
이전 포스팅 >> Ch1. 데이터 수집 및 증강
1. 데이터 준비
1-1. 데이터 수집

ch1에서 수집한 데이터와 별개로, 배경이 포함된 이미지를 수집해야 했습니다. 같은 환경에서 제가 모두 이미지를 촬영하게 되는 것 보다 다른 환경에서 촬영한 이미지로 학습하면 더 유연하게 예측이 이뤄질 것이기 때문에 지인들에게 촬영을 부탁했습니다. 총 62장의 이미지를 수집했습니다. 촬영된 이미지는 수학시험지로 한정하지 않았고, 토익문제지, 에이포용지 필기, 자격증 시험 문제집 등 다양했습니다.
1-2. 데이터 라벨링
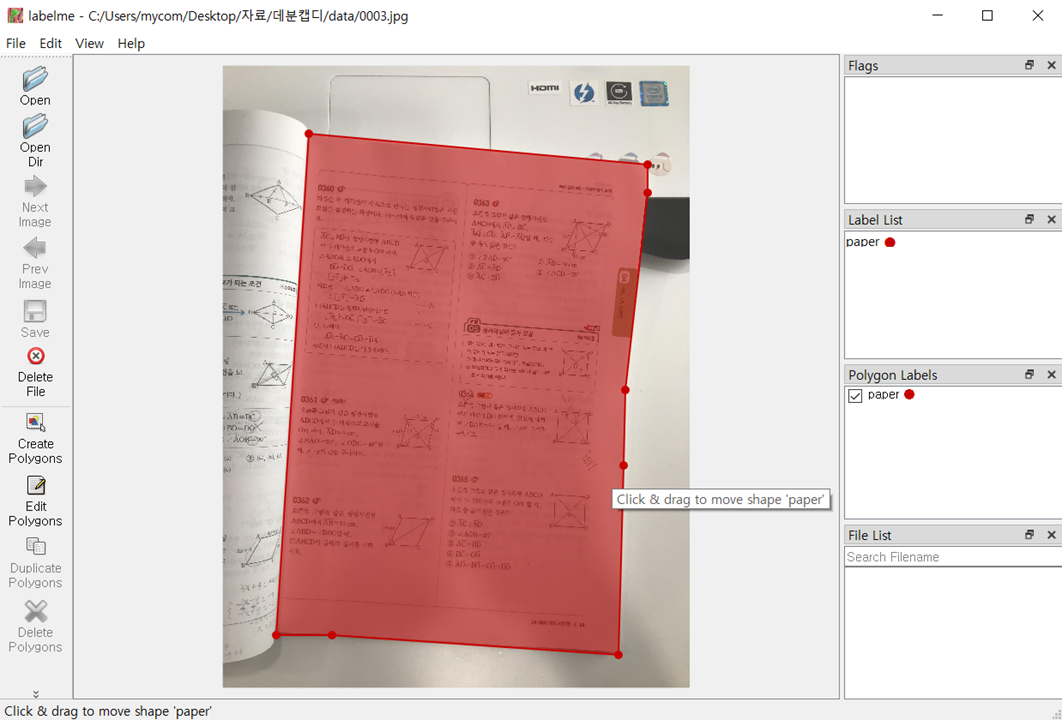
수집된 이미지를 직접 라벨링했습니다. 배경과 분리해야할 시험지 범위를 모양대로 잘라 라벨링했으며, class 이름은 paper 로 지정하였습니다. 저는 LabelMe 툴을 사용했으며, 설치 과정은 블로그를 참고했습니다.
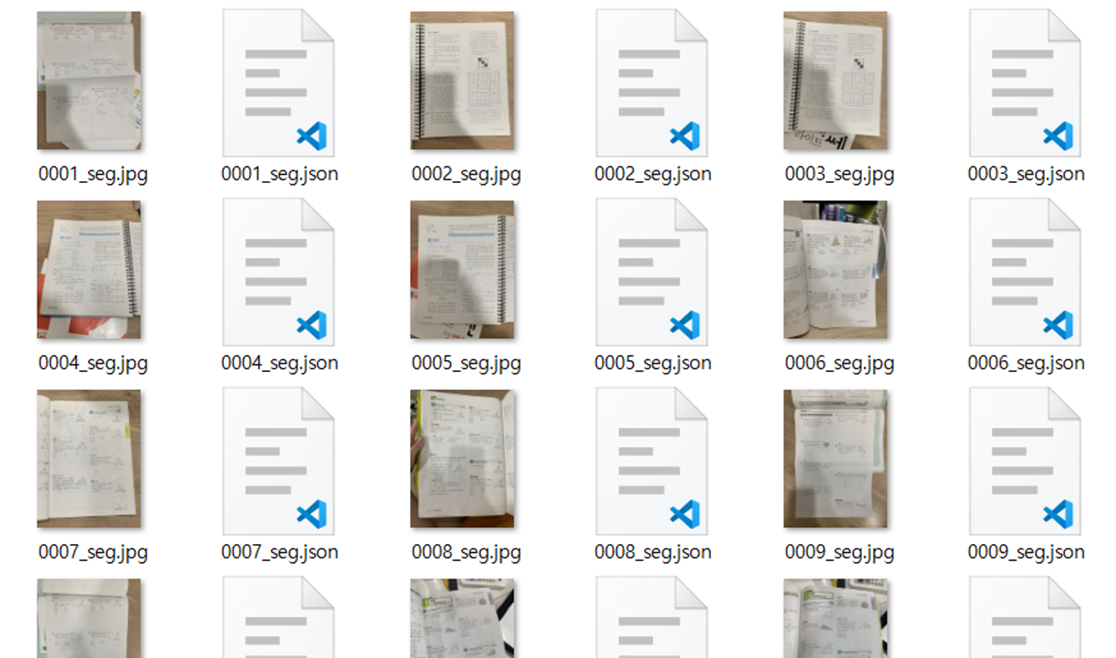
라벨링 후 json 파일로 각각 저장했습니다.
2. Mask R-CNN 학습 / 예측
2-1. 라이브러리 설치
저는 Detectron2 라이브러리를 사용하기 위해 먼저 Torchvision을 설치했습니다.
# torchvision 설치
!pip install -U torch torchvision
!pip install git+https://github.com/facebookresearch/fvcore.git
import torch, torchvision
torch.__version__torchvision 설치 후 Detectron2를 설치해주었습니다.
# detectron2 original repo clone
%cd /content/drive/My Drive/test-paper detector/detectron2
!git clone https://github.com/facebookresearch/detectron2 detectron2_repo
!pip install -e detectron2_repo2-2. 객체 추가
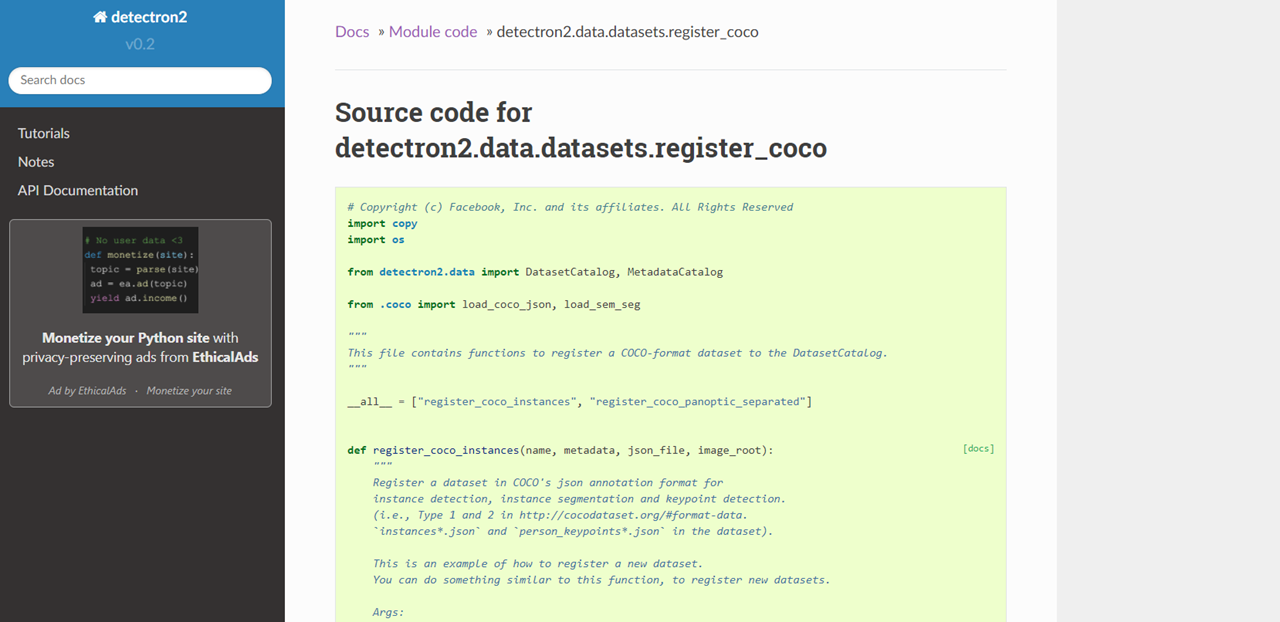
그 다음, detectron2에서 제공되는 객체들에서 추가로 제가 설정한 시험지 객체를 추가하기 위해 register_coco_instances()
함수를 사용해 "test-paper"라는 객체를 추가했습니다.
