What Language Model to Train if You Have One Million GPU Hours?
Link
Goal
- 100만 A100 GPU 시간을 사용할수 있을때 100B+의 모델을 학습하기 위한 가장 좋은 구조와 학습 세팅은 무엇인가?
Summary
- 여러 트랜스포머 모델의 발전에 따라 태스크별, 모델의 크기별 사용할 수 있는 모델의 구조가 다양하다.
- 하지만 100B 이상 파라미터를 가진 모델을 학습하는데 있어서, 모델의 학습과 설계에는 굉장히 많은 비용이 든다.
- 그리고 모델의 규모에 영향을 받기 때문에 모델링에 있어서 여러가지 사항들을 결정하는데 어려움이 있다.
- 100B+ multilingual 모델을 학습하기 위한 최적의 세팅을 탐색한다.
- 1.3B 모델에서 학습 진행
Contribution
- 제로샷 태스크에서 pretraining corpora, positional embedding, activation functions, embedding norm의 영향도를 확인
베이스모델로 GPT-3 1.3B 모델 사용
Architecture & training objective
- decoder only model ← gpt-3 구조를 사용한 이유는 제로샷 세팅에서 현재 가장 좋은 성능을 보이기 때문
T5, Prefix-LM도 고려
Experimental Setup
- follow gpt-3 setup
- 논문 참고

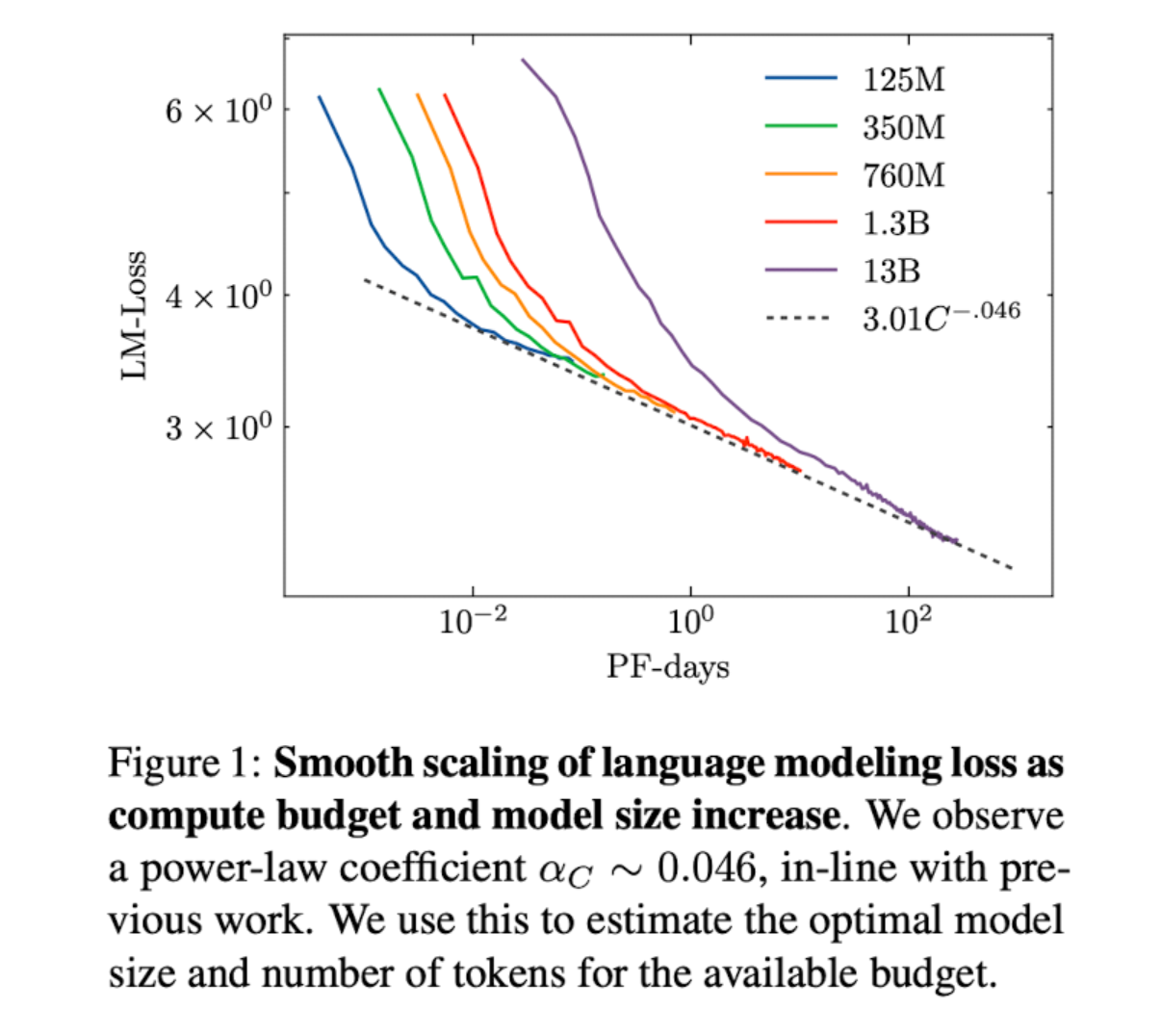
- 112B Token을 학습했으며, 100B+ 모델을 학습 시킬수 있으면서도 컴퓨팅 비용을 고려할수 있는 절충점이 되는 크기의 데이터 사이즈로 학습했다.
- GPT-3와 차별점은 GPT3의 경우 sparse attention을 사용했는데, sparse attention을 사용하는 가장 주요한 이유로는 긴 시퀀스를 처리할때 컴퓨팅 효율을 위해 사용하지만 100B+ 모델에서는 그 효용이 적으므로 제외했다.
컴퓨팅 비용에 대한 출처와 수식은 논문 참고
Corpora
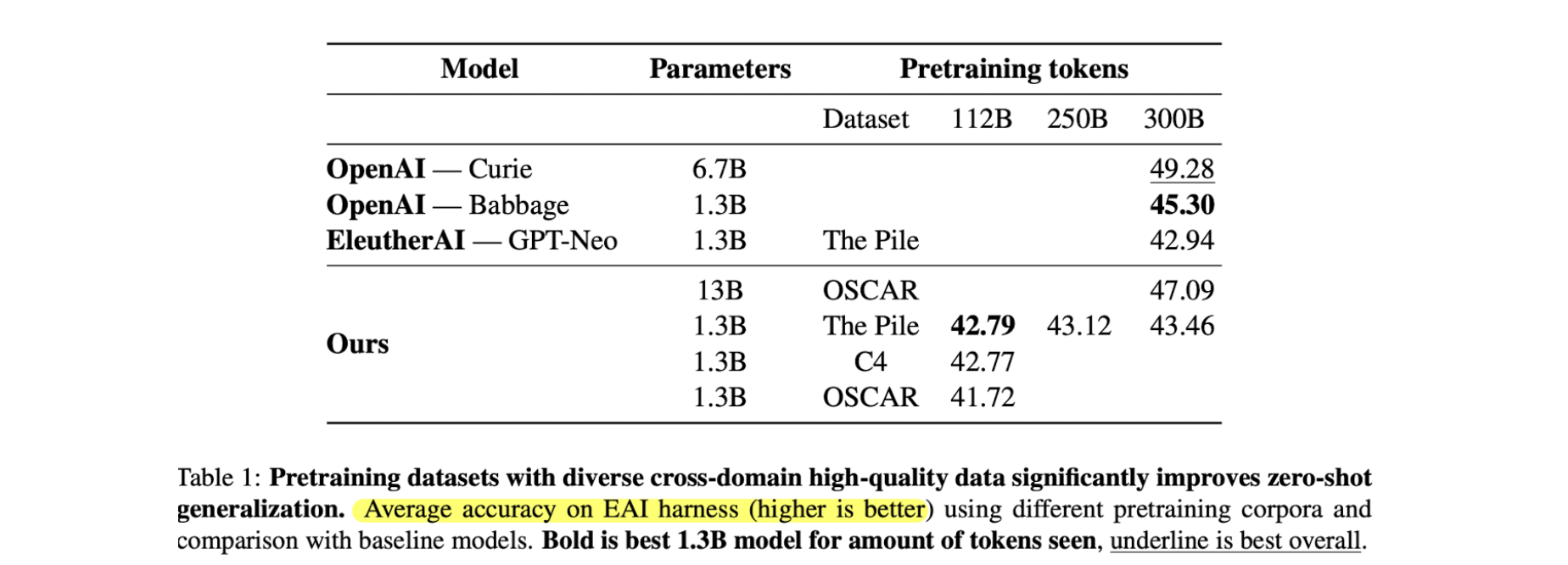
- 여러가지 코퍼스가 있으며, 공개적으로 완전히 사용 가능한것은 Oscar v1, C4, The Pile 데이터가 있다.
