이번 포스팅은 PEANUT 프로젝트를 진행하면서 사용할 YOLOv5을 커스텀하기 전 CNN에 대한 이론에 대해 자세히 알아보겠습니다.
CNN
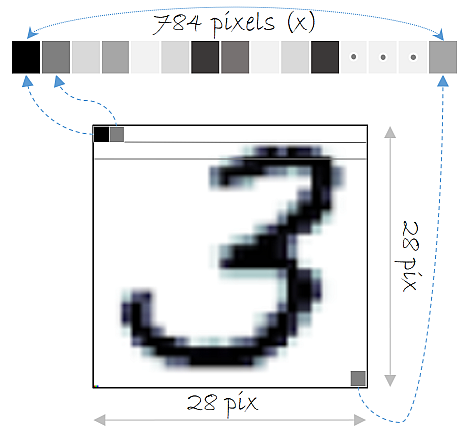
만약 2,3차원 데이터, 즉 이미지를 퍼셉트론 모델에 학습을 시킨다면? 2,3 차원의 데이터를 1차원으로 변환(평면화)하고, 이 과정에서 3차원 이미지의 공간적인 정보들은 손실 될 것입니다.
공간적 정보가 손실된 데이터를 학습시킨다면 인공신경망의 데이터 특징을 온전히 추출 할 수 없고, 학습도 비효율적일 것입니다.
이렇게 공간적인 정보 손실 없이 공간적 정보를 유지한 채 학습을 진행하려면 바로 CNN 모델을 사용해야 합니다.

CNN은 합성곱층(convolution layer)과, 풀링층(pooling layer), 완전 연결층(fully connected layer)로 구성된 모델입니다.
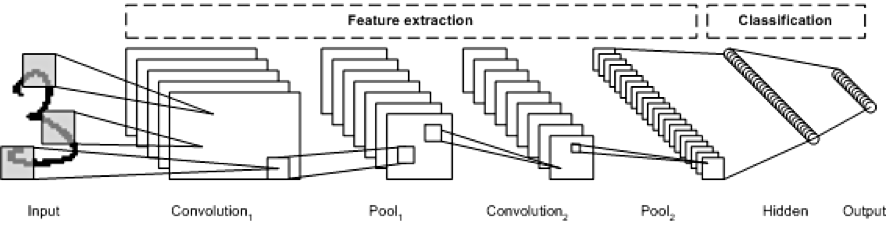
CNN은 위에 사진 처럼 합성곱층(convolution layer)과 풀링층(pooling layer)으로 이루어진 특징추출 부분(feature extraction)과 완전 연결층(fully connected layer)으로 구성된 클래스 분류 등과 같은 의사결정 부분으로 나뉩니다.
특징추출(feature extraction)
특징 추출 부분은 convolution layer와 pooling layer을 여러 겹으로 쌓는 형태이며, 해당 과정을 통해 입력데이터의 특징을 추출한 featur map이 출력됩니다.
convolution layer는 CNN모델에서 필수적인 layer이며 입력데이터에 필터를 적용 한 후 활성화 함수를 적용해줍니다.
pooling layer은 convolution layer 다음에 수행되는 layer로 선택적으로 적용해줍니다.
클래스분류(Classification)
decision making을 하는 부분으로 이미지 분류를 하기 위한 fully connected layer가 수행됩니다.
이때 fully connected layer의 입력데이터는 1차원이여야 하므로 입력데이터에서 추출한 feature map을 1차원 배열 형태로 만들어주는 Flatten Layer가 필요합니다.
이렇게 CNN에 대한 개념적인 내용들을 공부하는데, 단어들이 너무 어려웠습니다.
-> 여기서 convolution은 무엇일까요?
