RAG 처음부터 고도화까지 — 3편: 검색 끌어올리기 (Hybrid + HyDE + Reranking + MMR)
시리즈 「RAG 처음부터 고도화까지」 — 3부.
1편 · 2편: Indexing 까지 본 상태.
이번 글의 목표
5축 중 ③ 검색 + ④ 재정렬 (Retrieval 단계) 의 정교화.
같은 임베딩, 같은 청크에서도 검색을 어떻게 하느냐 가 답변 품질을 다시 한 번 갈라놓습니다. 다룰 것:
- 쿼리 변환 — Multi-Query · HyDE · Step-Back · Decomposition · RAG-Fusion
- 하이브리드 검색 — Dense + BM25 + RRF
- ColBERT / late interaction — 정확도 한 단계 위
- 재정렬 (reranking) — Cross-encoder · LLM-as-Reranker · Cohere Rerank
- MMR — 결과 다양성 확보
- Lost-in-the-Middle 재배치 + 컨텍스트 압축
1. 쿼리 변환 — 검색 전 LLM 한 번 끼우기
사용자가 던지는 질문은 보통 짧고 모호합니다.
"레이어 그리는 순서"이 질문 하나로 임베딩 검색하면 결과가 약합니다. 검색 직전에 LLM 으로 질문을 가공 하면 같은 인덱스에서 훨씬 좋은 결과가 나옵니다.
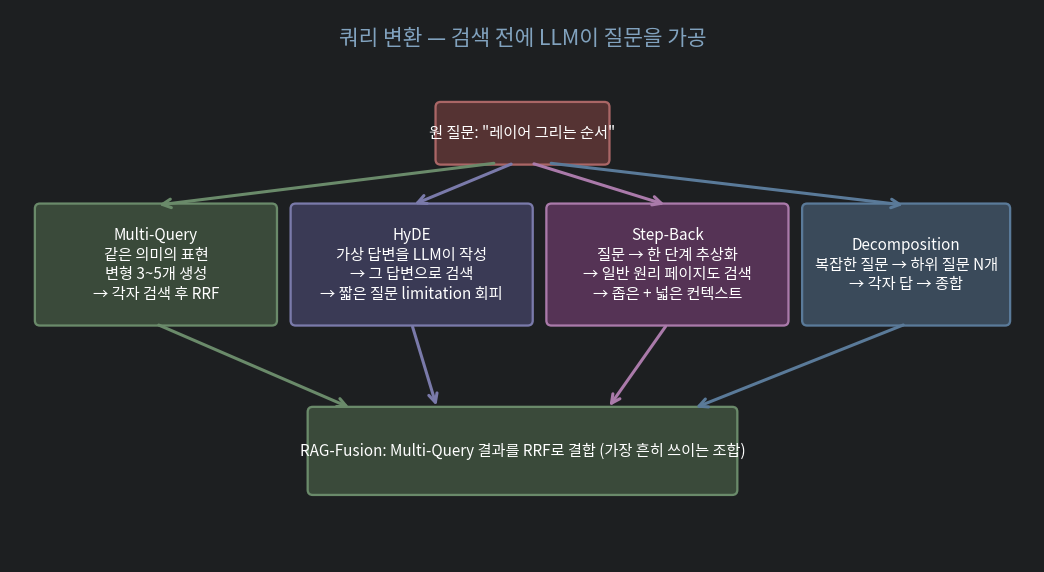
1.1. Multi-Query
같은 의미의 변형 질문 3~5 개를 LLM 이 생성. 각각으로 검색 → 결과 합치기 (RRF).
prompt = "아래 질문을 의미 유지하면서 표현이 다른 한국어 질문 3개로 바꿔라.\n질문: " + q
variants = llm.chat(prompt).strip().splitlines()
all_hits = [retriever.search(v) for v in [q] + variants]
final = rrf_merge(all_hits)같은 의미의 다른 표현으로 매치되는 청크들을 모두 끌어옴 → recall 상승.
