
이번 캡스톤 디자인 프로젝트에서 오브젝트 디텍션을 위해 사용할 모델인 Faster R-CNN을 사용하기 전, 관련내용에 대해 간단히 정리해보기로 했다.
Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks
Faster R-CNN
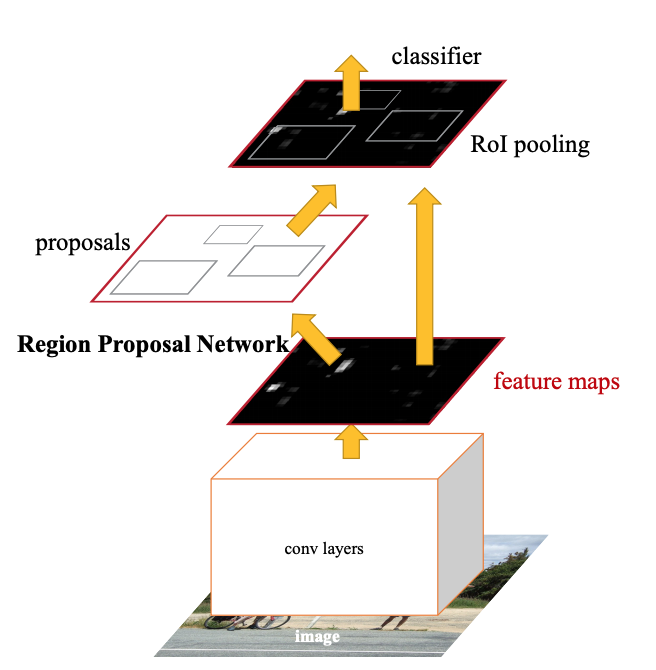
conv layer로부터 이미지가 feature map 생성
RPN에 넣음, fast rcnn에 오브젝트가 있을 것 같다는 제안을 하게 됨
RPN과 Fast RCNN이 convolutional Feature를 공유하도록 네트워크를 쌓음
아이디어
기존 Fast- RCNN에서는 ...
