GAN의 목적
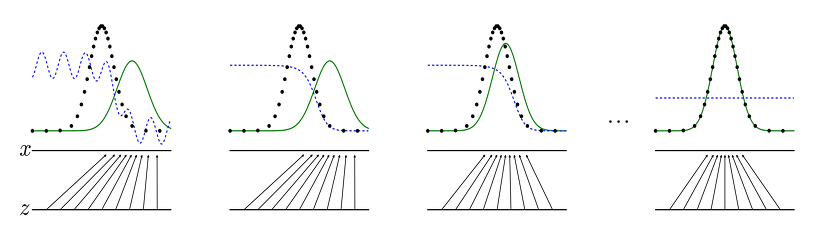
GAN은 일반적인 머신러닝에서 예측값을 생성해내는 것과 달리, 데이터의 형태를 만들고자 하는 목적을 가지고 있다. 여기서 데이터의 형태는 분포 혹은 분산을 나타내고, 단순히 결과값을 도출하는 함수가 아닌 실제적인 형태를 갖춘 데이터를 만들어 내는 것이다.
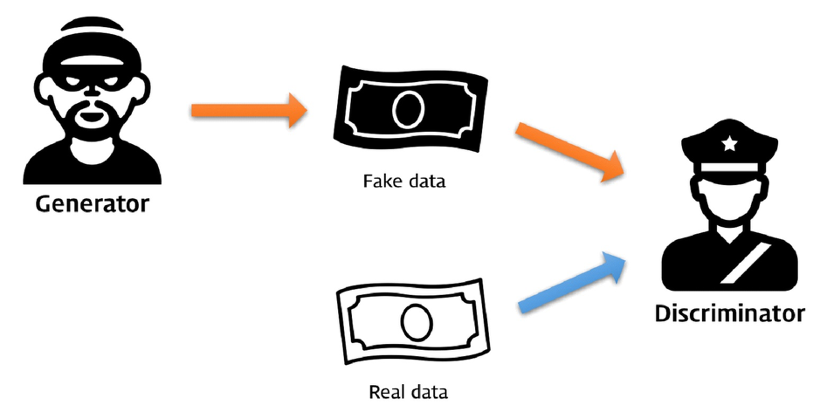
위 그림은 GAN을 설명할 때 흔히 사용되는 예시이고, 지폐위조범과 경찰이다. 지폐 위조범에게 Generator 라는 역할을, 경찰에게는 Discriminator 역할을 부여한다. 위조지폐범이 위조지폐를 만들었을 때 경찰이 가짜라고 판독하면 위조지폐범은 더 진짜 같은 지폐를 만들게 되고, 이와 같은 과정을 반복하여 진짜 같은 가짜를 생성해내는 능력을 키워주는 아이디어가 GAN의 핵심이다.
GAN의 학습 방법
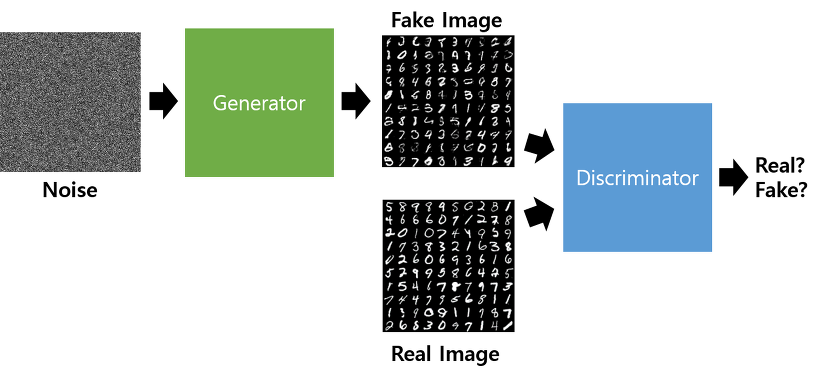
Generator는 랜덤 노이즈를 생성하는 벡터 z를 input으로 하고, Discriminator가 판별하고자 하는 input 이미지를 output으로 하는 뉴럴 네트워크 유닛이다. 학습과정에서는 실제 이미지를 Discriminator로 하여금 진짜라고 학습시키는 과정과, 벡터 z와 Generator에 의해 생성된 fake 이미지를 가짜라고 학습시키는 두개의 과정으로 나뉜다. 여기서 Discriminator는 이 두번의 과정을 따로 학습하는 것이 아닌, 첫번재 과정에서의 Real image와 Fake image를 Discriminator의 input으로 합쳐서 학습한다.
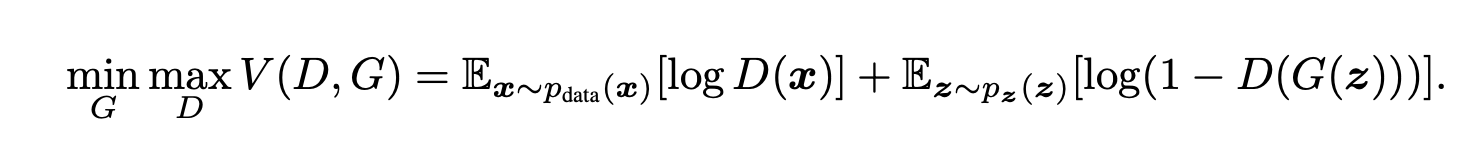
위 수식은 GAN의 목적함수이며, 여기서 V(D,G)는 확률값으로 도출된다. D(Discriminator)의 관점에서 실제 데이터를 입력하면 D(x)가 커지면서 log값이 커져 높은 확률 값이 나오도록 하고, 가짜 데이터(G(z))를 입력하면 log값이 작아져 낮은 확률값이 나오도록 학습된다. D는 실제 데이터와 G(Generator)가 만든 가짜 데이터를 잘 구분하도록 조금씩 업데이트 되는 것이다.
G에서는 노이즈 z를 멀티레이어 퍼셉트론에 통과시켜 샘플들을 생성하며 이 생성된 가짜 데이터 G(z)를 D에 input으로 넣었을 때 실제 데이터처럼 확률이 높게 나오도록 학습된다. 즉 D(G(z))값을 높도록, 전체 확률값이 낮아지도록 하는 것이기 때문에 G가 D를 잘 구분하지 못하는 데이터를 생성하도록 업데이트 된다.
