
미션-1 정규표현식 연습하기
-
보안이 뛰어난 비밀번호인지 검증하기 (난이도: 상)
보안이 뛰어난 비밀번호는 일반적으로 아래와 같은 조건들을 만족해야 합니다.- 8자리 이상 30글자 미만
영어 대문자와 소문자 최소 1개씩 포함
하나 이상의 숫자 포함
하나 이상의 특수기호 (!@#$%^&*) 포함
- 8자리 이상 30글자 미만
주어진 비밀번호들이 위의 조건들을 만족하는지 검증하고, 만족하면 True / 만족하지 않으면 False를 반환하는 함수를 작성해보도록 합시다.
import re
def MyFunction(password:str)->bool:
password_checker = re.compile("^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[!@#$%^&*])[A-Za-z\d!@#$%^&*]{8,30}$" )
mat = re.search(password_checker, password)
return bool(mat)- 욕설 삐처리하기 (1) (난이도: 하)
def myFunction(text):
# 문장(text) 중 slang_list에 있는 단어들이 포함되어있으면, 단어를 별표(*) 치환하는 코드를 작성해주세요!
for word in slang_list:
if word in text:
text = text.replace(word,'*'*len(word))
return text- 욕설 삐처리하기 (2) (난이도: 중)
욕설 필터링을 피하기 위해 욕설 사이에 특수기호를 넣는 케이스도 많습니다 (e.g., "미@친", "지@@랄하네"). 이런 욕설들도 처리해봅시다!- 욕설 사이에 들어가는 특수기호는 @ 만으로 한정합니다.
- 특수기호는 최대 2번 들어갈 수 있으며, 연속해서 들어갑니다.
def myFunction(text):
for word in slang_list:
if word in text:
text = text.replace(word,'*'*len(word))
for char_idx,char in enumerate(word):
for special_token in ['@','@@']:
special_word = word[:char_idx]+special_token+word[char_idx:]
if special_word in text:
text = text.replace(special_word,'*'*len(special_word))
return text- 자소 문자 제거하기 (난이도: 하)
트위터 등의 SNS에서 추출한 데이터에는 한글의 자소가 포함된 텍스트가 많습니다. 이 데이터 내에서 자소만을 분리하여 제고해봅시다.
import re
def MyFunction(text):
# 이곳에 코드를 작성해주세요!
jaeum_list = ['ㄱ','ㄲ','ㄴ','ㄷ','ㄸ','ㄹ','ㅁ','ㅂ','ㅃ','ㅅ','ㅆ','ㅇ','ㅈ','ㅉ','ㅊ','ㅋ','ㅌ','ㅍ','ㅎ']
moeum_list = ['ㅏ','ㅑ','ㅓ','ㅕ','ㅗ','ㅛ','ㅜ','ㅠ','ㅡ','ㅣ','ㅘ','ㅚ','ㅙ','ㅜ','ㅟ','ㅝ','ㅢ']
jamo_checker = re.compile('['+''.join(jaeum_list)+''.join(moeum_list)+']+')
new_text = re.sub(jamo_checker,'',text)
return new_text- 크롤링된 위키피디아 문서 전처리하기 (난이도: 중)
다음은 크롤링한 위키피디아 페이지를 전처리하는 코드를 작성해봅시다. 크롤링한 위키피디아 문서에는 HTML 태크, 다른 위키피디아 페이지로의 하이퍼링크 등이 포함되어 있습니다. 크롤링한 문서에서 자연어만을 추출하여 반환하는 전처리 코드를 작성해봅시다.
def make_clean_wiki_page(crawled_page:List[str]):
