English Wikipedia Extractor
영어 위키피디아 plain text를 얻기 위한 WikiExtractor
💾Github: https://github.com/nawnoes/WikiExtractor
개선내용
-
apertium/WikiExtractor의 경우 문서의 제목 아래에 <pages>와 같은 태그들이 보여 영어 위키피디아의 plain text를 얻는데 불편함이 있었다.
def clean_html(raw_html): cleanr = re.compile('<.*?>') cleantext = re.sub(cleanr, '', raw_html) return cleantext을 사용하여 html 태그들을 삭제
-
문서 본문이 아무것도 없는 경우, 해당 문서 건너 뛰기
def WikiDocumentSentences(out, id, title, tags, text):
header = '\n{0}{1}'.format(title, "|||".join(tags))
text = clean(text)
if text.isspace() or len(compact(text,structure=False))==0:
return
out.reserve(len(header) + len(text))
print(header, file=out)
for line in compact(text, structure=False):
print(line, file=out)사용법
1. Wiki Dump 다운로드
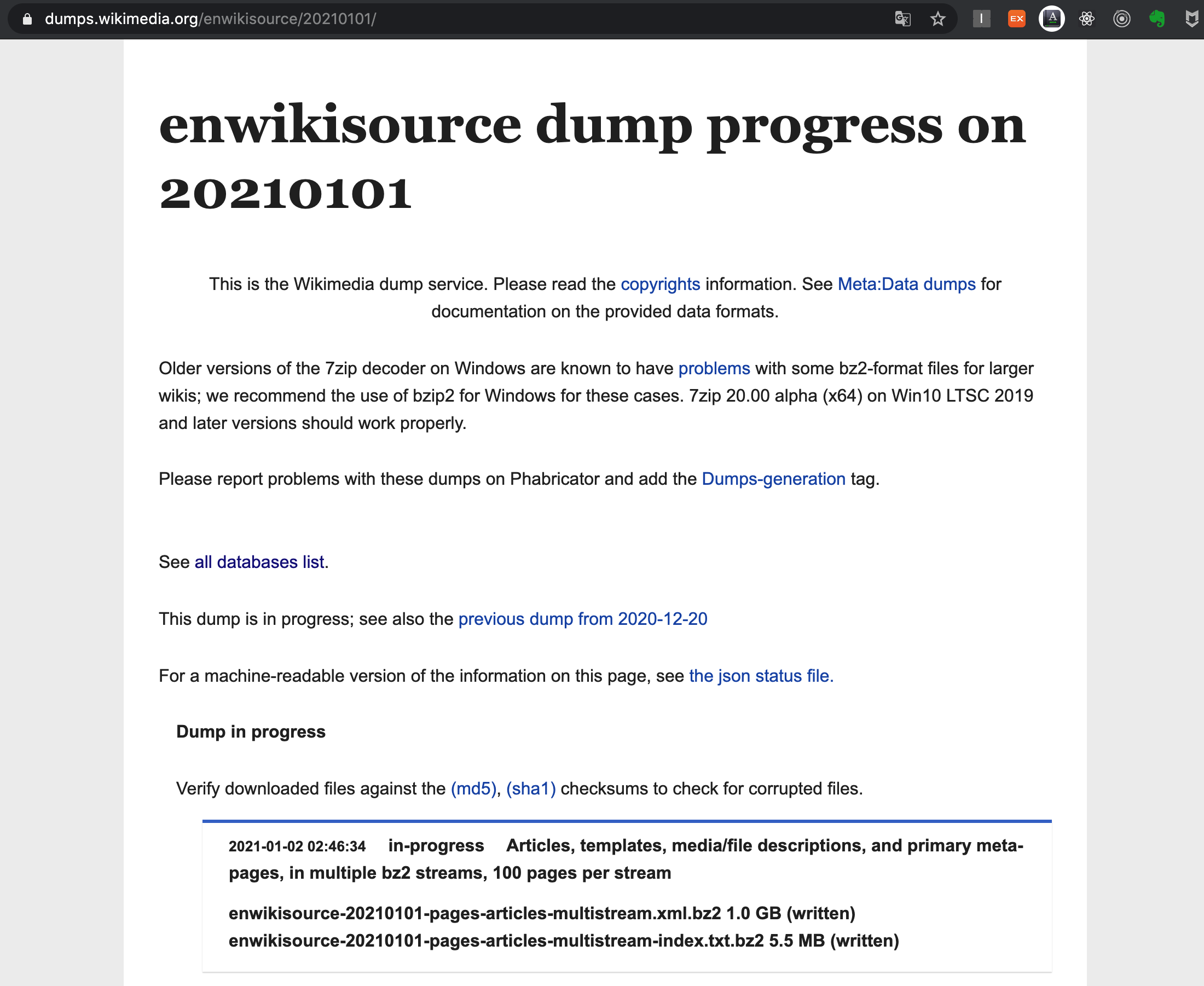
enwikisource dump에서 덤프 파일 다운로드

2. 덤프 파일 저장 후 명령어 실행
- https://github.com/nawnoes/WikiExtractor 에서
WikiExtractor.py다운로드 WikiExtractor.py소스 경로에서 아래 명령어 실행
python3 WikiExtractor.py --infn [다운받은덤프파일명].xml.bz2다운로드 받은 덤프파일의 경로 지정에 주의한다.