selective search 가 독립적으로 존재하므로, 이것에 대한 시간이 추가적으로 걸리게 되었다.
그래서 Faster RCNN 에서는 ...
- convolutional feature map이 Region Proposal에서도 쓰이도록 함
- conv layer에 새로운 layer를 쌓아서 region proposal 과 regression , objectness score 계산을 함께 하도록 함
selective search를 대체함으로써 proposal에 10 m/s 소요 -> 매우 빨라짐
Faster Rcnn train 과정
https://towardsdatascience.com/faster-r-cnn-for-object-detection-a-technical-summary-474c5b857b46
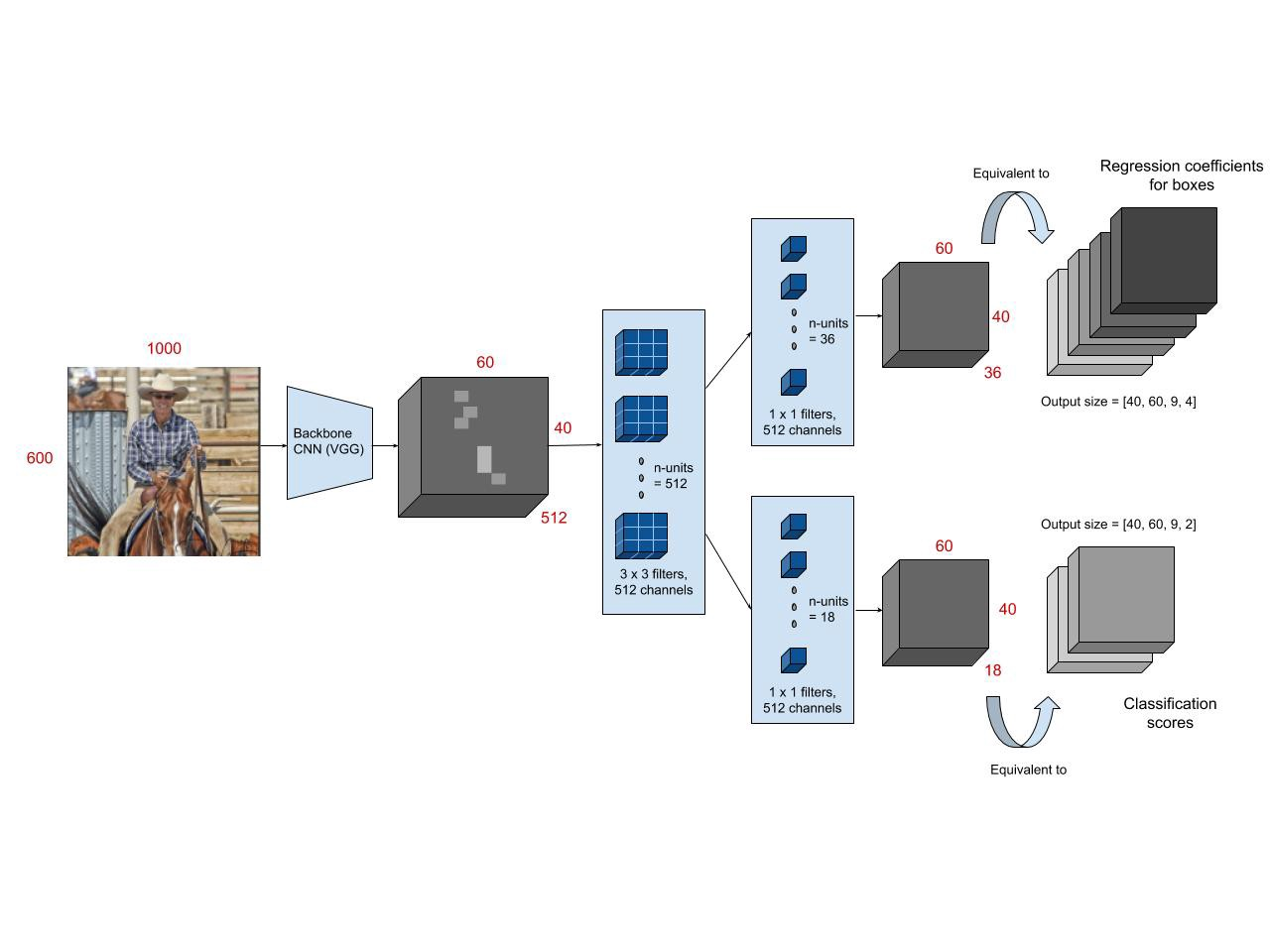
input 이미지 - conv layers (VGG- 16)에 패스 - feature map 생성
3x3 sliding window적용 (intermediate layer)시켜 같은 크기의 feature map 생성
1x1 feature map은 하나의 convolutional network 해당위치의 지역적 특성을 축약한 것
여기까지가 RPN학습의 베이스
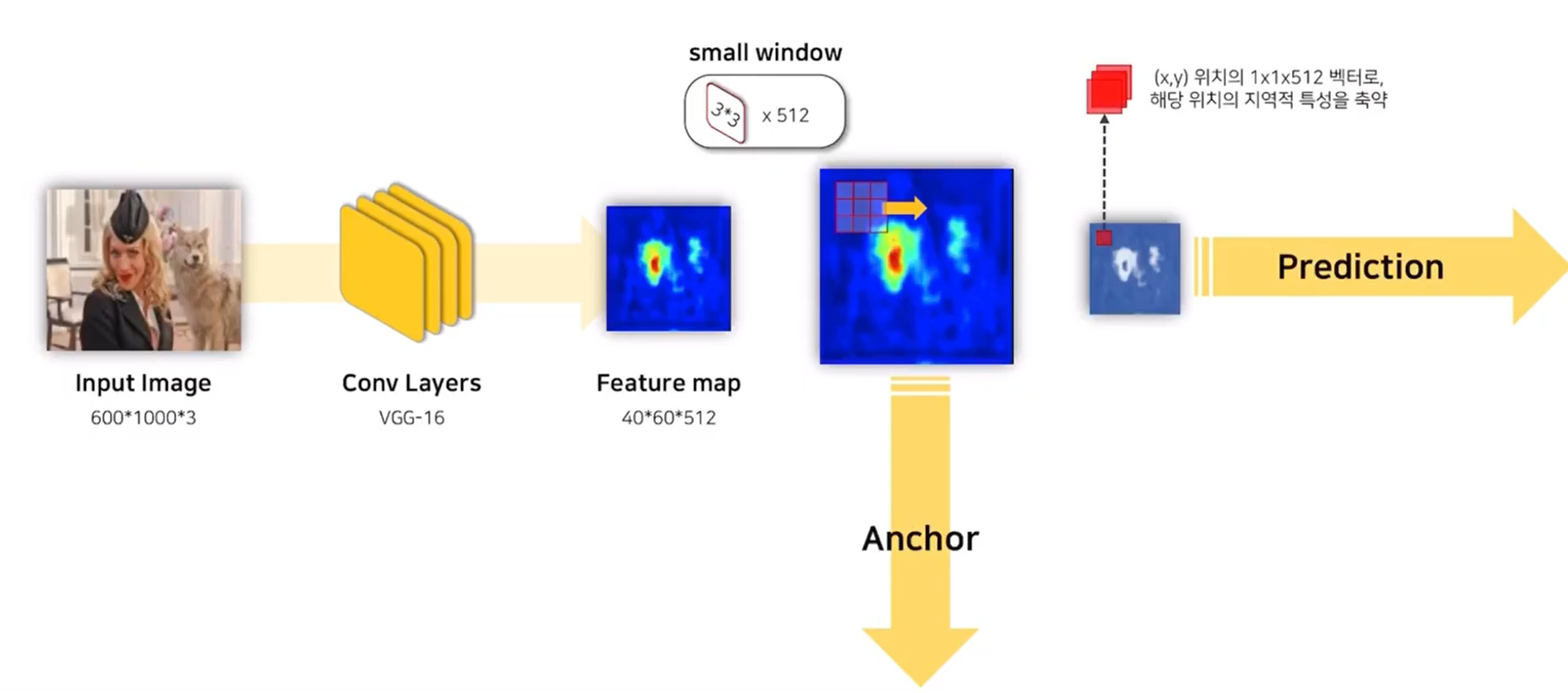
이후 anchor 와 prodiction 과정으로 나뉘게 된다.
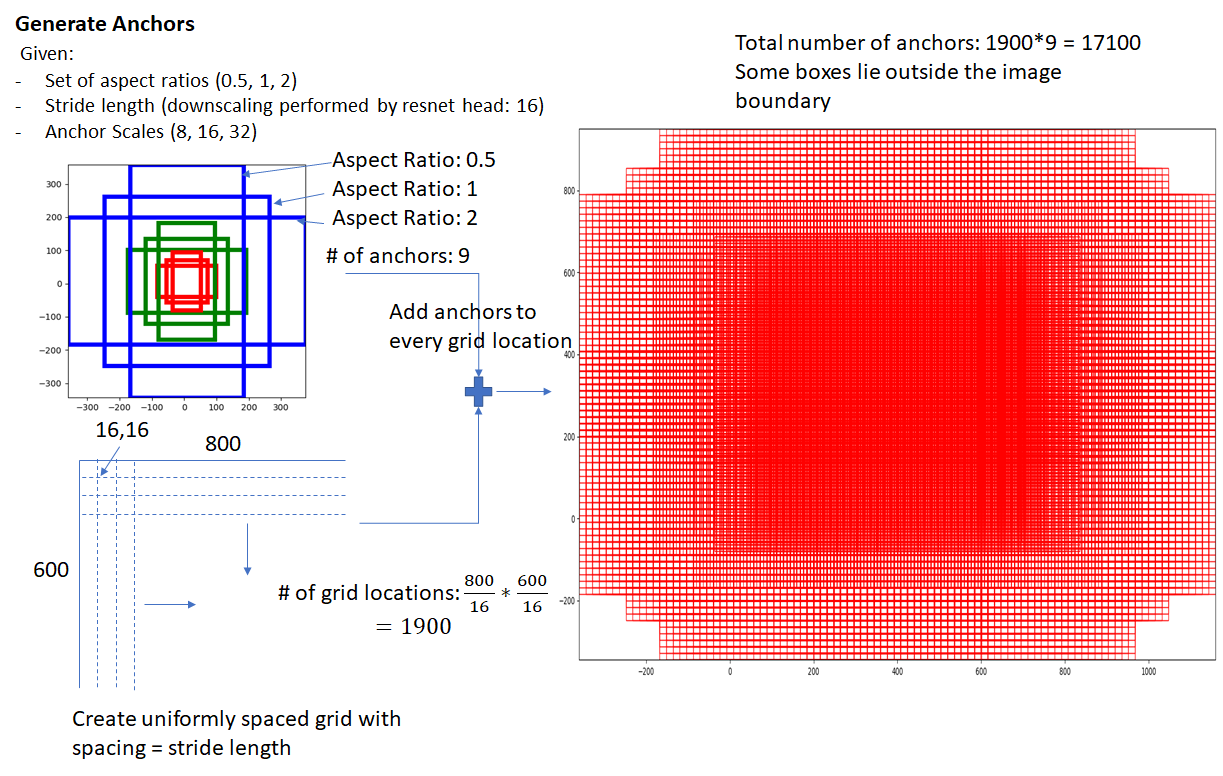
Anchor 3x3 적용할 때 중앙에 있는 것 anchor.