- 제로샷에 대해서 평가했을 때 Oscar가 가장 성능이 떨어졌으며
- The Pile이 빨리 수렴하고 좋은 성능을 보였다. 기존 gpt-neo 1.3b 모델의 성능을 뛰어넘음
- 위 세 데이터 모두 common crawl 기반의 데이터
Positional Embedding
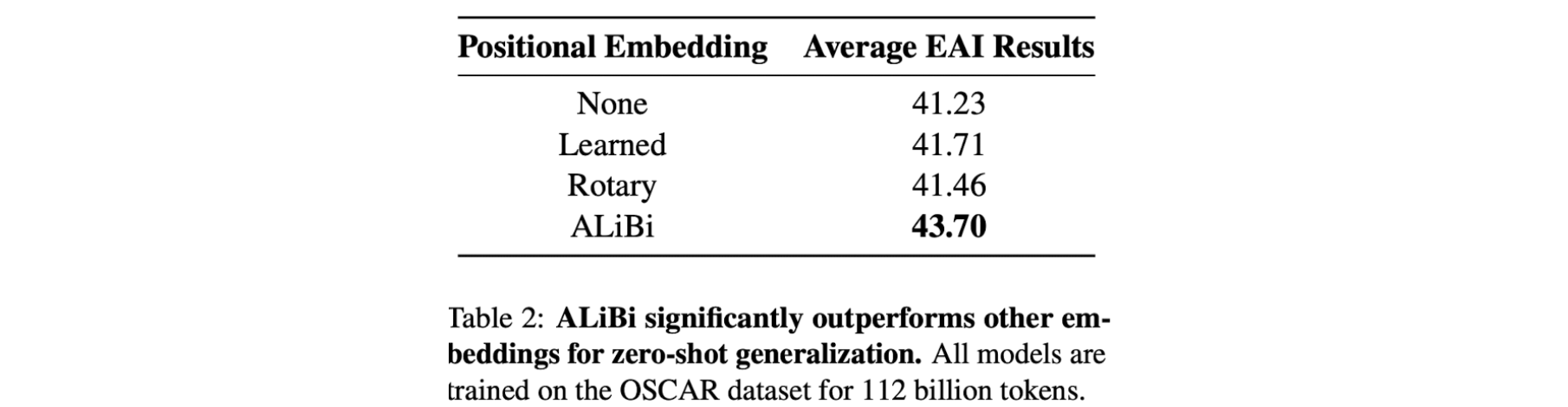
- 포지션 임베딩에는 사용안함, Learned, Rotary, ALiBi 등을 고려했다.
- 기존에 Rotary가 Learned 보다 뛰어나다고 알려져 있었지만 제로샷에서는 낮은 성능을 보였다.
- ALiBi가 큰 점수로 가장 뛰어난 성능을 보임.