합성곱층
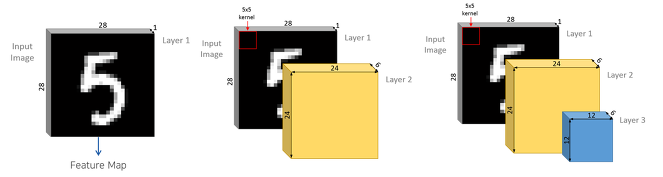
합성곱층은 CNN에서 가장 중요한 구성요소이며, 위의 그림처럼 완전연결 계층과는 달리 합성곱층(convolutional layer)은 아래의 그림과 같이 입력 데이터의 형상을 유지합니다. 3차원의 이미지 그대로 입력층에 입력받으며, 출력 또한 3차원 데이터로 출력하여 다음 계층(layer)으로 전달하기 때문에 CNN에서는 이미지 데이터처럼 형상을 가지는 데이터를 제대로 학습할 가능성이 높다고 할 수 있습니다.
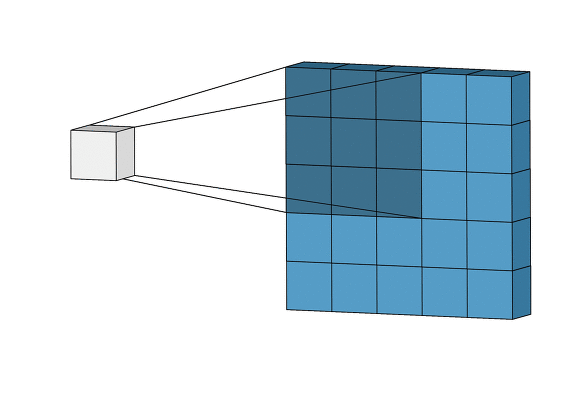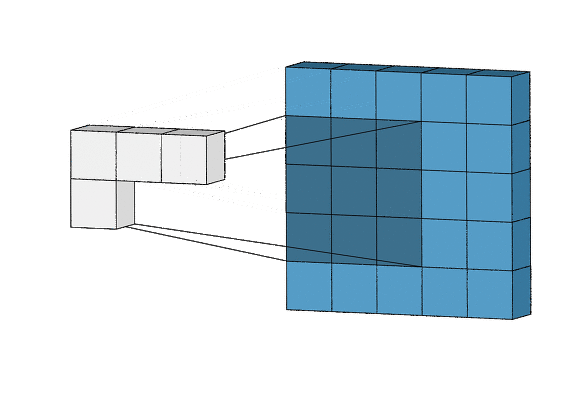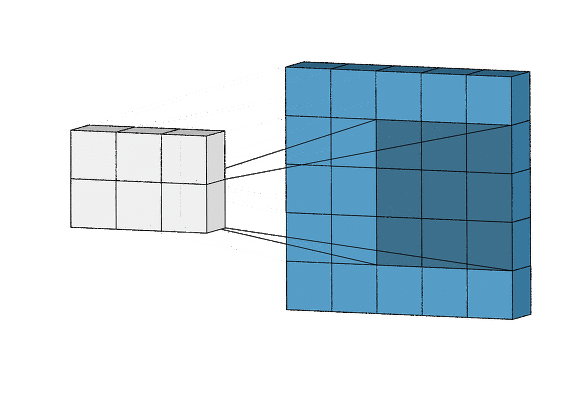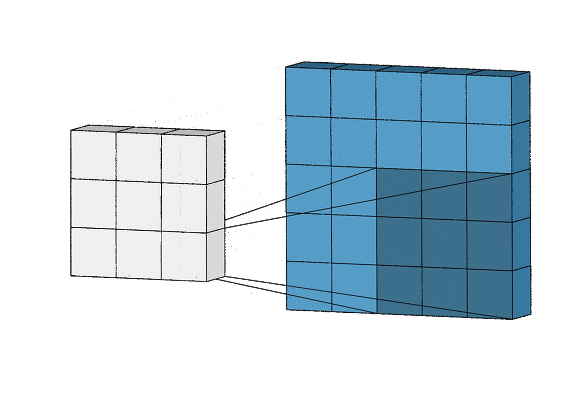
합성곱층의 뉴런은 아래의 그림처럼(출처: towardsdatascience.com) 입력 이미지의 모든 픽셀에 연결되는 것이 아니라 합성곱층 뉴런의 수용영역(receptive field)안에 있는 픽셀에만 연결이 되기 때문에, 앞의 합성곱층에서는 저수준 특성에 집중하고, 그 다음 합성곱층에서는 고수준 특성으로 조합해 나가도록 해줍니다.
