딥러닝을 위한 공부
1.[딥러닝 기초개념] 활성화 함수
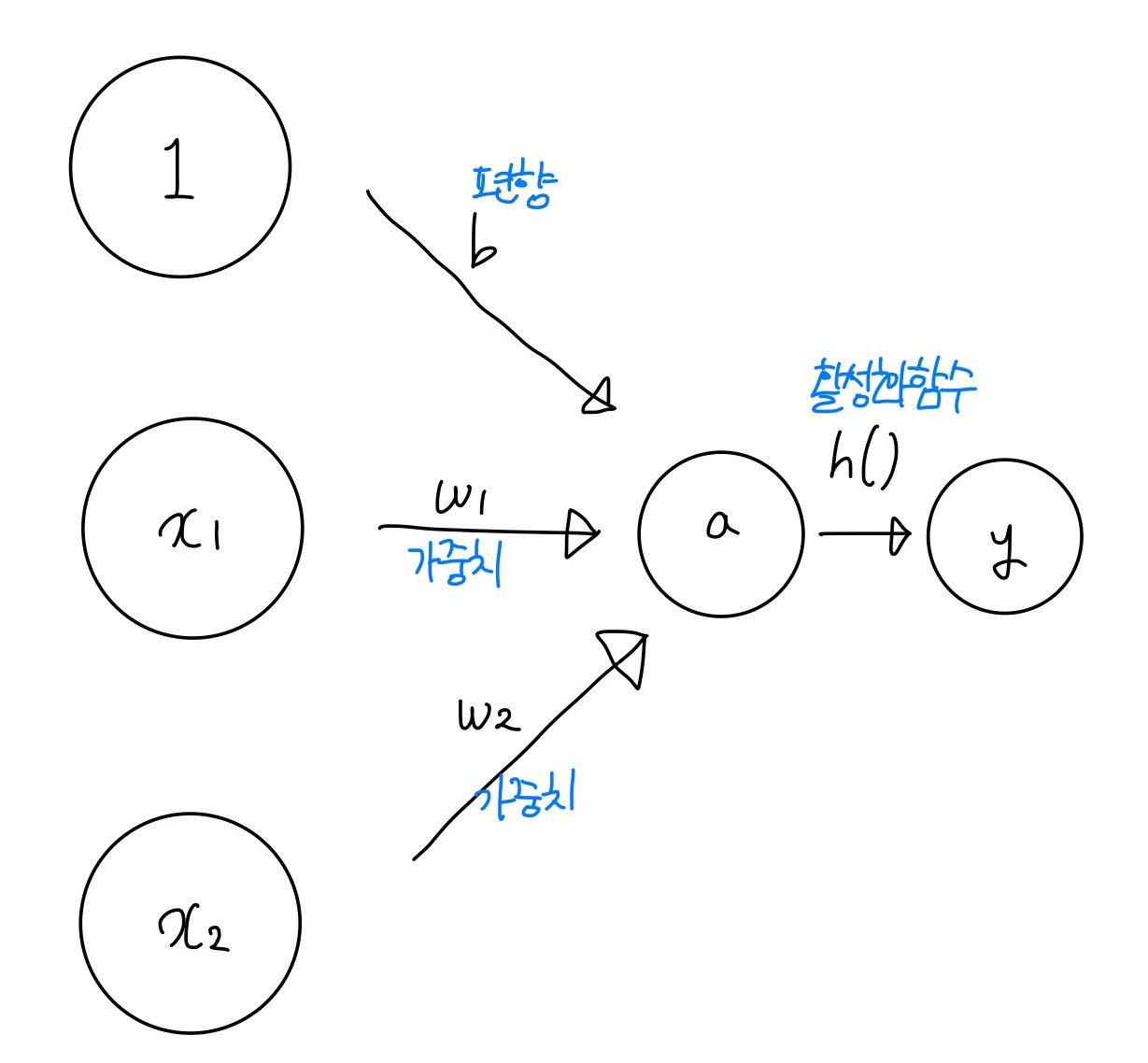
우선 퍼셉트론에서, x1와 x2를 입력받아 y를 출력하게 된다. 이때 b라는 편향을 통해 퍼셉트론이 얼마나 쉽게 활성화 되는지에 대한 정도를 결정한다. 편향이 -1000이라면, 입력값이 1000이 넘어야 활성화 될 것이고, 편향이 -10이라면, 입력값이 10만 넘어도
2.[딥러닝 기초개념] 손실함수

타켓의 실제값과 도출한 예측값의 차이를 수치화해주는 함수이다. 오차가 클수록 손실함수의 값이 크고, 오차가 작을수록 손실함수의 값이 작아진다. 그래서 모델성능의 '나쁨'의 정도를 나타낼 수 있다.손실함수의 값(loss)을 최소화하는 W(가중치), b를 찾아가는 것이 학
3.[딥러닝 기초개념] 최적화 (Optimization)

loss 함수의 최소값을 찾아가는 것경사하강법이란, 네트워크의 파라미터들을 θ(W,b)라 했을 때, Loss function J(θ)의 optima(최소화)를 찾기위해 파라미터의 기울기(gradient)를 이용하는 방법이다.알파는 learning rate에 해당하며,
4.[딥러닝 기초개념] Dropout

네트워크의 유닛의 일부만 동작하도록하고, 일부는 동작하지 않도록 하는 방법이다.dropout은 1. 오버피팅을 방지하기 위한 방법 중 하나이며, hidden layer의 일부 유닛을 동작하지 않게 하는 것이다.hidden layer에 드롭아웃을 확률 p로 적용할 때,