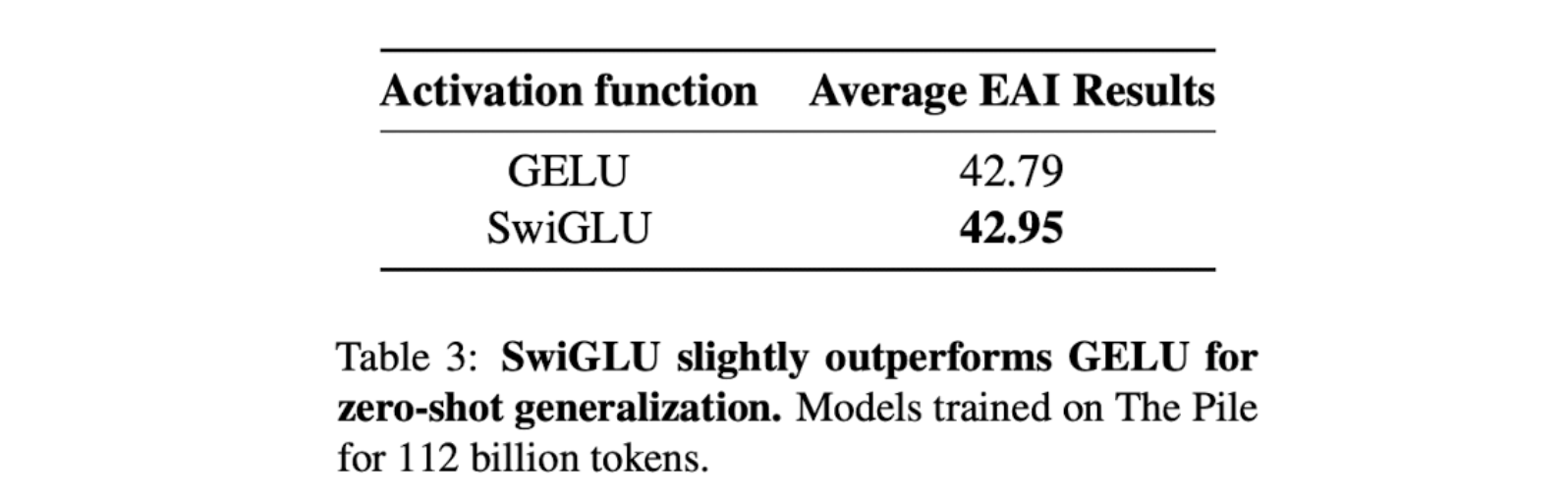
Activation
- 최근에는 language model에서는 대체로 gelu를 많이 사용한다.
- 2020년에 SwiGLU가 공개 되었고 둘간의 비교를 한다.
- 성능 비교시 SwiGLU가 미세하게 더 좋은 성능을 보이나 SwiGLU는 FF layer에서 50%의 추가적인 파라미터를 사용한다. 성능도 추가적인 파라미터 때문에 올라간것일 수도 있다.
- SwiGLU의 경우 분산학습시 이슈가 있으므로 GeLU 사용.
Compute budget
- 18주 동안 52node of 8 80GB A100 GPU 사용.
- 4개의 노드는 하드웨어의 문제 발생시를 고려하여 항상 유휴상태로 두었다.