# coco 데이터셋에 paper 객체instance를 추가
from detectron2.data.datasets import register_coco_instances
#register_coco_instances("test-paper", {}, "./data/trainval.json", "./data/segmentation_images")
paper_metadata = MetadataCatalog.get("test-paper")
dataset_dicts = DatasetCatalog.get("test-paper")이때, train data set의 통합 json 파일이 필요하며, 원본이미지를 함께 등록해야합니다.
추가 후 아래 코드를 통해 라벨링 상태를 시각화하여 확인해볼 수 있습니다.
import random
for d in random.sample(dataset_dicts, 3):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=paper_metadata, scale=0.5)
vis = visualizer.draw_dataset_dict(d)
cv2_imshow(vis.get_image()[:, :, ::-1])
2-3. 모델 학습
저는 수집한 62장의 이미지 중 test set 7장을 제외한 총 55장을 학습하였습니다.
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
import os
cfg = get_cfg()
cfg.merge_from_file("./detectron2_repo/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
cfg.DATASETS.TRAIN = ("test-paper",)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = "detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl"
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.02
cfg.SOLVER.MAX_ITER = 300
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()Detectron2에서 제공하는 미리 학습된 Mask-RCNN모델을 불러와 사용해 주었습니다. 탐지하고자 하는 test-paper 객체만 예측하도록 하기 위해 NUM_CLASSES 는 1로 설정해주었습니다.