# 이곳에 전처리 코드를 작성해주세요!
sents = [re.sub(r'\(.*?\)', "", (re.sub(r'\<.*?\>', "", sent))).strip() for sent in crawled_page]
return sentsBERT 언어모델
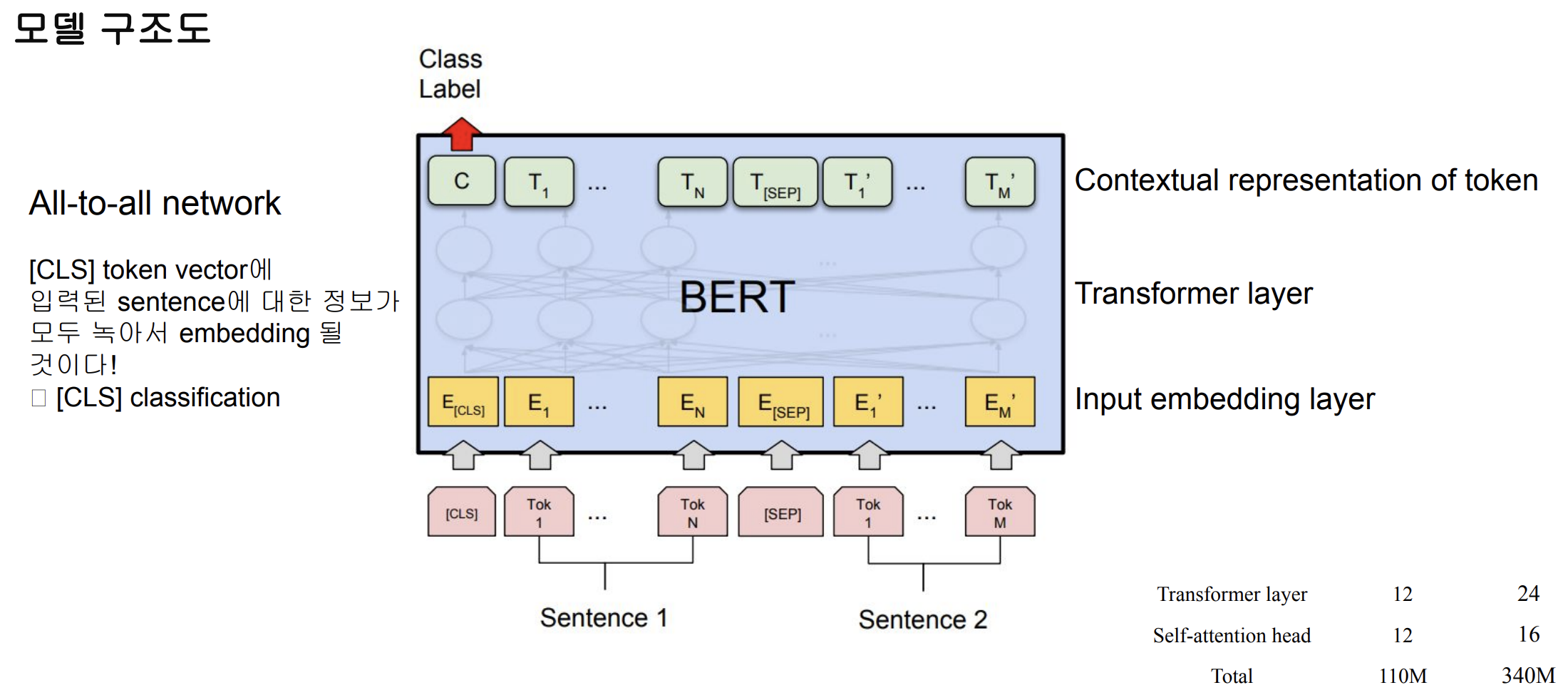
데이터의 tokenizing
- WordPiece tokenizing
- He likes playing He likes play ##ing
- 입력 문장을 tokenizing하고, 그 token들로 ‘token sequence’를 만들어 학습에 사용
- 2개의 token sequence가 학습에 사용
- Next sentence or Random chosen sentence
Masked Language Model
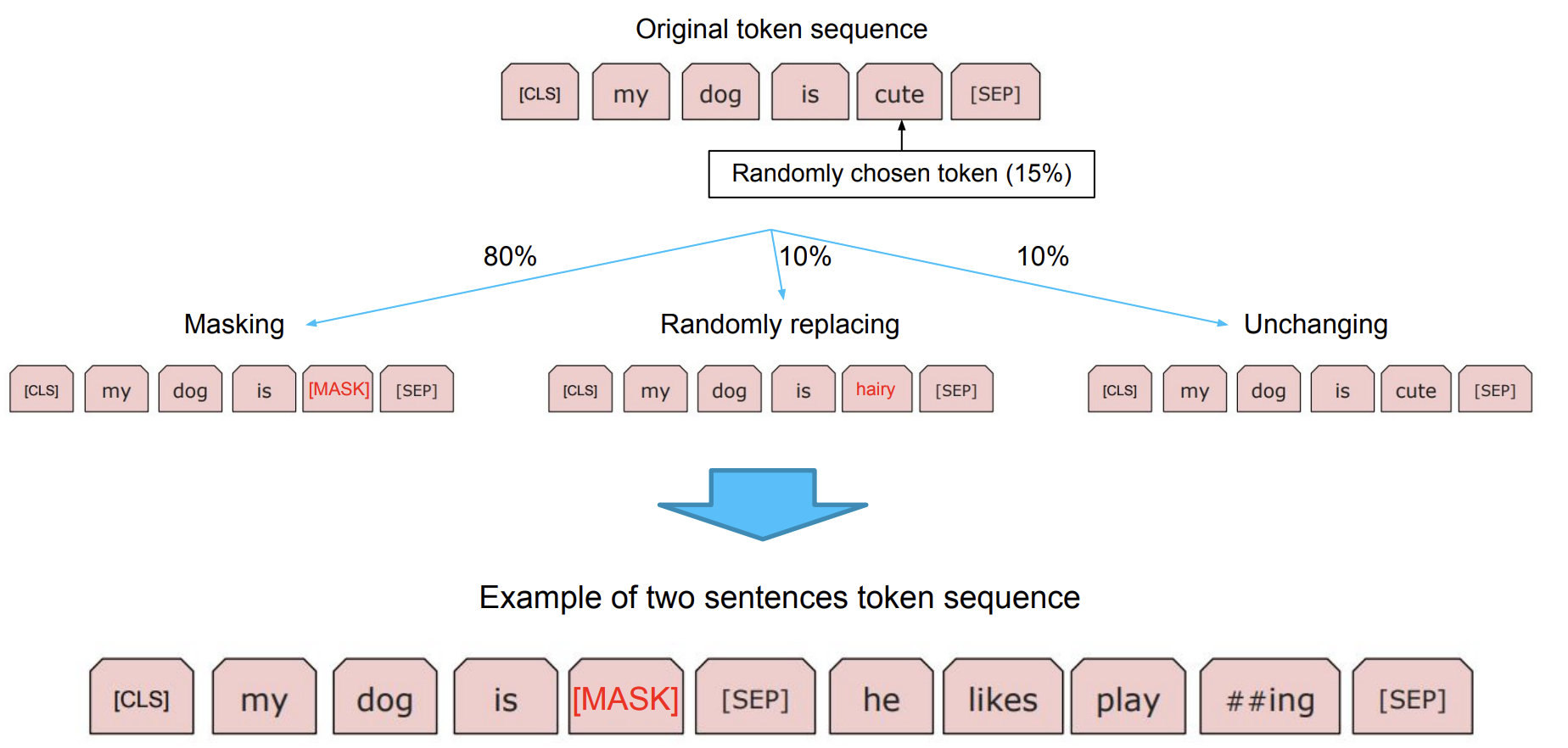
BERT 모델 학습
도메인 특화 task의 경우, 도메인 특화 된 학습 데이터만 사용하는 것이 성능이 더 좋다.
단일 문장 분류 Task
- 문장 분류
- 감정분석
- 주제 라벨링
- 언어 감지
- 의도 분류
- 관계 추출
BERT의 [CLS] token vector를 classification하는 Dense layer 사용
두 문장 관계 분류 Task
주어진 2개의 문장에 대해, 두 문장의 자연어 추론과 의미론적인 유사성을 측정하는 task
-
Natural Language Inference(NLI)
- 언어모델이 자연어의 맥락을 이해할 수 있는지 검증하는 task
- 전제문장(Premise)과 가설문장(Hypothesis)을 Entailment(함의), Contradiction(모순),
Neutral(중립) 으로 분류
-
Semantic text pair
- 두 문장의 의미가 서로 같은 문장인지 검증하는 task
-
BERT를 활용한 두 문장 관계 분류 방법
1. Sent A와 Sent B의 [CLS] token 임베딩 값을 이용해 유사도 비교
분류의 대상이 되는 모든 문장들을 미리 임베딩하여 저장, inference 대상이 되는 문장 1개만 임베딩하여 비교
2. [SEP] token을 이용해 두 문장 관계 분류 학습
문장의 관계 분류를 위해 학습된 모델로, 좋은 성능이 나타날 수 있습니다. 하지만, inference 시, 모든 조합들을 새롭게 계산해야하여 시간이 오래걸릴 수 있습니다.
