♯) denotes the best published we could find on the leaderboard. (e) denotes SOTA used an ensembled approach. Because we evaluate finetuning and in-context trade-offs for SuperGLUE, SuperGLUE
scores have their own dedicated section below.
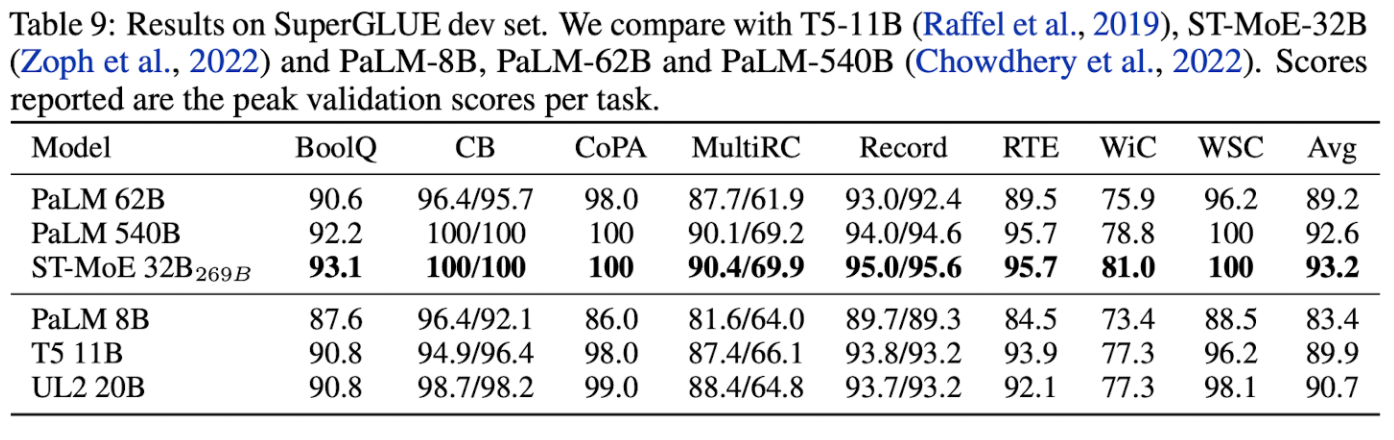
SuperGLUE dev 데이터에 대해서 다른 큰 모델들과의 비교
Conclusion
UL2에서 보편적으로 효과적인 모델을 학습하기 위한 새로운 패러다임을 제시했다. UL2에서는 2가지 주요한 아이디어:
- Mixture of Denoiser
- Model switching: 프리트레이닝 단계와 파인튜닝 단계를 연결하는 방법론.
여러 태스크에서 GPT 계열의 모델과 T5모델 결과들을 뛰어넘은 모델을 제시했다.