흑백이미지와 같은 2차원 데이터의 convolution(합성곱) 알아보기
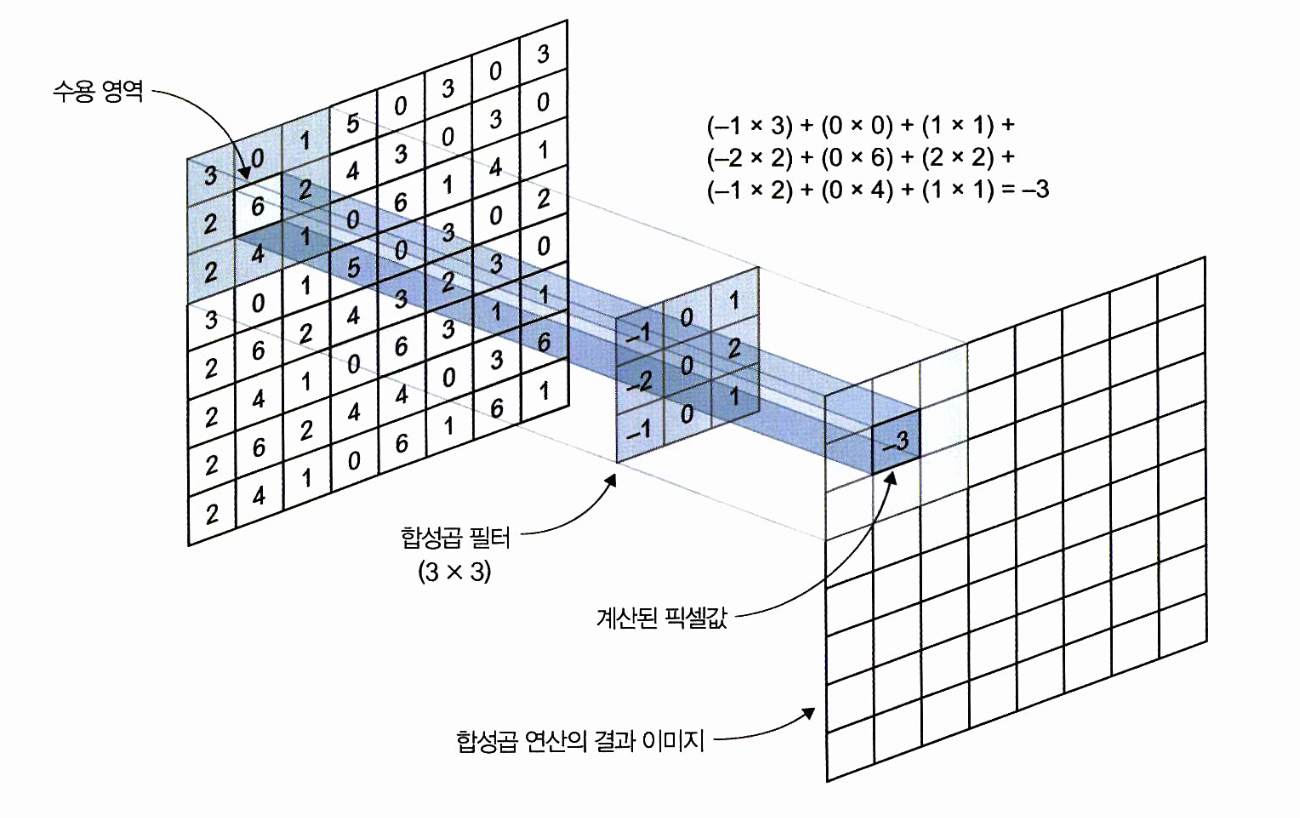
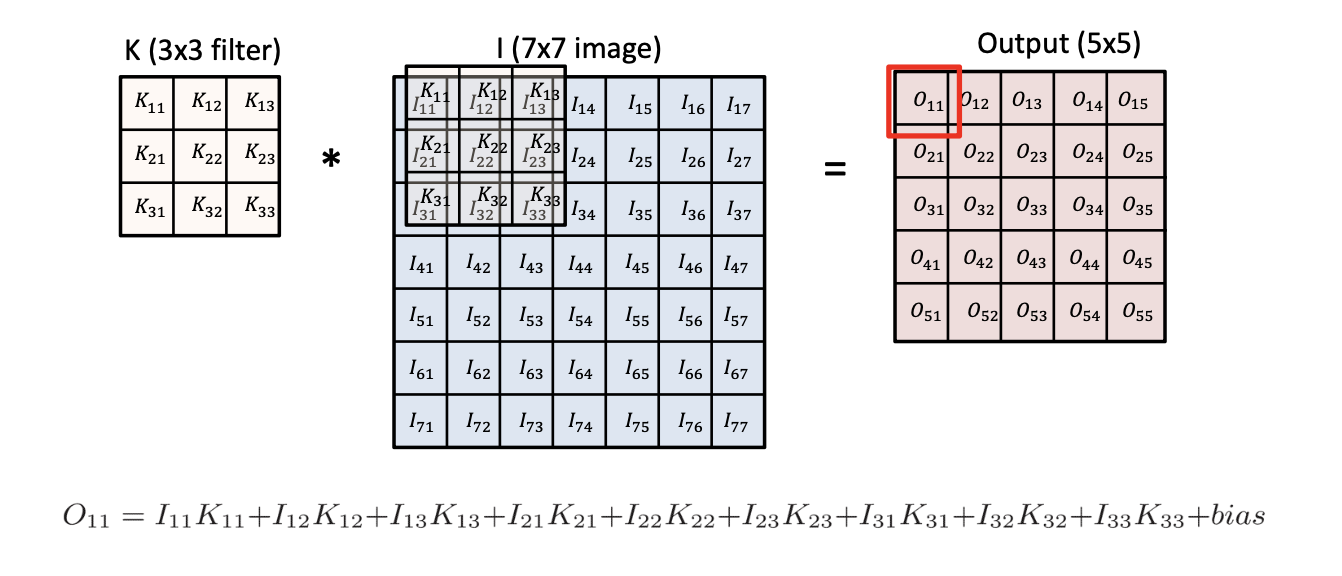
두번째 이미지를 보면 (7,7) 이미지가 있을 때 (3,3) 필터(커널이라고도 불린다)를 맨 왼쪽 위부터 오른쪽과 아래로 한 칸씩 이동해 가며 맨 끝까지 도장찍듯이 적용해주는 것입니다.
필터(fillter)는 가중치가 담긴 행렬이기 때문에 커널(kernel)이라고도 불립니다.
한번 도장을 찍을때 매칭되는 칸끼리 곱하고 이런 값들을 모두 합해주면 output의 하나의 셀값이 나옵니다.