1.2. HyDE — Hypothetical Document Embeddings
LLM 이 질문에 대한 가상 답변 을 먼저 작성하고, 그 답변으로 검색.
hypo = llm.chat(f"다음 질문에 대한 가상의 답변을 2~3문장으로 써라(검색용). 질문: {q}")
hits = retriever.search(hypo)핵심 아이디어: 답변 임베딩이 답변 임베딩과 더 가깝다. 짧은 질문이 긴 본문과 매치되기는 어렵지만, 짧은 질문 → 긴 가상 답변 → 긴 본문 매치는 잘 됨.
1.3. Step-Back Prompting
질문을 한 단계 추상화 한 일반 질문도 같이 검색:
원 질문: "XDL 3.0 에서 NXImageView 의 setSource 호출 흐름"
Step-Back: "XDL 의 일반적인 View 생명주기는?"좁은 + 넓은 컨텍스트를 동시에. 일반 원리 문서(아키텍처 개론 등) 도 답변에 들어오게 됨.
1.4. Decomposition
복잡한 질문을 하위 질문 N개로 분해, 각자 답 한 뒤 종합.
사용자: "어떻게 XDL의 Layer 시스템이 React의 가상 DOM보다 빠른가?"
→ Q1: XDL Layer 시스템 동작 원리
→ Q2: React 가상 DOM 동작 원리
→ Q3: 둘의 성능 비교 데이터
→ 합쳐서 최종 답변Multi-hop 질문에 강함. 한 번에 못 푸는 질문을 단계로 쪼개서 푸는 것.
1.5. RAG-Fusion — 가장 흔한 조합
Multi-Query + RRF 의 명칭. 단독 기법 이름이라기보단 위 둘의 조합 패턴. 2026 년 가장 자주 보는 baseline.
variants = generate_variants(q)
rankings = [retriever.search(v) for v in [q] + variants]
final = rrf_merge(rankings, k=60)비용은 LLM 호출 1회 (변형 생성) + 임베딩 N+1회. 효과 대비 가성비 매우 좋음.
2. 하이브리드 검색 — Dense + BM25
Dense 임베딩은 의미 비슷한 문장 을 잘 찾습니다. 그런데:
- "NXImageView" 같은 고유명사 / 식별자 / 약어
- "v3.2.1" 같은 버전 번호
- "OAuth 2.1" 같은 정확 토큰
이런 건 dense 임베딩이 일반 단어로 흡수해서 못 찾는 경우가 많습니다.
BM25 (전통적 단어 빈도 기반 sparse 검색) 가 이런 토큰형 매칭을 잘 잡습니다. 둘 다 돌리고 결과를 합치는 게 하이브리드 검색.
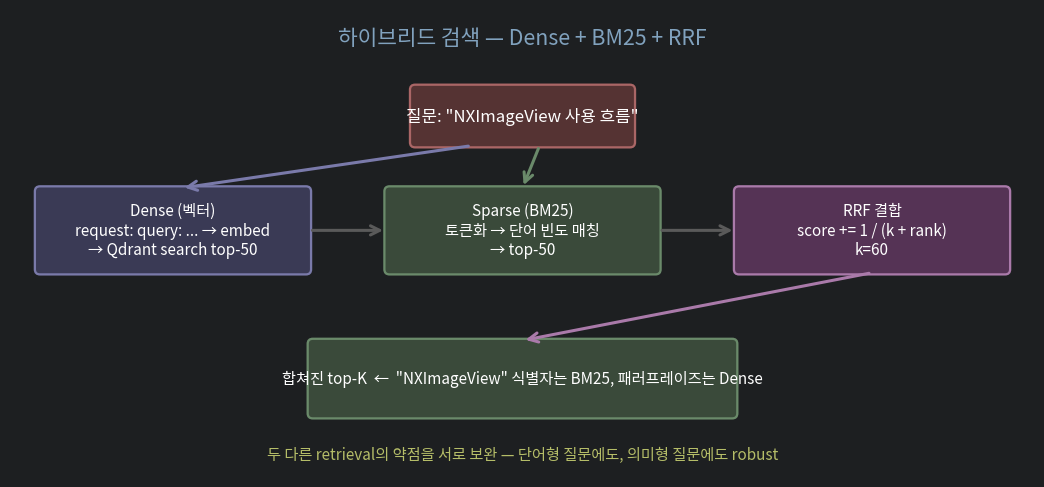
2.1. 결합 방법 — RRF (Reciprocal Rank Fusion)
def rrf_merge(rankings, k=60):
scores, seen = {}, {}
for ranked in rankings:
for rank, item in enumerate(ranked, start=1):
pid = item.id
scores[pid] = scores.get(pid, 0.0) + 1.0 / (k + rank)
seen[pid] = item
return sorted(seen.values(), key=lambda x: scores[x.id], reverse=True)
dense_hits = dense_retriever.search(q, k=50)
sparse_hits = bm25_retriever.search(q, k=50)
merged = rrf_merge([dense_hits, sparse_hits])RRF 의 매력은 점수 단위가 다른 두 retrieval 을 정규화 없이 합칠 수 있다는 것. Dense 의 cosine 점수와 BM25 의 점수는 단위가 완전 달라서 직접 가중합이 어렵지만, 순위만 보는 RRF 는 자연스럽게 결합됩니다.