3. Sentence BERT
동일한 BERT 모델이 각각의 Sent A, Sent B를 임베딩하여, 임베딩 벡터를 이용해 분류 혹은 유사한 정도를 예측하도록 학습, 결과적으로 BERT 모델이 문장의 의미를 더 정확하게 임베딩할 수 있도록 학습
문장 토큰 분류 Task
주어진 문장의 각 Token이 어떤 범주에 속하는지 분류하는 task
- Named Entity Recognition(NER)
- 개체명 인식은 문맥을 파악해서 인명, 기관명, 지명 등과 같은 문장 또는 문서에서 특정한 의미를 가지고 있는 단어 또는 어구(개체) 등을 인식하는 과정을 의미한다.
- Part-of-speech tagging(POS TAGGING)
- 품사란 단어를 문법적 성질의 공통성에 따라 언어학자들이 몇 갈래로 묶어 놓은 것이다.
- 품사 태깅은 주어진 문장의 각 성분에 대하여 가장 알맞는 품사를 태깅하는 것을 의미한다.
문장 토큰 분류 모델을 학습하기 위해서는 형태소 단위의 토큰을 음절 단위의 토큰으로 분해하고, Entity tag 역시 음절 단위로 매핑시켜 주어야 한다.
GPT 언어 모델
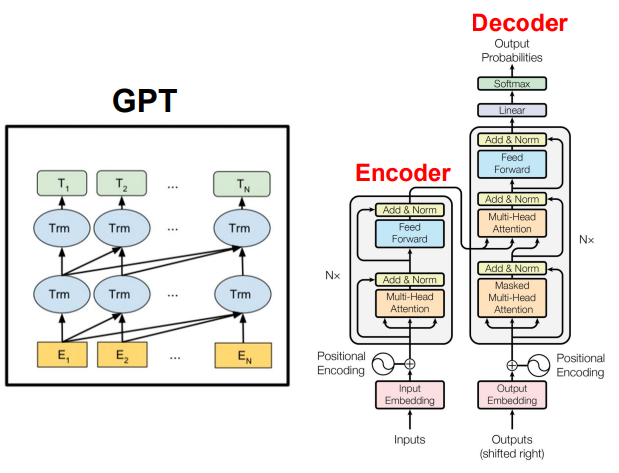
- 성능이 좋은 디코더이며 적은 양의 데이터에서도 높은 분류 성능을 보였다.
- 다양한 자연어 task에서 SOTA를 달성하였으며 Pre-train 언어 모델의 새 지평(BERT)을 열었다.
- Fine-tuning을 통해 pre-train 모델을 하나의 task에 적합한 형태로 만드는 것이 아닌 Few-shot, One-shot, Zero-shot 등을 제시했다.
- 하지만 Weight update가 없기에 새로운 지식 학습이 없으며 text를 통한 학습이 진행되었기에 멀티 모달 정보가 부족하다.
GPT 기반 자연어 생성 방법
-
Greedy Search
- 단순히 가장 높은 확률을 가진 단어를 다음 단어로 선택한다.
-
Beam Search
- Beam search는 각 Time step에서 가장 확률이 높은 Hypotheses의 num_beams를 유지하고 결국 전체 확률이 가장 높은 hypothesis를 선택하는 것으로 숨겨진 높은 확률 Word sequence를 놓칠 위험을 줄입니다
- 모든 Beam Hypotheses가 EOS토큰에 닿으면 생성이 완료되도록 num_beams > 1 과 eqrly_stopping=True로 파라미터를 설정합니다.
beam_output = model.generate( input_ids, max_length=50, num_beams=5, early_stopping=True )
-
Greedy와 Beam Search 방식은 Word sequence를 반복하는 문제를 포함합니다.
-
단순한 해결법은 Paulus et al. (2017)과 Klein et al. (2017)의 논문에서 제안된 n-grams 패널티를 도입하는 것입니다. 가장 일반적인 n-grams 패널티는 이미 나타난 n-gram에 대해 다음 단어로 생성될 확률을 0으로 설정하여 두번 나타나지 않도록 하는 방법입니다.
