1 인스타 웹크롤링을 위한 준비
1-1 셀레니움, 크롬드라이버 설치하기
우선 셀레니움, 크롬드라이버를 통해 인스타 속 클래스를 뽑아내야 한다.

처음 써보는 selenium 이었지만 이미 설치는 되어있었다.
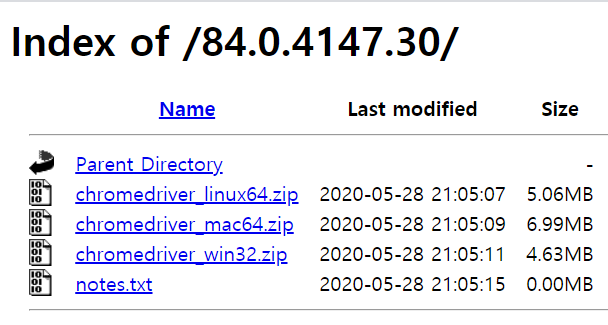
그리고 chromedriver를 설치한다. 본인의 크롬 버전을 잘 확인한 후 같은 버전으로 설치해야만 한다.
1-2 인스타그램 게시물의 클래스 확인하기

인스타그램 피드에서, 3줄에 하나의 클래스로 묶여있었다.
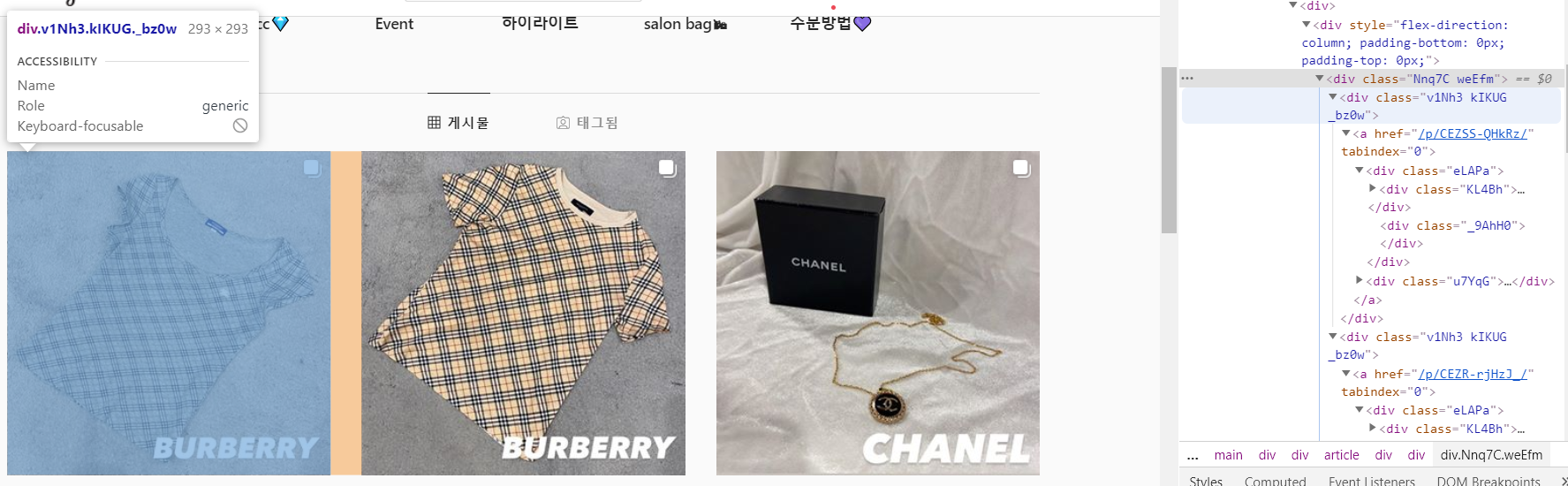
또 그안에서 하나의 게시물만 가리키는 클래스가 존재했다.
.v1Nh3. 뒷부분을 생략해도 된다고 한다.