- 계산 비용 모두 고려시 1M의 A100-hour
Hyperparameter
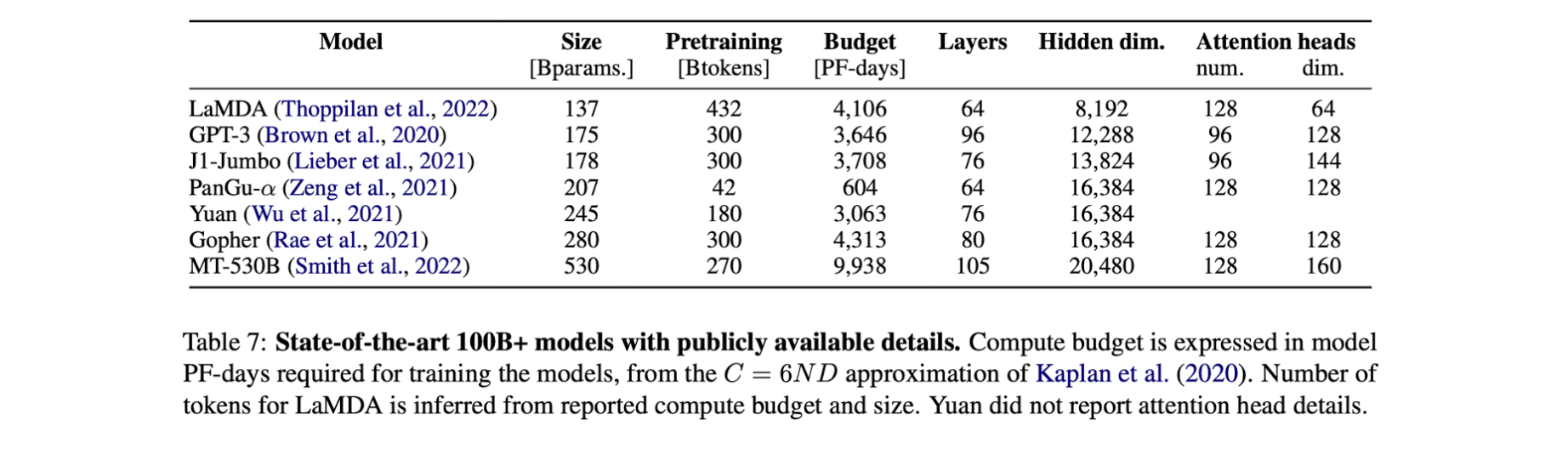
Final Archtecture
- 학습 데이터: 300-400B Token 데이터 사용 (Kaplan et al., 2020)