-
no_repeat_ngram_size=2을 설정한다면 2-gram이 두번 나타나는 것을 막을 수 있습니다.
beam_output = model.generate( input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, early_stopping=True ) -
n-gram 패널티는 신중하게 사용되어야 합니다. 예를 들면 city New York에 대해 생성된 기사는 n-gram을 사용하지 않는 것이 좋습니다. 2-gram을 사용하게 될 경우 시의 이름이 전체 텍스트에서 한 번만 나타나기 때문입니다.
-
Beam search의 또 다른 중요한 특징은 생성된 Top beam을 비교하여 목적에 가장 적합한 Beam을 선택할 수 있다는 것입니다.
-
Transformer에서 num_return_sequences 파라미터를 return 해야 하는 최대 num_beams 보다 작거나 같도록 설정합니다. num_return_sequences <= num_beams로 설정된 코드를 확인할 수 있습니다.
beam_outputs = model.generate( input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, num_return_sequences=5, early_stopping=True ) """ Output: ---------------------------------------------------------------------------------------------------- 0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again. I've been thinking about this for a while now, and I think it's time for me to take a break 1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again. I've been thinking about this for a while now, and I think it's time for me to get back to 2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again. I've been thinking about this for a while now, and I think it's time for me to take a break 3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again. I've been thinking about this for a while now, and I think it's time for me to get back to 4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again. I've been thinking about this for a while now, and I think it's time for me to take a step """ -
Beam search은 반복 생성 문제에 취약합니다. 특히 Story Generation Task에서 n-gram또는 기타 패널티를 통해 문장을 제어하는 것이 어렵습니다. 왜냐하면 "반복이 없는 구문"과 "n=gram반복 주기" 사이에서 적당한 trade-off를 찾기 위해 많은 finetuning이 필요하기 때문입니다.
-
Beam search는 Machine translation 또는 Text summarization처럼 원하는 문장 생성 길이가 예측 가능한 Task에서는 잘 작동할 수 있습니다. 하지만 Dialog 또는 Story Generation Task처럼 출력길이가 크게 달라질 수 있는 개방형 생성에서는 원활하게 작동하지 않습니다. ( Murray et al. (2018), Yang et al. (2018))
-
Ari Holtzman et al. (2019) 논문에 따르면 고품질 인간 언어는 높은 확률의 다음 단어 분포를 따르지 않는다고 주장합니다. 쉽게 말하자면 인간입장에서 우리는 지루하거나 예측 가능한 문장이 아니라 우리를 놀라게 할 수 있는 문장생성을 원한다고 합니다. 저자는 모델이 인간 텍스트 대비 beam search text를 그래프로 보여주면서 beam search text가 그다지 놀랍지 않은 문장이라는 것을 보여줬습니다.
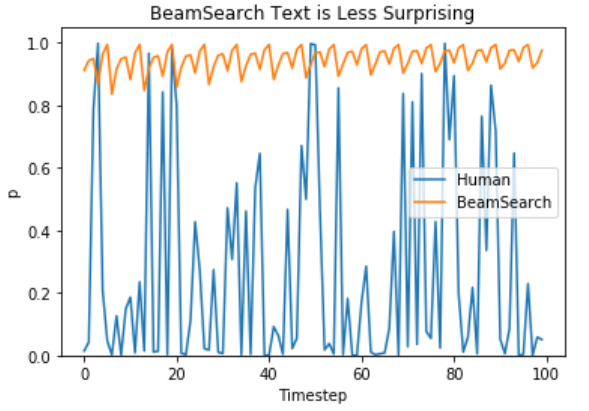
-
-
Sampling
- 가장 기본적인 형태의 Sampling은 조건부 확률 분포에 따라 다음 단어 wt 를 무작위로 선택하는 것을 의미합니다.
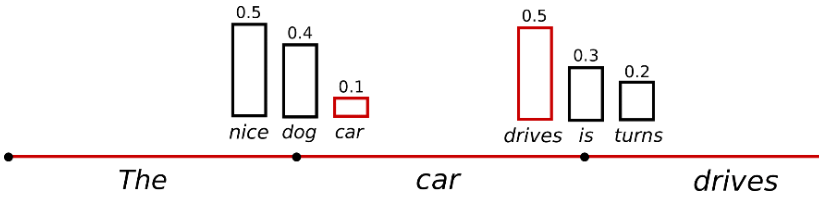
- Sampling을 이용한 언어생성은 더이상 결정론적이지 않습니다. 단어 는 조건부확률 에서 샘플링 된 후, 에서 를 샘플링 합니다.
sample_output = model.generate( input_ids, do_sample=True, # 완전 random sampling max_length=50, top_k=0 # w/o top_k 추출 )-
흥미롭게도 본문은 괜찮은 것 같지만 자세히 보면 매우 일관성 없는 문장입니다. 3-grams의 new hand sense 와local batte harness 라는 문장은 이상하고 사람이 쓴것처럼 보이지 않습니다. 이것은 sampling word sequences를 할때 모델이 일관성없이 횡설수설하는 문장을 발생시키는 큰 문제입니다. (Ari Holtzman et al. (2019)).
