자연어처리 Beam Search
텍스트 생성 문제에 대해서 Greedy Search와 Beam Search을 어떻게 사용하는지 How to Implement a Beam Search Decoder for Natural Language Processing블로그를 보고 정리
텍스트 생성을 위한 Decoder
캡션 생성, 요약, 기계 번역은 단어들의 연속을 예측한다. 이런 모델들의 출력은 각 단어들에 대해 사전크기의 확률 분포이다. 이 사전 크기의 확률 분포들은 문장속의 단어로 변환된다.
가장 가능성이 높은 출력 시퀀스를 디코딩하는 것은 그 가능성에 기초하여 가능한 모든 출력 시퀀스를 검색하는 것을 포함한다. 이때 vocab의 크기는 수백 수천, 수백만이 될때가 있다. 따라서
탐색문제는 출력 시퀀스에 지수적이기 때문에 완전히 탐색하기 어렵다. 그래서 휴리스틱 탐색 방법이 사용한다. 휴리스틱은 보다 근사적이거나 충분하게 디코딩된 출력 시퀀스를 반환한다.
단어들의 후보 시퀀스들은 그들의 우도(likelihood)에 따라 점수화 되고, 다음 텍스트를 예측하는 것에 Greedy Search와 Beam Search을 일반적으로 사용한다.
1. Greedy Seaerch Decoder
greedy search는 각 출력을 예측하는데 각 스텝에서 가장 가능성이 높은 단어를 선택한다.
장점
탐색하는데 매우 빠르다.
단점
최종 출력이 최적화된 결과에서 멀어진다.
예제
10개의 단어 시퀀스롤 포함하는 예측문제. 각단어는 다섯 단어의 어휘에 대한 확률 분포를 예측한다
데이터
# define a sequence of 10 words over a vocab of 5 words
data = [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1]]
data = array(data)각 단어들은 정수로 vocab에서 검색 가능하고, 따라서 디코딩 작업은 확률에서 정수 시퀀스를 선택하는 것이 된다.
argmax()는 배열에서 최대값을 갖는 인덱스를 반환해주고 numpy 배열에서 사용 가능하다.
greedy_decoder()는
argmax()함수를 이용한다
Greedy Decoder
# 그리디 디코더
def greedy_decoder(data):
# 각 데이터에서 가장 큰 값을 가지는 인덱스들의 배열을 반환
return [argmax(s) for s in data]전체 코드
from numpy import array
from numpy import argmax
# greedy decoder
def greedy_decoder(data):
# index for largest probability each row
return [argmax(s) for s in data]
# define a sequence of 10 words over a vocab of 5 words
data = [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1]]
data = array(data)
# decode sequence
result = greedy_decoder(data)
print(result)출력
[4, 0, 4, 0, 4, 0, 4, 0, 4, 0]
2. Beam Seaerch Decoder
그리디 탐색에서 확장된 빔 탐색이 많이 사용한다. 이것은 가장 높은 확률을 시퀀스를 반환한다.
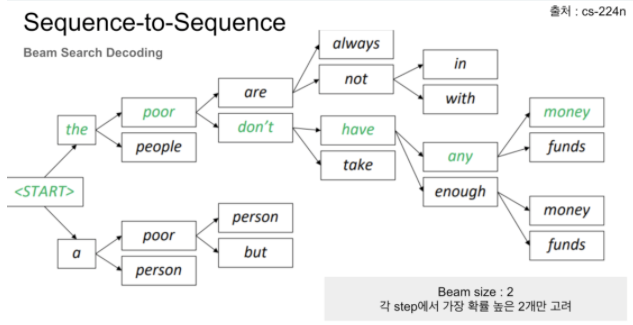
빔 탐색은 모든 가능한 다음 스텝들로 확장하고, 가 사용자 지정 파라미터 이고, 빔의 숫자 또는 확률 시퀀스에서 병렬 탐색들을 조절가능한 곳에서 가능한 를 유지하려고 한다.
그리디 탐색의 경우 빔이 1인 탐색과 같다. 빔의 수는 일반적으로 5 또는 10을 사용하고, 빔이 클수록 타겟 시퀀스가 맞을 확률이 높지만 디코딩 속도가 떨어지게 된다.