k=60 은 BM25 논문에서 온 디폴트. 다른 값으로 튜닝해도 됨.
2.2. BM25 토큰화
영문은 단어 분할만 하면 OK. 한국어는 형태소 분석기 가 필요합니다.
# 간단 (영문+한글 음절 단위 — 첫 PoC 용)
import re
def tokenize(text):
return [t.lower() for t in re.findall(r"[가-힣]+|[A-Za-z0-9_]+", text)]
# 실전 (한국어 정확도 ↑)
from konlpy.tag import Mecab # 또는 Kiwi
mecab = Mecab()
def tokenize(text):
return mecab.morphs(text)rank_bm25 (pip install rank_bm25) 가 가장 가벼움. 대용량이면 Pyserini 또는 Elasticsearch.
2.3. Sparse 임베딩 — 차세대
BM25 자리에 학습된 sparse 임베딩 을 쓰는 방향도 있음. BAAI/bge-m3 가 같은 모델에서 dense + sparse + multi-vec 출력을 동시에 줍니다. Qdrant 도 sparse vector 지원 → 하이브리드를 한 DB 안에서.
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
out = model.encode(text, return_dense=True, return_sparse=True, return_colbert_vecs=True)
# out: dense (1024-d), sparse (token-weighted dict), colbert (multi-vec)3. ColBERT / Late Interaction — 한 단계 위
위 dense / sparse 는 문서 한 개당 벡터 한 개. ColBERT 는 문서를 토큰 단위 벡터 묶음으로 임베딩하고, 검색 시 토큰 ↔ 토큰 최대 매칭을 계산합니다.
일반 dense: doc_vec · q_vec
ColBERT: sum over q_token of max over doc_token of (q_token · doc_token)정확도가 일반 dense 보다 10~30% 높지만 인덱스 사이즈가 (토큰 수 × 차원) 으로 커지고 검색이 느립니다. 재정렬 단계 에서 한 번 쓰는 게 일반적 (top-100 가져오고 ColBERT 로 다시 정렬).
bge-m3 가 colbert_vecs 도 내주니까 셋 다 한 모델로 가능합니다.
4. 재정렬 (Reranking) — 후보 50 → 정확한 5
검색은 빠르게 top-50 후보를 가져오고, 느리지만 정확한 모델로 다시 정렬해 top-5 만 LLM 에 줍니다. 이게 모던 RAG 의 표준 구성.