-
한가지 트릭은 softmax. 의 이른바 temperature를 낮추어 분포 P(w|w1:t−1) 를 더 선명하게 만드는 것입니다. 높은 확률의 단어의 가능성은 증가시키고 낮은 확률의 단어 가능성은 감소시키는 효과가 있습니다.
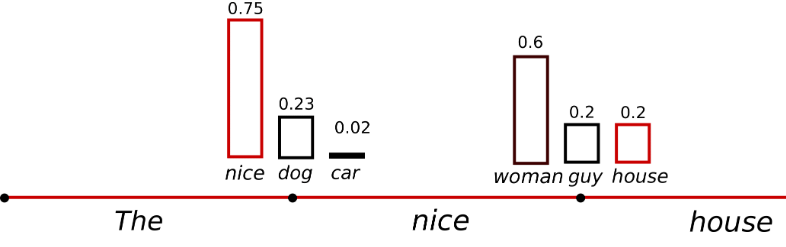
sample_output = model.generate( input_ids, do_sample=True, max_length=50, top_k=0, temperature=0.7 ) - 가장 기본적인 형태의 Sampling은 조건부 확률 분포에 따라 다음 단어 wt 를 무작위로 선택하는 것을 의미합니다.
-
Top-K Sampling

-
지금까지 기법중 가장 인간적으로 보이는 텍스트를 생성했습니다. Top-K Sampling의 한 가지 우려되는 점은 다음 단어 확률 분포 P(w|w1:t−1) 에서 필터링된 단어 수를 동적으로 조정하지 않는 점입니다. 예를들면 위 그림에서 첫번째 step의 단어들은 전반적으로 평평한 분포에서 Sampling 되지만, 두번째 step의 어떤 단어들은 매우 Sharp한 분포에서 Sampling 될 수 있기 때문에 문제가 될 수 있습니다.
-
Step t=1 에서 Top-K은 꽤 합리적인 후보처럼 보이는 "people", "big", "house", "cat" 을 샘플링하는 가능성을 배제합니다. 반면에 Step t=2 에서 단어 Sample pool에 단어 "down", "a" 와 같은 부적절한 단어를 포함합니다. 그러므로 Sample pool이 고정크기 K로 제한되면 모형이 Sharp한 분포에서 횡설수설한 단어를 고를 위험이있고 평평한 분포에서는 문장의 창의성이 제한될 수 있습니다. (Ari Holtzman et al. (2019))
-
-
Top-p (nucleus) sampling

- 이론적으로는 Top-p가 Top-K보다 더 성능이 좋아 보이지만, 두 방법 모두 실제로 잘 작동합니다. Top-p는 또한 Top-K와 함께 사용될 수 있는데, 이것은 매우 낮은 순위의 단어를 피하면서도 일부 동적 선택을 허용할 수 있습니다.
-
Conclusion
- ad-hoc decoding방법에 따르면 Top-p와 Top-k sampling은 기존 Greedy-, Beam search 보다 개방형 언어생성에서 더 유창한 문장을 생성하는 것으로 보입니다.
- 그러나 Top-p와 Top-k sampling 또한 Greedy-, Beam search 처럼 반복적 Word sequencd에 대한 문제가 발생합니다. (Welleck et al. (2020))
- (Welleck et al. (2019))에 따르면 Beam search가 모델 트레이닝 목적함수를 잘 조정한다면 Top-p보다 더 유찬한 텍스트를 생선한다는 연구도 있습니다.
- 개방형 언어생성은 빠르게 발전하는 분야이며, 무엇이 적합하다고 단정할 수 없으므로 특정 사용 사례에서 가장 잘 작동하는 방법이 무엇인지 고려해야 합니다.