- 레이어: 70-80 Layers
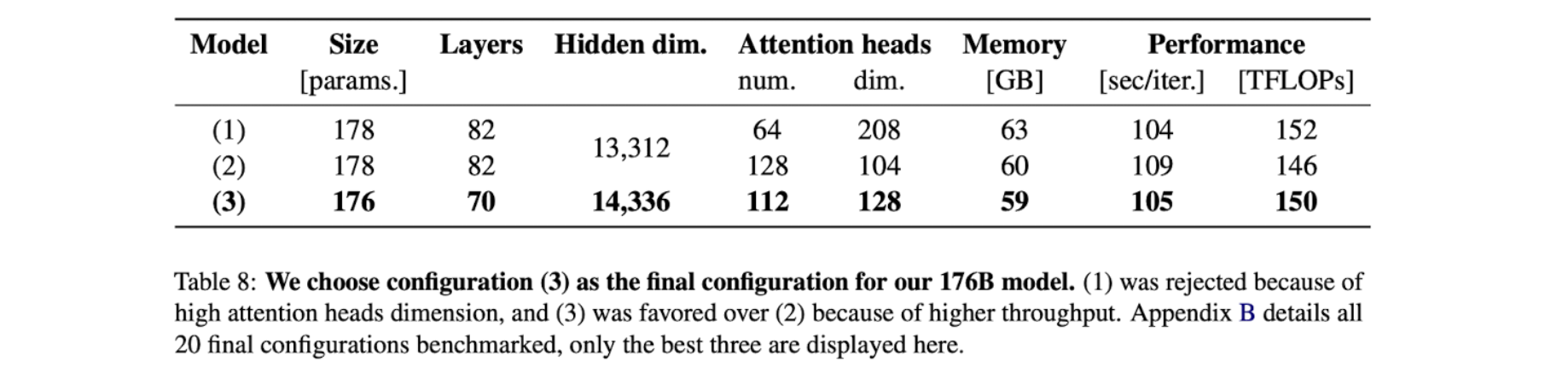
Evaluation details
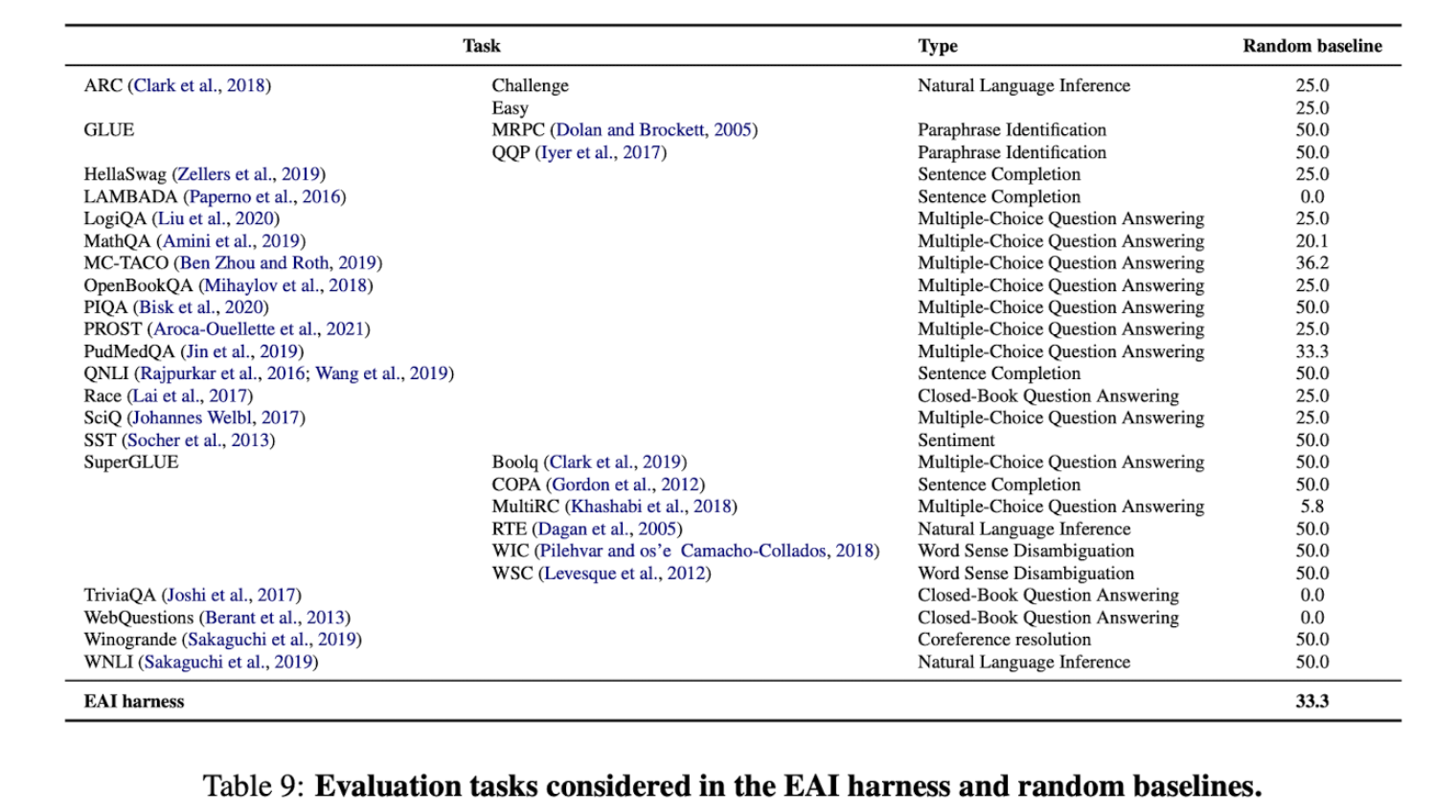
Architecture details