5.[딥러닝 기초개념] 기울기 소실과 폭주 (Gradient Vanishing / Exploding)
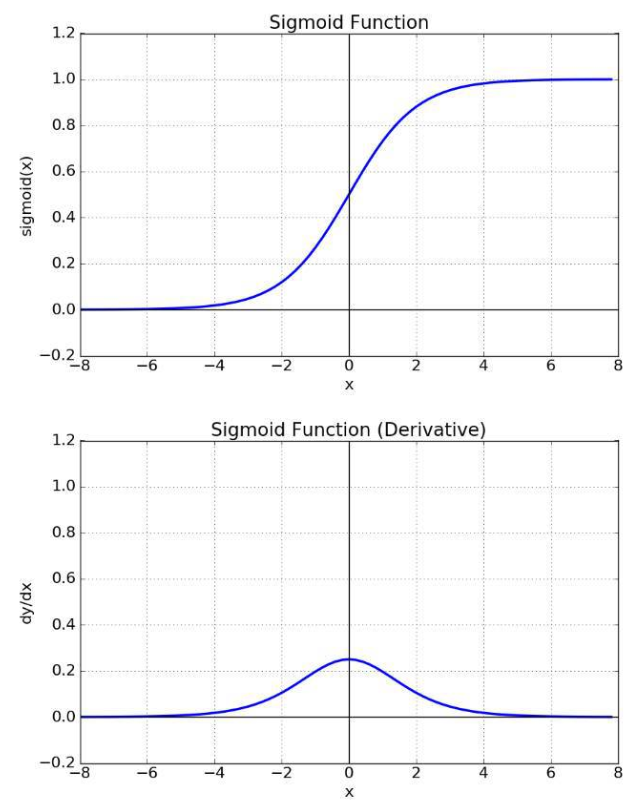
https://wikidocs.net/61375역전파 과정에서 입력층으로 갈수록, 기울기가 점차적으로 작아지는 현상이 발생할 수 있다. 이러한 현상으로 입력층에 가까운 층들에서 가중치들이 업데이트가 제대로 되지 않으면 결국 최적의 모델을 찾을 수 없게 되고,
6.[딥러닝 모델] CNN(Convolutional Neural Network)

CNN 쉼게 이해하기 참고 블로그 일반 DNN은 기본적으로 1차원 형태의 데이터를 사용한다. 따라서 이미지가 입력될 경우, 이것을 flatten 시켜서 한줄의 데이터로 만들게 된다. 이 과정에서 이미지의 공간적 정보가 손실되어, 특징 추출과 학습이 비효율적이고 정확도의
7.[딥러닝 모델] RNN 과 LSTM
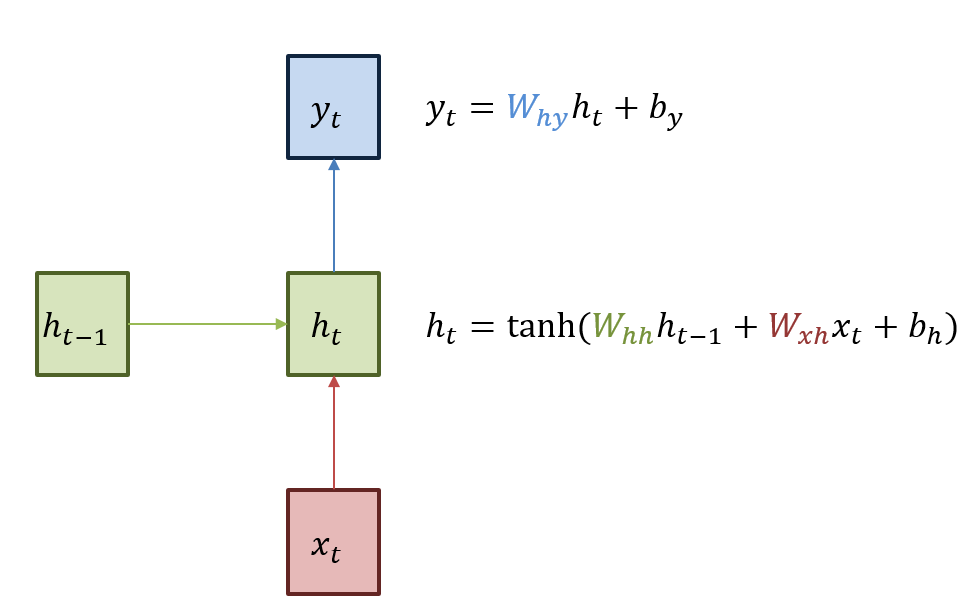
https://wikidocs.net/22886https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/RNN은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스 모델이다. 예를
8.[딥러닝 모델] 어텐션(Attention)
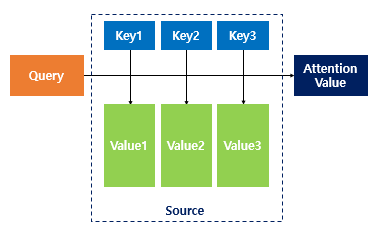