그리고 .KL4Bh 클래스 속 src 에 해당하는 이미지 링크를 확인할 수 있었다. 게시글의 첫번째에 해당한다.
이것은 모든 사진에 포함되어 있으므로 for 문으로 여러장을 저장하는 데 이용할 수 있다.
html = driver.page_source
soup = BeautifulSoup(html)
insta = soup.select('.v1Nh3.kIKUG._bz0w')
#print(insta[0])
n = 1
for i in insta:
print('https://www.instagram.com'+i.a['href'])
imgUrl = i.select_one('.KL4Bh').img['src']
with urlopen(imgUrl) as f:
with open('./clothes_img/' + id_Input + str(n) + '.jpg', 'wb') as h:
img = f.read()
h.write(img)
n += 1
print(imgUrl)
print()먼저 driver를 통해 특정 id 의 인스타그램 링크를 가져온 상태이다.
insta = soup.select('.v1Nh3.kIKUG._bz0w')
각각의 게시글에 존재하는 클래스를 insta 에 저장한다.
imgUrl = i.select_one('.KL4Bh').img['src']
그리고 차례대로 첫번째 게시글부터 마지막 게시글까지 돌아가며 이미지 url을 저장한다.
저장된 url 에서 특정폴더에 특정 이름으로 저장하게 된다.

print('https://www.instagram.com'+i.a['href'])
하나의 게시글 링크를 각각 보여주고 싶다면 href 클래스를 이용한다.

1-3 사용코드
2 무한 스크롤 내리기
2-1 스크롤 내리기
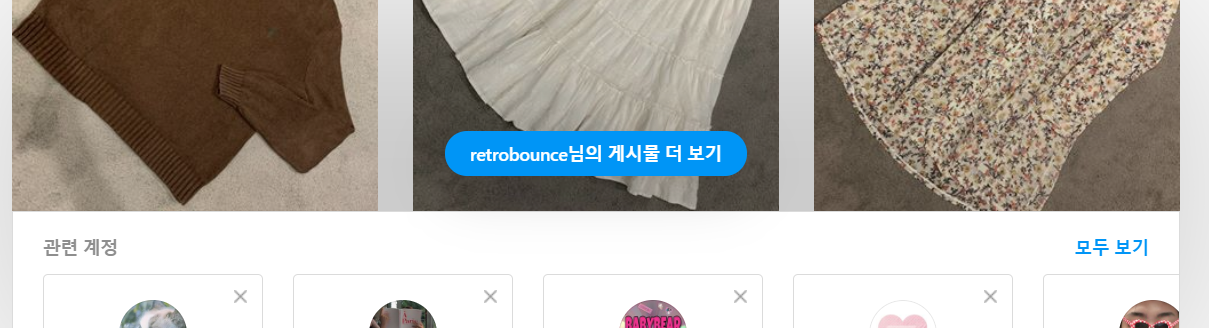
이전 까지는 처음 계정 url 에 접속하여 스크롤 하기전에 뜨는 사진이 12개라서 12개의 사진만 불러올 수 있었다.
그래서 스크롤 후의 사진도 여러장 불러올 방법을 찾아야했다.
위 사진처럼 초기화면 젤 아래에 있는 더 보기를 누른 후 무한 스크롤 진행해야한다.
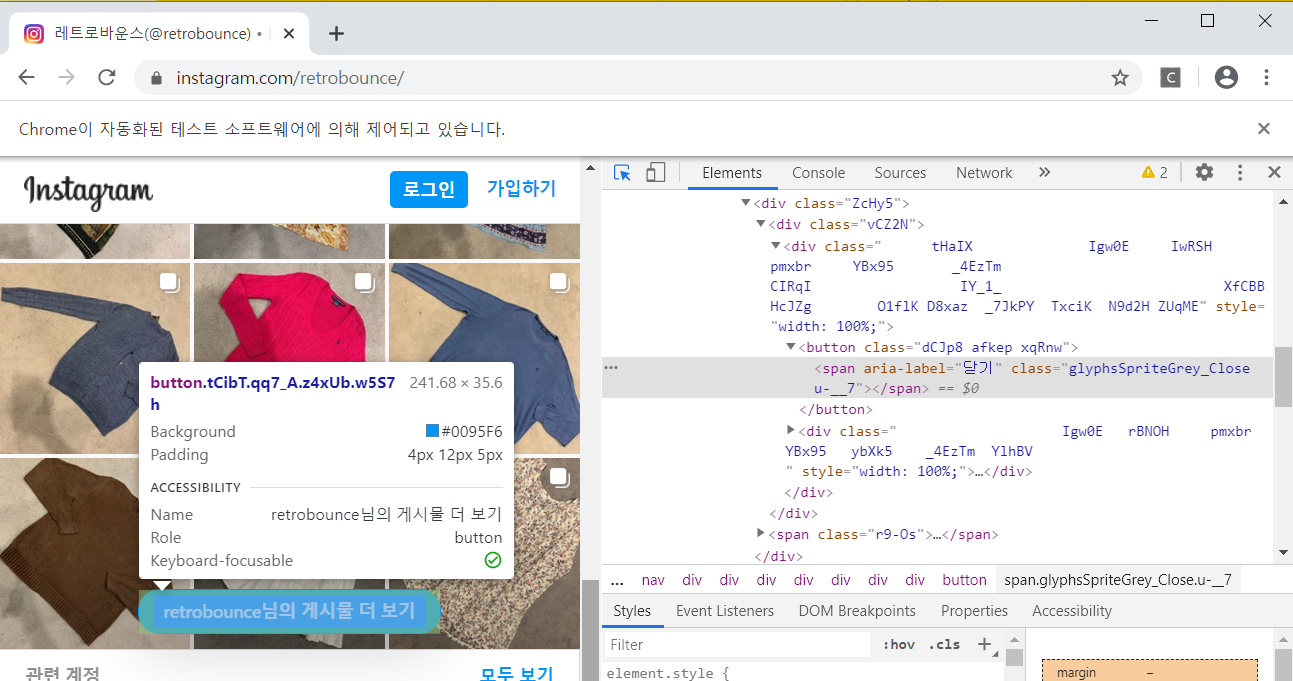
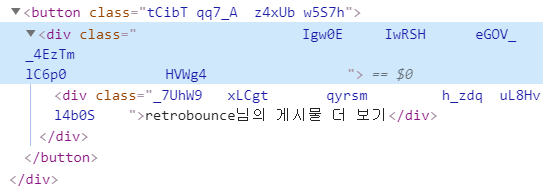