3. 생성확인
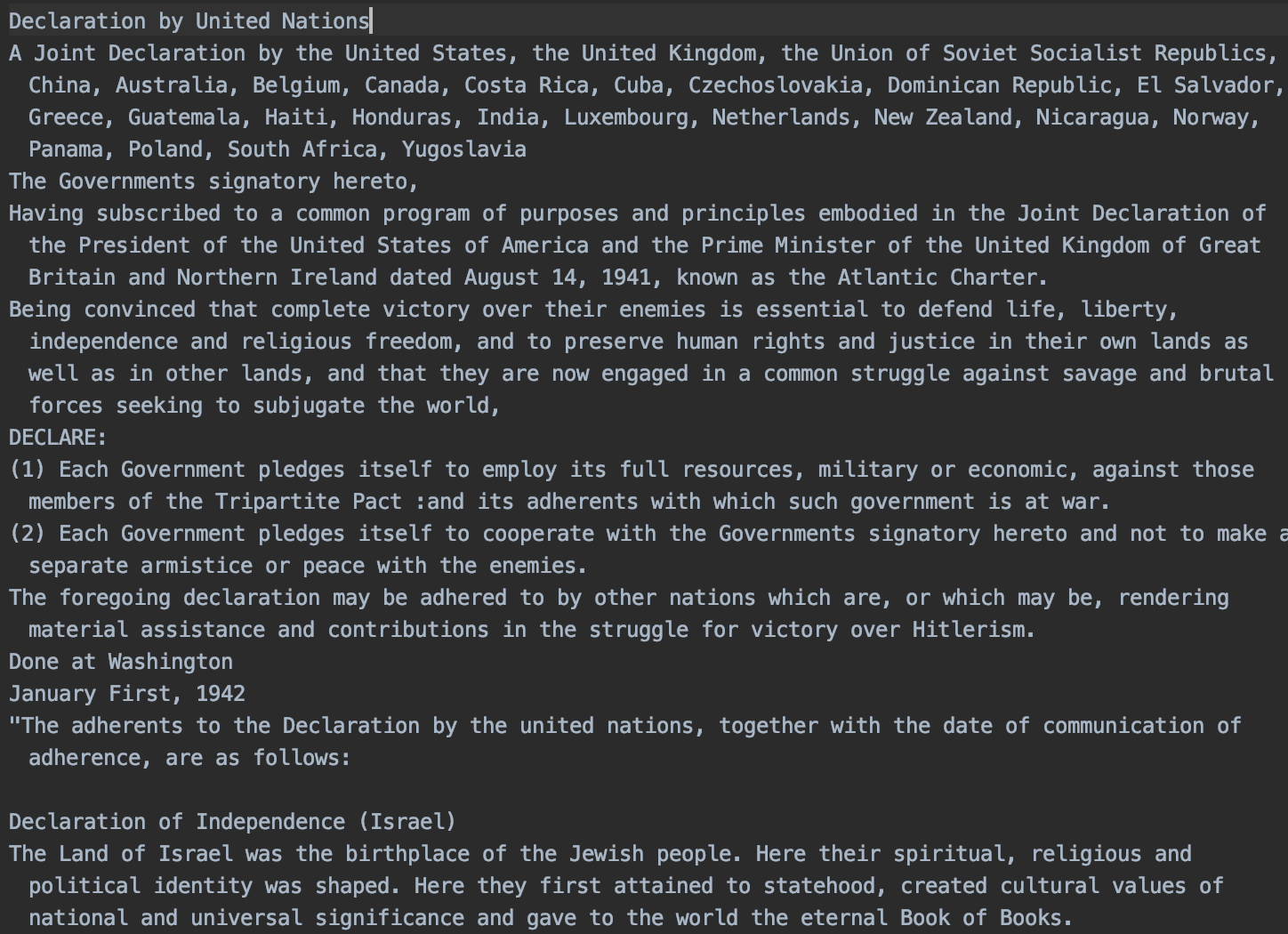
아래와 같은 양식으로 WikiExtractor.py와 같은 경로에 2.03GB의 wiki.txt 파일 생성
제목
본문텍스트
제목
본문텍스트
...