https://wikidocs.net/22893RNN을 기반으로한 언어 모델에서 크게 두가지 문제가 발생했는데, 먼저 하나의 고정된 크기 벡터에 모든 정보를 압축하려고 하니 정보손실이 발생한다는 점과, 기울기 소실(Vanishing Gradient)문제가 발생
9.[딥러닝 모델] 트랜스포머 (Transformer)
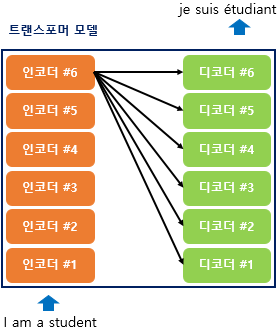
https://wikidocs.net/31379트랜스포머는 RNN을 사용하지 않지만, 기존 seq2seq 처럼 인코더에서 입력시퀀스를 입력받고, 디코더에서 출력시퀀스를 출력하는 인코더-디코더구조를 가진다. 이전에는 하나의 RNN인 t개의 시점을 가지는 구조였는
10.[딥러닝 모델] AutoEncoder
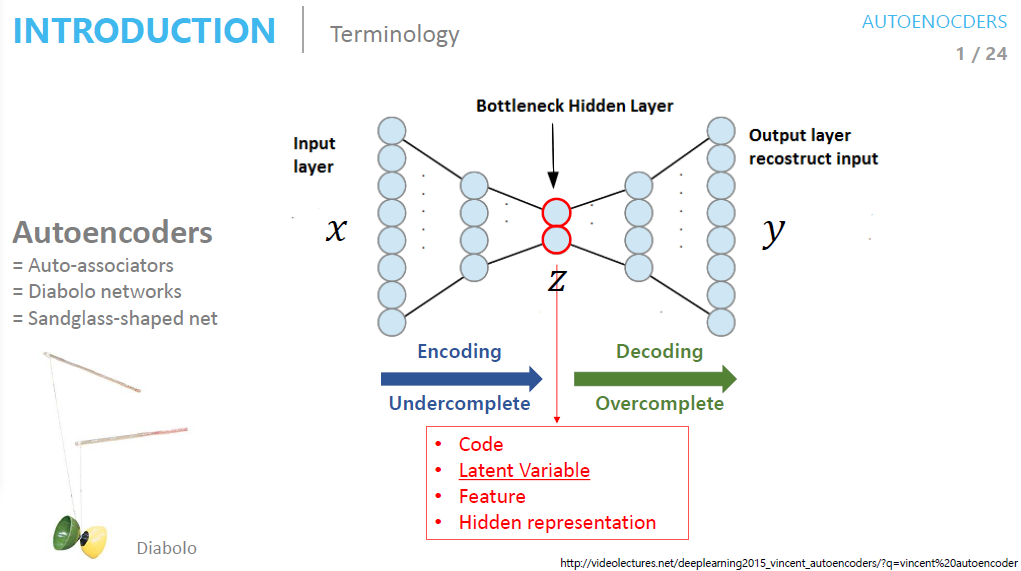
https://deepinsight.tistory.com/126오토인코더(Autoencoder)는 단순히 입력을 출력으로 복사하는 신경망이다. 이 때 hidden layter의 뉴런수를 input layer보다 작게 해서 데이터를 압축하거나 노이즈를 추가해 원
11.[딥러닝 모델] GAN (Generative Adversarial Network)
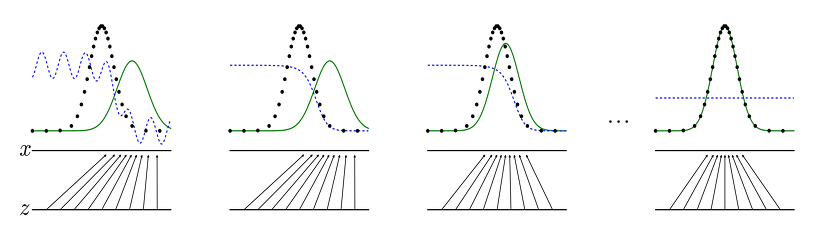
GAN은 일반적인 머신러닝에서 예측값을 생성해내는 것과 달리, 데이터의 형태를 만들고자 하는 목적을 가지고 있다. 여기서 데이터의 형태는 분포 혹은 분산을 나타내고, 단순히 결과값을 도출하는 함수가 아닌 실제적인 형태를 갖춘 데이터를 만들어 내는 것이다.위 그림은 GA