시작하기
케라스를 이용하여 간단하게 무언가를 분류하는 예제를 다루어 보고 싶은데, 이를 하기 위해서 그전에 신경망을 만들어보는, 즉 모델을 학습 시켜보는 실습을 해보았다.
mnist 데이터셋을 이용하였다.
x_train : 손글씨 숫자 이미지 대입
y_train : 이미지가 의미하는 숫자 대입
-> 데이터의 갯수 60000개, 모델을 학습할때 사용
x_test : 손글씨 숫자 이미지 대입
y_test : 이미지가 의미하는 숫자 대입
-> 데이터의 갯수 10000개, 모델의 예층 정확도 평가시 사용
사용코드
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 모델 학습시 훈련 데이터셋, 모델 예측 정확도 평가시 테스트 데이터셋
# 모델의 출력이 y_train에 있는 대응하는 숫자가 되도록 모델을 학습
# x_test 를 입력으로 제공시 y_test 가 출력되는지로 모델 평가
x_train, x_test = x_train/255.0, x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape = (28, 28)), # 크기 28 x 28 의 배열을 입력으로 받아 1차원 배열로 변환
tf.keras.layers.Dense(128, activation = 'relu'), # 히든레이어의 노드개수는 128개, 활성화 함수로 relu 사용
tf.keras.layers.Dropout(0.2), # 오버피팅 방지, 이전레이어의 출력을 20% 끈다
tf.keras.layers.Dense(10, activation = 'softmax') # 출력레이어의 노드개수는 10개, 활성화 함수는 softmax
])
model.compile(
optimizer = 'adam',
loss = 'sparse_categorical_crossentropy', # 손실함수로 크로스 엔트로피
metrics = ['accuracy'] # 메트릭은 모델을 평가할때 사용 , 정확도
)
model.fit(x_train, y_train, epochs = 5) # 모델 5번 반복 훈련
model.evaluate(x_test, y_test, verbose = 2) # 테스트 데이터셋으로 모델 평가
코드설명
x_train, x_test = x_train/255.0, x_test/255.0
손글씨 숫자 이미지 데이터는 0 - 255 사이의 값을 가진다.
모델 훈련에 사용하기 전에 0-1 사이 범위를 갖도록 변경한다!
.
model = tf.keras.models.Sequential([])
레이어를 쌓아서 keras.models.Sequential 모델을 생성한다.
.
tf.keras.layers.Dense(10, activation = 'softmax')
softmax 를 이용하면 출력값 간의 편차가 커져서 분류하기 쉽게 된다.
.
model.fit(x_train, y_train, epochs = 5)
훈련 데이터 셋을 사용하고, epochs를 5로 설정하여 모델을 5번 반복하여 훈력한다.
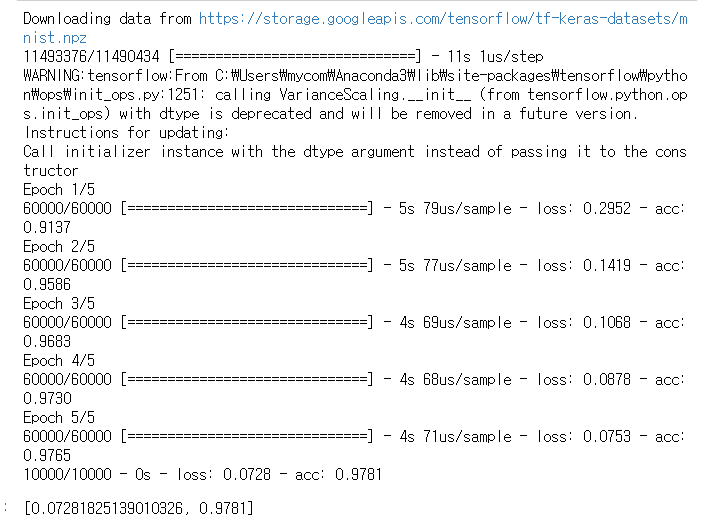
결과
진행할수록 손실은 적어지고 정확도는 높아진다.
.
.

Data Science / Computer Vision