NMT에서 빔 탐색 디코더를 통해 문장을 번역하는것은 학습된 NMT 모델의 조건부 확률의 최대화하는 번역을 찾는것이다. 빔 탐색전략은 고정됨 숫자를 유지하면서 왼쪽->오른쪽으로 이동하면서 단어를 생성한다. 빔 크기를 증가시면 번역 성능은 높아지나 디코딩 속도는 떨어진다.
Beam Search Strategies for Neural Machine Translation, 2017
탐색 절차는 각 후보 단어들에 대해서 최대 길이에 도달할때 EOS 토큰에 도달하거나 임계값 우도에 도달할때 탐색을 개별적으로 멈출 수 있다.
2.1 구현
주어진 확률 시퀀스와 빔 크기 에 대해 빔 탐색을 수행하는 함수를 작성한다.
- 각 후보 시퀀스는 가능한한 모든 다음 스텝들에 대해 확장된다.
- 각 후보는 확률을 곱함으로써 점수가 매겨진다.
- 가장 확률이 높은 시퀀스가 선택되고, 다른 모든 후보들은 제거된다.
- 위 절차들을 시퀀스가 끝날때까지 반복한다.
확률을 숫자가 작은데, 작은 숫자끼리 곱하게 되면 매우 작은 숫자가 나오게 되어 언더플로우가 발생한다. 따라서 확률값에 자연로그 값을 취한 후에 곱해준다. 이런 방법은 숫자를 크고 다루기 편하게 유지해준다. 게다가 이 과정은 점수를 최소화 하면서 탐색을 수행한다. 확률의 네거티브 로그가 곱해지고, 이 마지막 수정은 우리가 모든 후보들에 대해 점수에 대해 오름차순으로 분류할 수 있다는 것을 의미하고 그리고 처음 를 가장 높은 확률의 후보자로 선택할 수 있다.
2.2 beam_search_decoder 함수
# beam search
def beam_search_decoder(data, k):
sequences = [[list(), 1.0]] # 빈리스트와 점수 1.0으로 초기화
# data에 대해서 반복
for row in data:
all_candidates = list()
#sequences만큼 순회
#최초에는 길이 1
for i in range(len(sequences)):
seq, score = sequences[i]
for j in range(len(row)): # data의 한 row 만큼 순회
candidate = [seq + [j], score * -log(row[j])] # [순서, 1.0 * -log(row의 j번째 요소)]
all_candidates.append(candidate) # 계산된 후보를 list에 삽입
# 후보들을 점수에 따라 정렬
ordered = sorted(all_candidates, key=lambda tup:tup[1])
# 그중에 k개를 반환
sequences = ordered[:k]
return sequences2.3 beam_search_decoder 전체
"""
source by https://machinelearningmastery.com/beam-search-decoder-natural-language-processing/
"""
from math import log
from numpy import array
from numpy import argmax
# beam search
def beam_search_decoder(data, k):
sequences = [[list(), 1.0]]
# walk over each step in sequence
for row in data:
all_candidates = list()
# expand each current candidate
for i in range(len(sequences)):
seq, score = sequences[i]
for j in range(len(row)):
candidate = [seq + [j], score * -log(row[j])]
all_candidates.append(candidate)
# order all candidates by score
ordered = sorted(all_candidates, key=lambda tup: tup[1])
# select k best
sequences = ordered[:k]
return sequences
# define a sequence of 10 words over a vocab of 5 words
data = [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1]]
data = array(data)
# decode sequence
result = beam_search_decoder(data, 3)
# print result
for seq in result:
print(seq)결과
[[4, 0, 4, 0, 4, 0, 4, 0, 4, 0], 0.025600863289563108]
[[4, 0, 4, 0, 4, 0, 4, 0, 4, 1], 0.03384250043584397]
[[4, 0, 4, 0, 4, 0, 4, 0, 3, 0], 0.03384250043584397]References
https://machinelearningmastery.com/beam-search-decoder-natural-language-processing/