아래에 있는 <게시물 더보기> 라는 버튼을 누르기 위해 전전긍긍하던 중
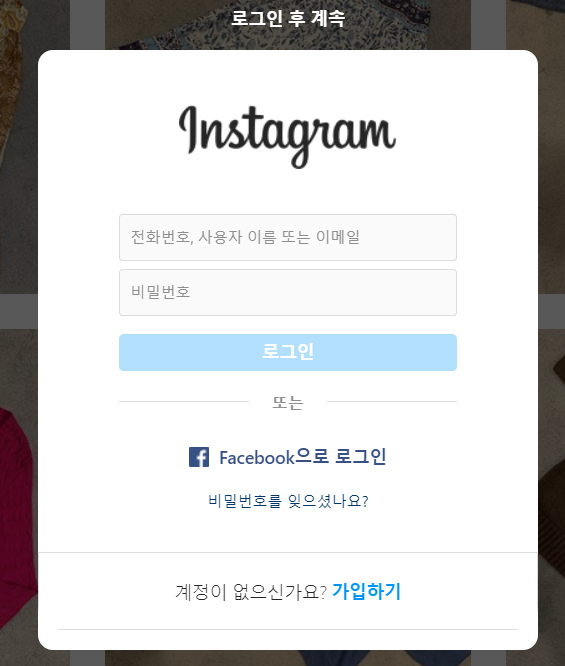
로그인을 하지 않으면 위와 같은 창이 뜨면서 스크롤이 더이상 안된다는 것을 알게되었다. 그래서 로그인을 먼저 하고, 무한 스크롤내리기를 진행하기로 판단했다.
2-2 로그인하기
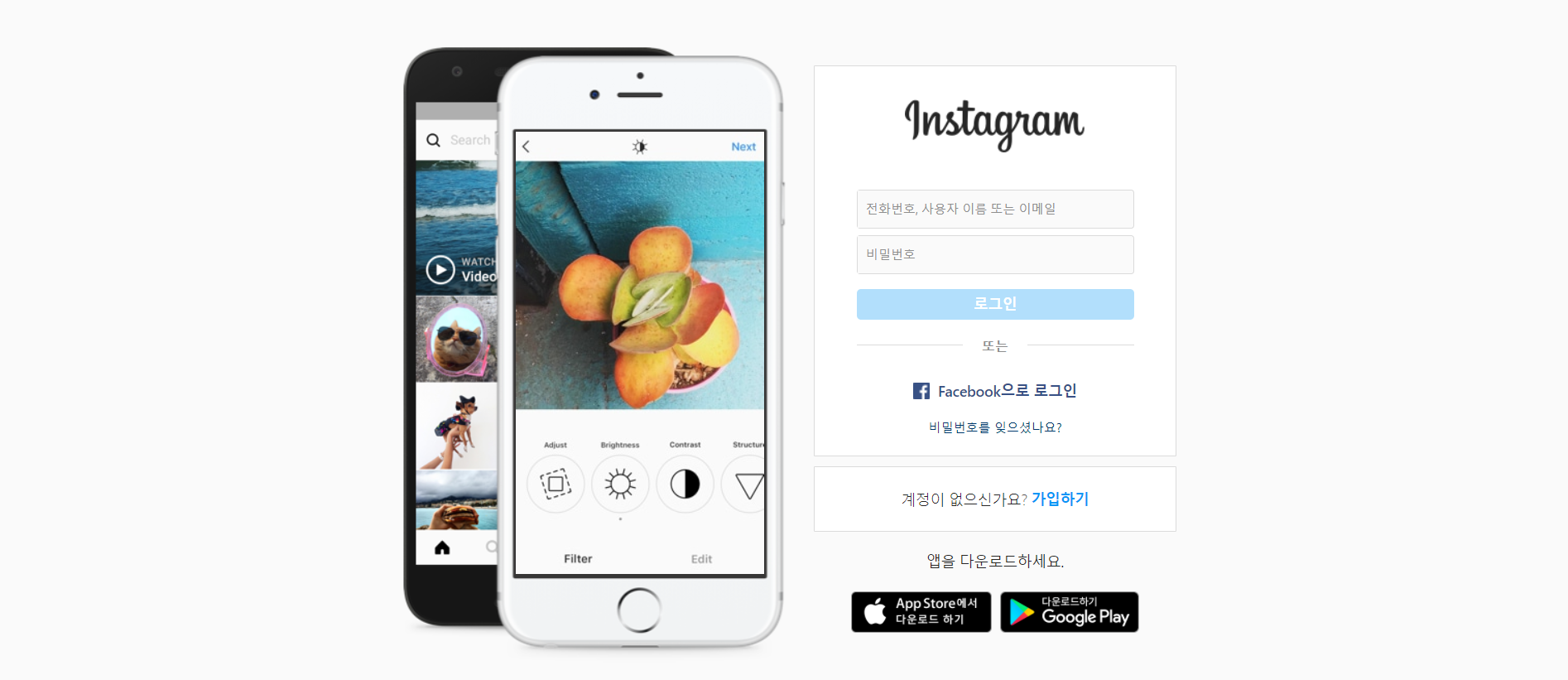
먼저 https://www.instagram.com/ 의 메인화면이다. 이 화면에서 id 와 password의 elements 를 webdriver로 불러온 후 입력값을 채울 계획이다.