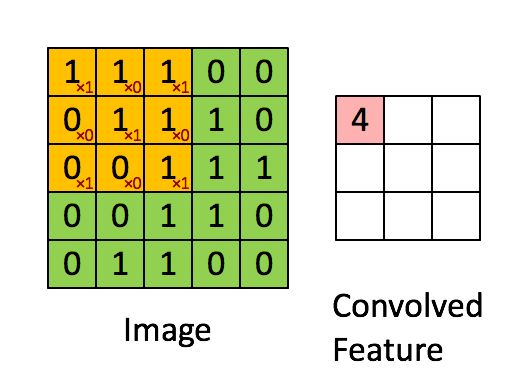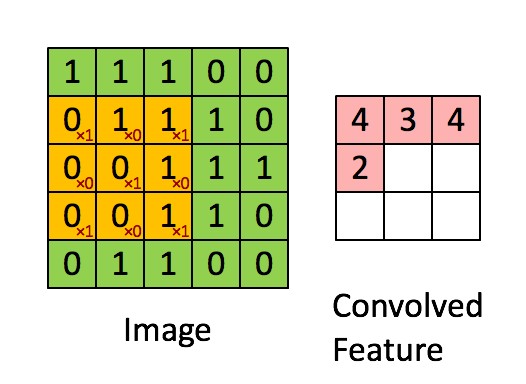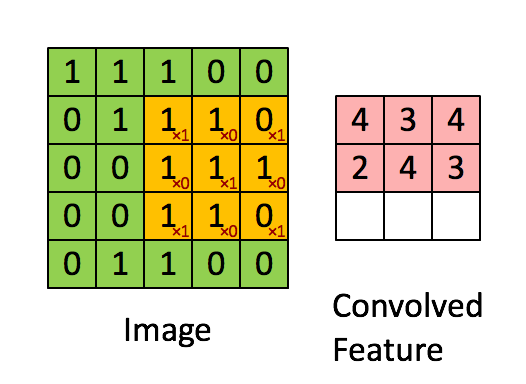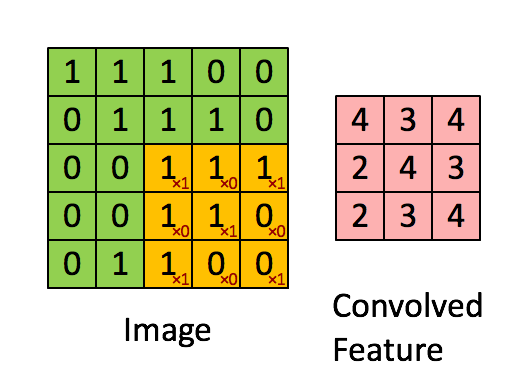
kernel(커널)
- 커널의 값들(합성곱 행렬)은 우리가 학습할 가중치입니다.
- 초기 가중치는 랜덤 값으로 진행되지만, 커널의 값들을 어떻게 설정 할 것인지에대한 부분은 신경 쓰지 않아도 됩니다. 중요한건 커널의 개수와 사이즈 입니다.
커널을 적용한 특징맵

3차원 데이터의 convolution
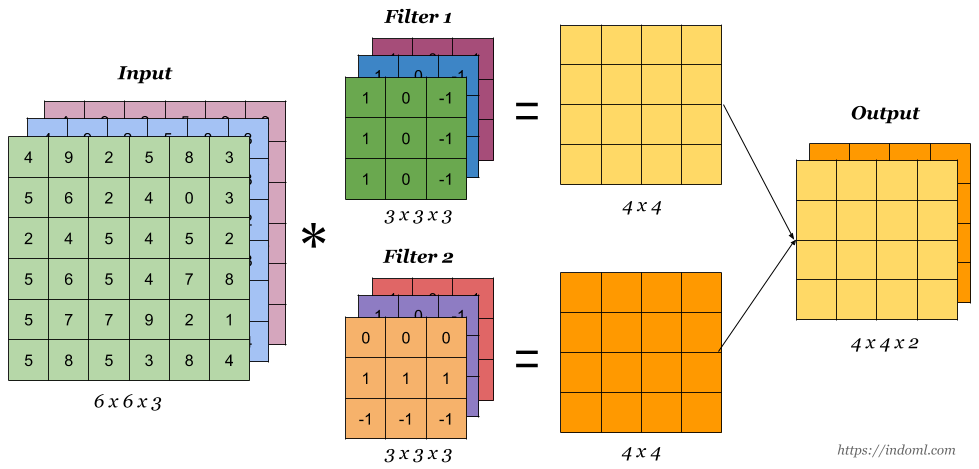
채널의 수가 늘어나지만 연산 원리는 똑같습니다. 필터가 1개라는 가정하에 흑백 이미지 일때는 특징맵이 1개가 생기고, 컬러 이미지 일때는 채널이 3으로 3개의 특징맵이 생기는게 아니라 필터가 1개라면 특징맵도 채널의 개수는 1개 입니다. 특징맵의 채털의 개수는 필터의 갯수와 연간이 있습니다.