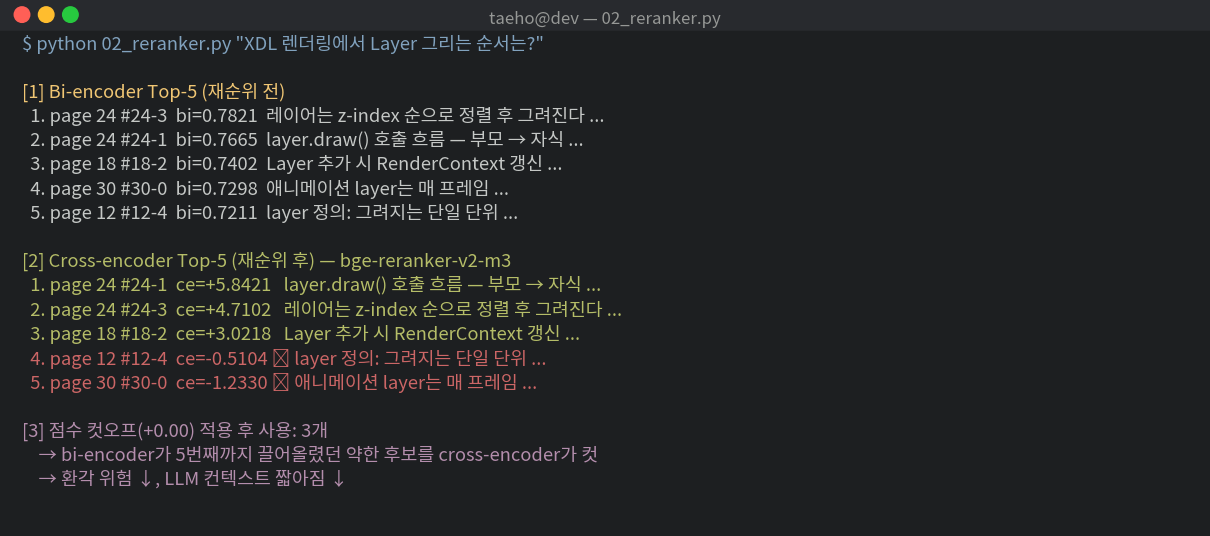
4.1. Cross-Encoder Reranker
일반 검색 (bi-encoder): question → vec_q, doc → vec_d, cosine(vec_q, vec_d)
Cross-encoder: (question, doc) → 트랜스포머 한 번 통과 → relevance score질문과 문서를 같이 트랜스포머에 넣어서 점수 계산. 두 텍스트의 상호작용을 다 보기 때문에 훨씬 정확.
대표 모델: BAAI/bge-reranker-v2-m3 — 다국어, 600MB.
from sentence_transformers import CrossEncoder
reranker = CrossEncoder("BAAI/bge-reranker-v2-m3", max_length=512)
pairs = [(question, h.text) for h in hits]
scores = reranker.predict(pairs)
reranked = sorted(zip(hits, scores), key=lambda x: x[1], reverse=True)4.2. 점수 컷오프
bge-reranker 는 로짓을 출력 (양수면 관련 있음, 음수면 관련 없음). 임계값으로 약한 후보를 잘라내자 — 환각 방지.
kept = [(h, s) for h, s in reranked if s >= 0.0]
if not kept:
return "근거 없음 — 답변 보류" # 환각보다 안전이 한 줄이 RAGAS faithfulness 를 가장 크게 올립니다.
4.3. LLM-as-Reranker
별도 reranker 모델 안 쓰고 같은 LLM 으로 listwise 재정렬:
catalog = "\n".join(f"[{i}] {h.text[:140]}" for i, h in enumerate(hits))
prompt = (
"다음 후보 중 사용자 질문에 가장 도움 되는 순서로 인덱스만 콤마로 출력. "
"상위 5개면 충분.\n"
f"질문: {q}\n후보:\n{catalog}\n출력 예: 3,0,7,2,5"
)
order = parse_indices(llm.chat(prompt))
reranked = [hits[o] for o in order]- 장점: 별도 모델/인프라 필요 없음 — 같은 vLLM 한 번 더 호출
- 단점: LLM 한 번 호출 추가, 후보가 너무 많으면 컨텍스트 한도
4.4. Cohere Rerank / Jina Reranker — API
Cohere Rerank 3.5 가 2026 년 상용 reranker 중 가장 강력하다는 평. API 한 줄로 끝:
import cohere
co = cohere.Client(API_KEY)
results = co.rerank(model="rerank-3.5", query=q, documents=texts, top_n=5)비용은 1K docs 당 약 $1 수준. 운영 환경에서 매 query 마다 호출하면 비싸지만, 품질 최상위가 필요한 경우 (의료/법률 RAG) 에는 충분히 ROI.