모든 anchor별로 k개의 앵커 박스 생성 - scale x ratio
Anchor labeling - Objectness Labeling
앵커박스인에 실제 object가 있는 지를 판단한다.
IoU를 기준으로
0.7이상 positive
0.3이하 negative
0.3~0.7이거나 이미지 경계 벗어난 경우 invalid
Bbox offset labeling
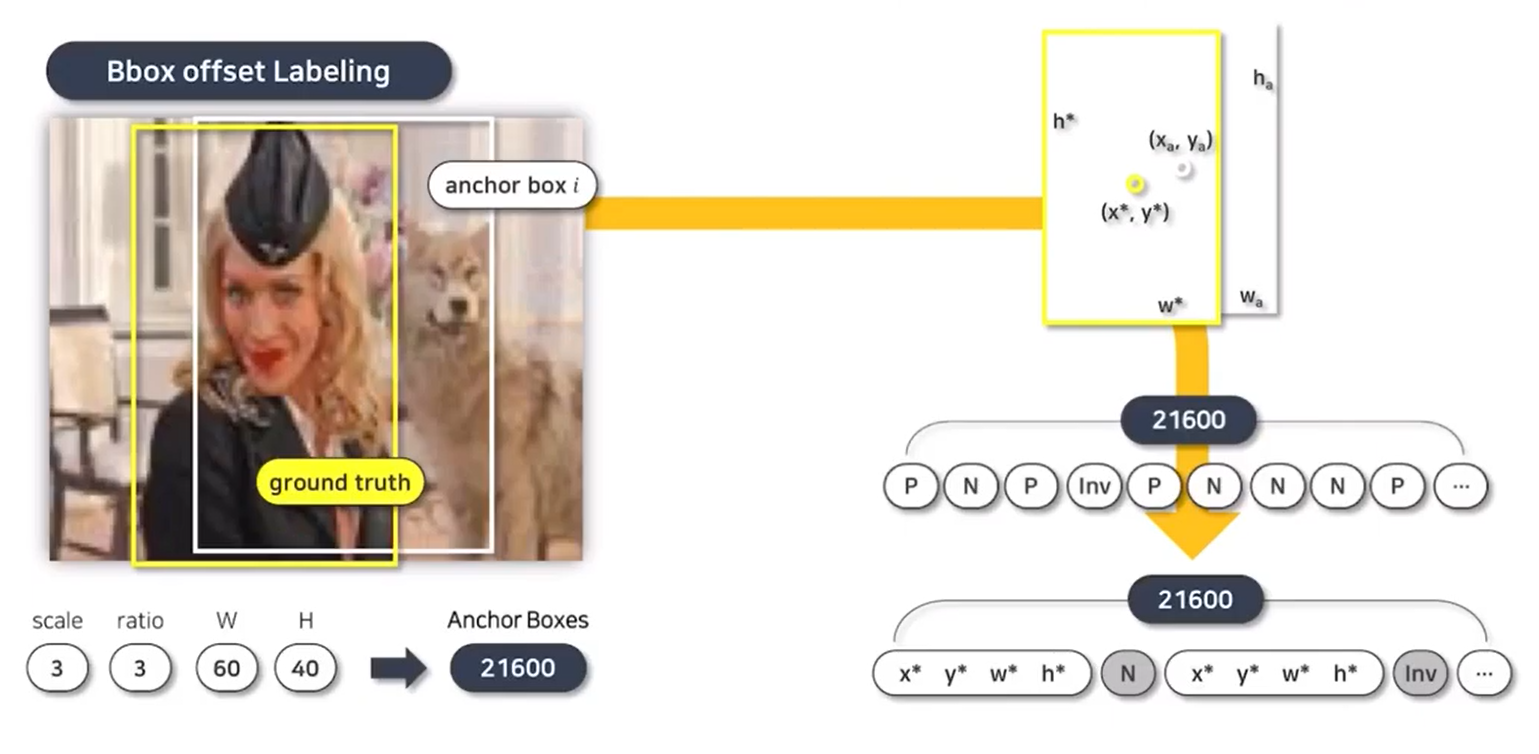
앵커박스에 해당하는 ground truth와의 위치적 관계를 labeling
anchor box의 위치적 offset으로 설정
Prediction network
오브젝트가 여기에 있을 것 같다는 것에 대한 네트워크
classification
여기에 오브젝트가 있다 없다 판단, 모든 픽셀에 대해 앵커 박스들의 오브젝트가 있을 확률을 담는다.