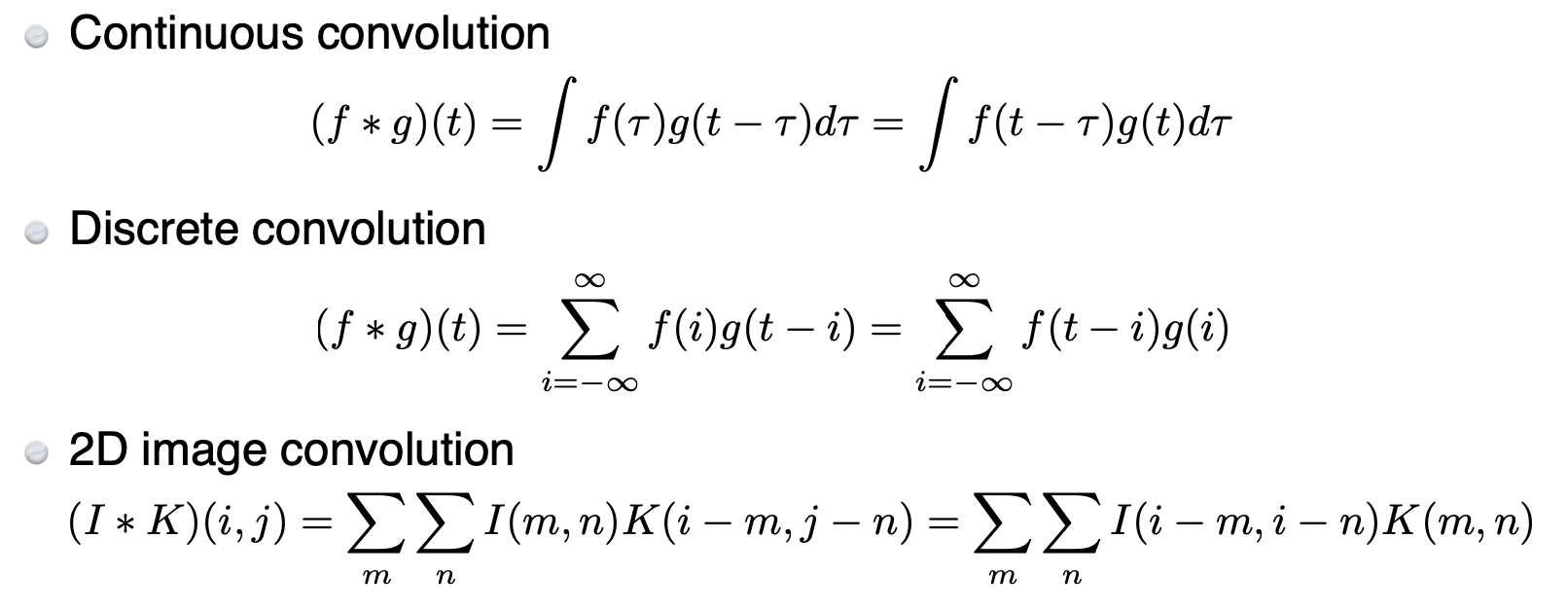
위 그림은 convolution의 수식입니다. 필터가 도장을 찍을 때, 한 칸이 아닌 몇 칸 이동하는 것을 스트라이드 라고 합니다.
참고|
[https://excelsior-cjh.tistory.com/180][https://velog.io/@hipjaengyi_cat18/CNNConvolutional-Neural-Network]
[https://supermemi.tistory.com/entry/Convolution%ED%95%A9%EC%84%B1%EA%B3%B1%EC%9D%98-%EC%9B%90%EB%A6%AC%EC%99%80-%EB%AA%A9%EC%A0%81]
이렇게 간단하게 cnn 개념들을 정리해보았습니다. 사실 더 자세한 내용들도 있고, 많은 내용이 더 있지만 제가 이해한 부분들 위주로 포스팅했습니다. 다음은 새로 알게된 내용과 YOLO알고리즘에 대한 내용들도 포스팅하도록 하겠습니다.