5. MMR — 다양성 확보
검색 top-5 가 전부 같은 페이지의 다른 청크면 LLM 이 보는 정보가 사실상 하나입니다. MMR (Maximal Marginal Relevance) 가 이걸 막습니다.
def mmr(q_vec, cand_vecs, lambda_=0.6, top=5):
"""반복 선택: lambda·sim(q,d) - (1-lambda)·max sim(d, 이미 선택된 d')"""
selected, remaining = [], list(range(len(cand_vecs)))
sim_q = cand_vecs @ q_vec
while remaining and len(selected) < top:
if not selected:
best = max(remaining, key=lambda i: sim_q[i])
else:
def score(i):
rel = sim_q[i]
div = max(cand_vecs[i] @ cand_vecs[j] for j in selected)
return lambda_ * rel - (1 - lambda_) * div
best = max(remaining, key=score)
selected.append(best); remaining.remove(best)
return selectedlambda_=1.0→ 다양성 무시 (그냥 top-k)lambda_=0.0→ 관련성 무시 (다양성만)lambda_=0.5~0.7이 보통
비용 거의 0 — 그냥 후보 벡터 dot product 만. 반드시 reranker 뒤 / LLM 앞 에 한 번 끼우는 게 좋습니다.
6. Lost-in-the-Middle 재배치
LLM 은 컨텍스트의 시작과 끝 을 가장 잘 봅니다. 가운데 정보는 곧잘 무시합니다 (논문 "Lost in the Middle", Liu et al., 2023).
해결: 점수 1·3·5 등 홀수 순위는 앞쪽에, 짝수 순위는 뒤쪽에 배치.
def lim_reorder(ranked):
out = [None] * len(ranked)
left, right = 0, len(ranked) - 1
for i, item in enumerate(ranked):
if i % 2 == 0:
out[left] = item; left += 1
else:
out[right] = item; right -= 1
return out
# [1,2,3,4,5] -> [1,3,5,4,2]비용 0. 효과 작지만 일관됨. MMR 다음, 프롬프트 조립 직전 단계.
7. 컨텍스트 압축
검색 top-5 청크의 본문 그대로를 다 LLM 에 보내면 토큰 낭비가 큽니다. LLM 한 번 더 끼워서 각 청크에서 질문과 무관한 부분을 잘라내기:
for chunk in hits:
extract = llm.chat(
f"질문: {q}\n본문: {chunk.text}\n"
"질문과 관련 있는 문장만 그대로 발췌. 없으면 빈 줄."
)
if extract.strip():
compressed.append(extract)LongLLMLingua (Microsoft) 같은 전용 모델도 있음. 60~80% 토큰 압축하면서 답변 품질 거의 유지.
비용은 매 query 의 LLM 호출 +N회. 정말 컨텍스트가 큰 경우 (top-10+ × 긴 청크) 에만 유리.
8. 운영 디폴트 — 처음 어떻게 조합하나
추천 baseline:
질문
↓ (Multi-Query, 3 변형)
+ HyDE (가상 답변)
↓ 4개 쿼리로
[Dense top-30, Sparse(BM25) top-30] 각자 → RRF 합산 → top-50
↓
Cross-encoder rerank (bge-reranker-v2-m3) → top-10
↓ 점수 컷오프 0.0 적용 → 약한 후보 컷
MMR (lambda=0.6) → top-5
↓ Lost-in-the-Middle 재배치
프롬프트 조립 → LLM 응답가지치기 가능:
- 비용 줄이려면 — Multi-Query 빼고 HyDE 만, reranker 만 살리기
- 정확도 더 짜내려면 — Cohere Rerank 또는 ColBERT 추가, 컨텍스트 압축
참고
- Channel.tel, The RAG You Built Last Year Is Already Outdated (2026): link
- Lost in the Middle (Liu et al., 2023): arXiv:2307.03172
- BAAI/bge-m3 모델 카드: HuggingFace
- ColBERT (Khattab & Zaharia, 2020): arXiv:2004.12832
