손실함수
타켓의 실제값과 도출한 예측값의 차이를 수치화해주는 함수이다. 오차가 클수록 손실함수의 값이 크고, 오차가 작을수록 손실함수의 값이 작아진다. 그래서 모델성능의 '나쁨'의 정도를 나타낼 수 있다.
손실함수의 값(loss)을 최소화하는 W(가중치), b를 찾아가는 것이 학습 목표이다.
손실함수의 종류
평균 제곱오차(Mean Squared Error, MSE)

실제 정답에 대한 정답률의 오차뿐 아니라, 다른 오답에 대한 정답률의 오차도 포함하여 계산해준다. 최적값에 가까워질수록 이동값이 다르게 변화하기 때문에 최적값에 수렴하기 용이하다.
값을 제곱하기 때문에 절댓값이 1미만인 값은 더 작아지고, 1보다 큰 값은 더 커지는 왜곡이 발생할 수 있다.
평균 절대값오차(Mean Absolute Error, MAE)
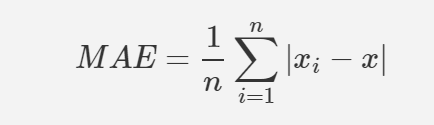
어떤식으로 오차가 발생했는지, 음수인지 양수인지 알 수없다.
최적값에 가까워져도 이동거리가 항상 일정하기 때문에 최적값에 수렴하기가 어렵다.
그렇지만 MAE는 MSE에 비해 outlier의 영향을 적게 받는다. MSE는 이상치가 멀리떨어져 있을 수록 제곱하여 그 값을 크게 만들지만, MAE는 절대값을 취하기 때문이다.
크로스 엔트로피(Cross-Entropy)
크로스 엔트로피는 카테고리컬 데이터를 분류할 때 주로 사용된다.
엔트로피란?
사건 A를 반복 실행했을 때, 얻을 수 있는 평균정보량
발생활 확률이 클수록, A사건에 대해 발생할 정보량이 작아진다. 반대로, 엔트로피가 크다는 것은 예측하기가 어려운 사건일수록 정보량이 많아지고, 엔트로피가 커지게 된다.
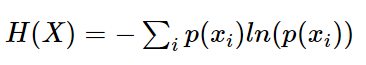
크로스 엔트로피 오차(Cross Entropy Error, CEE)
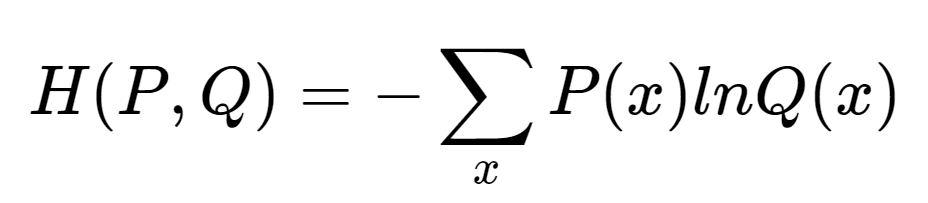
엔트로피 공식을 기반으로, 각 사건이 발생할 확률이 몇가지 인지에 따라 공식은 조금씩 바뀐다.
Q(x)는 신경망의 출력값, P(x)는 정답 레이블인데, 정답레이블은 정답만 1이고, 나머지는 0인 onehot 벡터를 사용한다.
P(x)는 원핫벡터이기 때문에, 정답1이 있는 위치만 1 * InQ(m) 으로 나오게 되고 나머지는 0으로 도출되어 정답위치에 해당하는 값이 CEE로 출력된다.
정보량이 0에 가까워져 발생확률이 1에 가깝게 만드는 것을 목적으로 한다.
이진 크로스 엔트로피 오차(Binary Cross Entropy Error, BCEE)
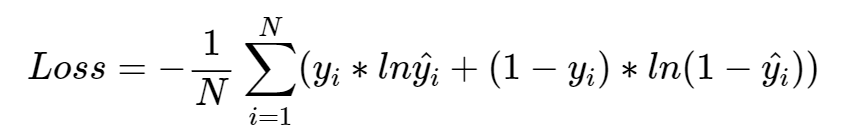
교차엔트로피는 분류할 클래스가 2보다 클 때 사용할 수 있지만, 이진 크로스엔트로피 오차는 클래스가 0과 1일때만 고려하여 계산하는 방식이다.
y_hat은 예측값이고, y는 실제값이다.
유도과정
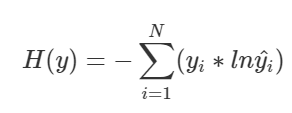
y=0의 CEE 공식
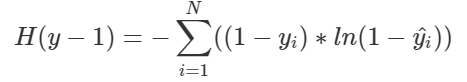
y=1의 CEE 공식
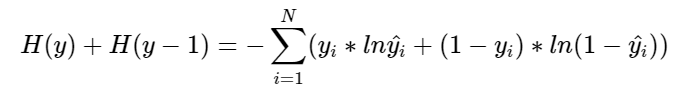
합침
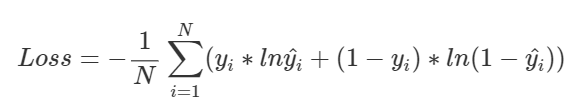
N개의 학습데이터 전체에 대한 교차엔트로피를 구하는 공식(평균)이다.
BCEE는 출력층의 노드 수를 하나로 하여 출력값을 하나로 받기때문에, 실제값과 예측값 모두 하나의 스칼라 값이다.

범주형 크로스 엔트로피 오차(Categorical Cross Entropy Error, CCEE)
클래스가 3개 이상인 데이터를 대상으로 사용하는 손실함수이고, 타겟 라벨은 원핫벡터로 구성, 출력된 벡터는 각 클래스에 속할 총합1인 확률로 나온다.
CEE를 N개의 데이터셋에 대해 1개의 스칼라를 추출하는 방법이다.
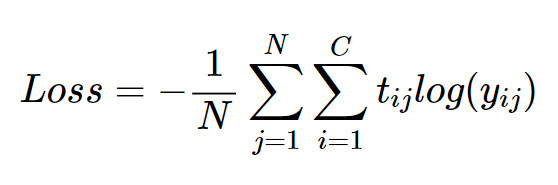
데이터셋 개수 N, 클래스 개수 C
각각의 데이터셋에서 도출된 CEE 구하고, 평균을 구하는 방식
5개의 클래스에 대해 원핫벡터로 표현된 label들, 각 데이터셋에서 도출된 예측값 predict, 각 데이터 셋에서의 CEE를 구하고, 이를 합쳐 평균으로 나타낸 CCEE
https://gooopy.tistory.com/65?category=824281