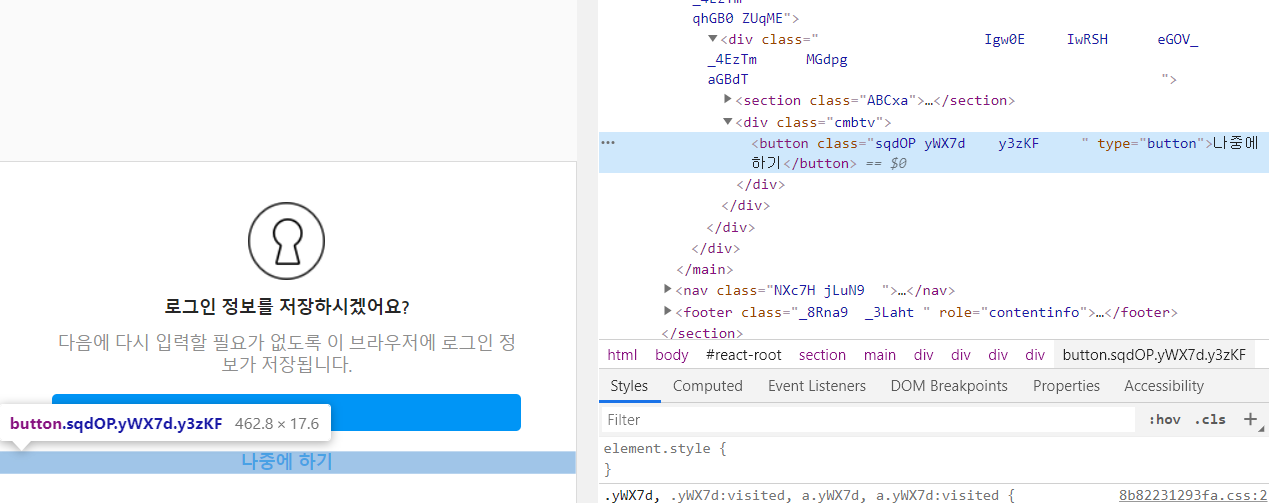
위 사진과 같이 나는 총 네가지 버튼과 입력창의 xpath 를 확인했다.
아이디 입력창
패스워드 입력창
로그인 버튼
로그인 후 로그인정보를 저장하지 않겠다는 버튼
driver.find_element_by_xpath 로 각각의 xpath를 불러와 원하는 입력값을 넣는다.

그다음 원하는 url을 불러오면 스크롤을 계속해서 할 수 있는 상태가 된다.
2-3 사용코드