2-4. 예측 결과
제외해두었던 7장으로 모두 테스트 해보았습니다.

색으로 칠해진부분이 모델을 통해 예측된 segmentation 이미지 입니다. 적은 데이터 개수로 학습을 진행했지만 미리 학습된 모델이라 결과는 생각보다 잘 나온 것 같습니다. 프로젝트를 진행하며 모델에 대한 데이터 셋은 더 추가할 예정입니다.
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
cfg.MODEL.WEIGHTS = "/content/drive/My Drive/test-paper detector/detectron2/output/model_final.pth"
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.DATASETS.TEST = ("test-paper", )
predictor = DefaultPredictor(cfg)
path = "/content/drive/My Drive/test-paper detector/detectron2/data/segmentation_images/test/0062_seg.jpg"
im = cv2.imread(path)
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])3. segmentation mask 자르기
이제 원본이미지를 예측된 segmentation mask를 따라 잘라보겠습니다. 이 과정은 실제 데이터를 입력했을 때 배경과 시험지를 잘라 정확도를 더 높이기 위한 과정입니다.

위 이미지는 test set 7장 중 하나이며, 오른쪽 사진은 segmentation 예측 결과입니다. segmentation 결과는 mask 행렬로서 output 객체에 저장됩니다. 따라서 저는 이 mask 행렬을 활용하여 이미지를 잘라보았습니다.
import matplotlib.pyplot as plt
from matplotlib import cm
ins = outputs["instances"]
pred_masks = ins.get_fields()["pred_masks"]
#boxes = ins.get_fields()["pred_boxes"]
pred_masksoutputs의 "instances"가 존재합니다. 그 속에는 예측된 마스크 행렬을 포함하는 pred_masks와, 대상 객체가 존재하는 위치를 저장해둔 pred_boxes가 있습니다. 저는 pred_masks을 불러왔습니다.
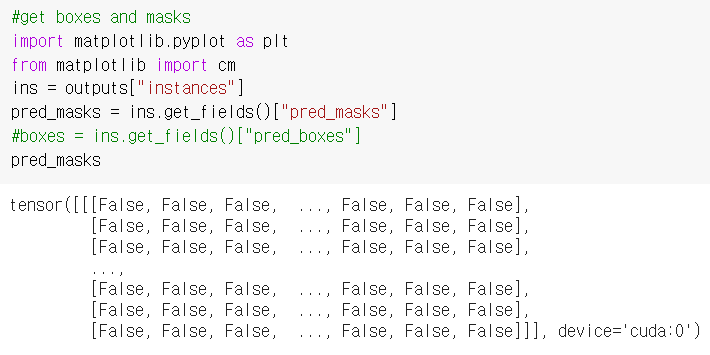
그 속에는 False와 True로 가득찬 행렬이 존재하고 tensor 타입 행렬을 numpy로 우선 바꾸어 주었습니다.
## tensor to numpy
mask_array = pred_masks.cpu().numpy()그 다음, numpy 행렬을 이미지로 바꾸기 위해 fromarray 함수를 사용하게 되면 아래와 같은 마스크 이미지가 도출됩니다.
## numpy to image
mask = Image.fromarray(mask_array[0])
이 마스크 이미지를 가지고 bitwise_or 연산을 시행해줍니다. 시행 전
img = 255-img
을 통해 이미지 반전을 해주고,
img = (img*1).astype('uint8')
masked = cv2.bitwise_or(img,im)원본이미지와 마스크 이미지 bitwise_or 연산을 시행하면, 원본이미지에서 마스크이미지가 잘려진 형태의 이미지가 저장됩니다.

이제 이 이미지를 가지고 더 높은 정확도의 예측이 추후에 가능하게 되었습니다.
사용한 모든 코드는 깃허브에 업로드하였습니다.
감사합니다.