regression
모든 픽셀에 대해 앵커박스가 예측하는 오브젝트의 위치 저장한다.
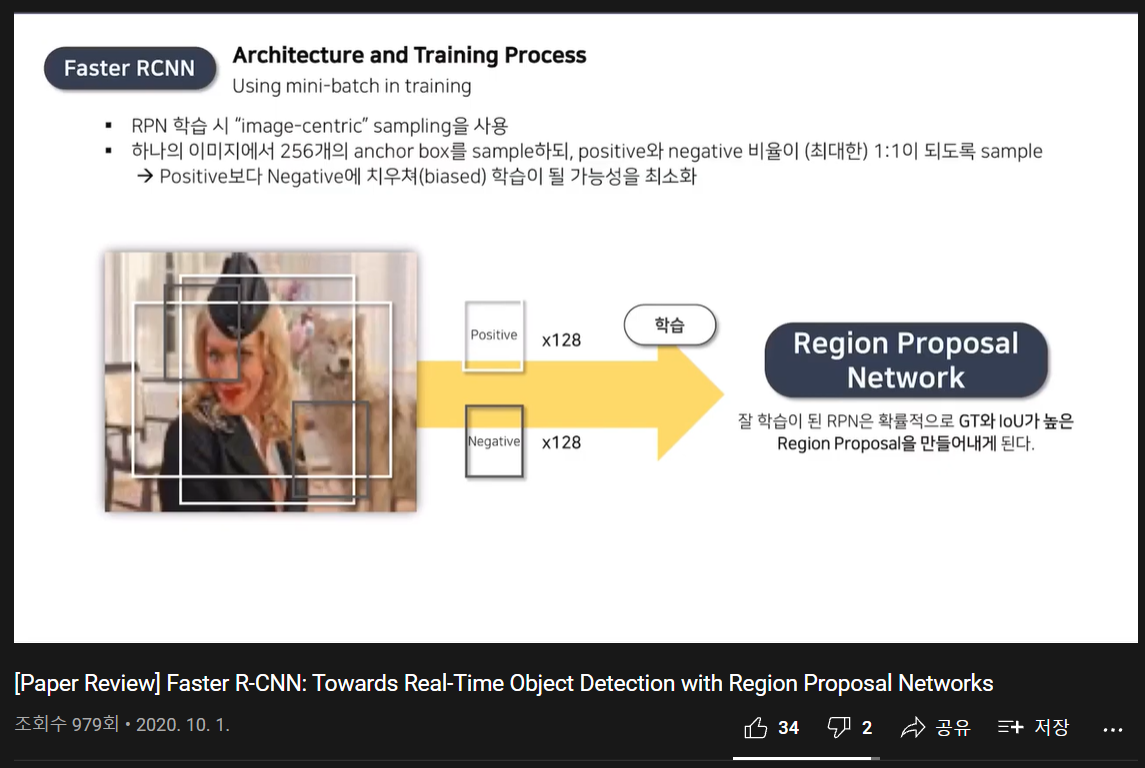
최종적으로 sampling된 p, n 와 loss function 학습
-> 확률적으로 GT와 IoU가 높은 RP를 만들어냄
학습 과정
RPN학습 -> 여러 proposal 생성
proposal로 Fast RCNN 학습, 초기화된 CNN다시 사용
-> fine tuning
-> 파인튜닝된 프리트레인 네트워크 생성
-> 학습된 이 네트워크를 사용하여 rpn 학습
-> 여기서 부터 conv layer 공유
-> 다시 proposal
-> 파인튜닝
-> 반복