- 언어별, 모델별로 최적의 생성 방식을 찾아내야 합니다.
Few-shot & Zero-shot
- Zero-shot

- Few-shot

BERT 이후의 다양한 LM
-
XLNet
- BERT의 경우 [MASK] 토큰을 독립적으로 예측하기에 Token 사이의 관계 학습이 힘들다.
- 또한 Embedding length의 한계(Positional encoding)로 segment간 관계 학습 불가능
- GPT의 경우 단일 방향성으로만 학습하는 한계가 존재한다.
- 이를 해결하기 위해 XLNet은 Relative positional encoding과 Permutation language modeling을 사용한다.
- Relative positional encoding : BERT와 같이 0,1,2,3 등으로 위치를 표현하는 것이 아니라, 현재 token의 위치 대비 0번째, 1번째 등 상대적 거리 표현법을 사용하여 sequence 길이에 제한을 없앴다.
- 기존의 단일 방향으로 학습하는 것이 아닌 token에 모든 순열 조합을 생성하여 학습한다.
- BERT의 경우 [MASK] 토큰을 독립적으로 예측하기에 Token 사이의 관계 학습이 힘들다.
-
RoBERTa
- BERT 구조에서 학습 방법을 변경
- Model 학습 시간 증가, Batch Size 증가, Train data 증가
- Next Sentence Prediction 제거 : Fine-tuning과 관련이 없으며 너무 쉬운 task라 오히려 성능 하락
- Longer sentence 추가
- Dynamic masking : 똑같은 텍스트 데이터에 대해 masking을 10회 다르게 적용하여 학습
- task가 어려운 문제를 학습한 모델이 일반적으로 성능이 좋음
-
BART
- Transformer Encoder-Decoder 통합 LM
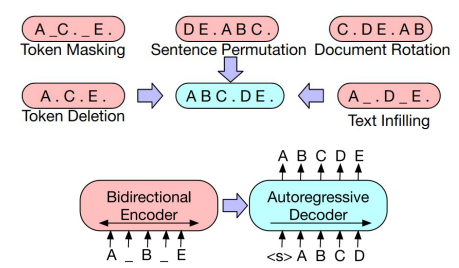
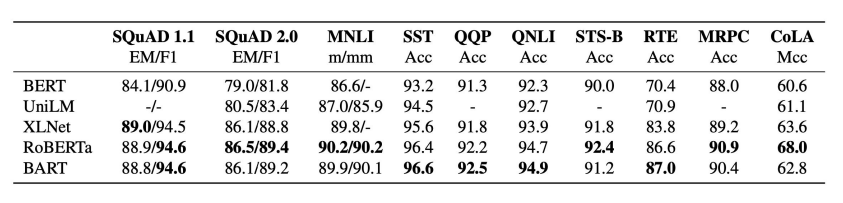
- 추후 정리 예정
- Transformer Encoder-Decoder 통합 LM
-
T-5
- Transformer Encoder-Decoder 통합 LM
- 추후 정리 예정
-
Meena
- 대화 모델을 위한 LM
- 소셜 미디어의 데이터(341GB, 400억개의 단어)를 이용하여 26억개의 파라미터를 가진 신경망 모델을 이용한 end-to-end multi-turn 챗봇
- 챗봇의 평가를 위한 새로운 Metric인 SSA(Sensibleness and Specificity Average)를 제시
-
Controllable LM
- Plug and Play Language Model(PPLM)
- 내가 원하는 단어들의 확률이 최대가 되도록 이전 상태의 vector를 수정
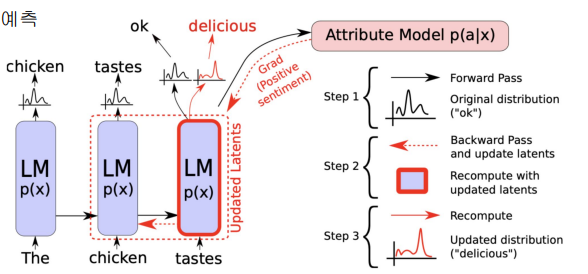
- 확률 분포를 사용하는 것이기 때문에, 중첩도 가능 (기쁨 + 놀람 + 게임)
- 특정 카테고리에 대한 감정을 컨트롤해서 생성 가능
- 내가 원하는 단어들의 확률이 최대가 되도록 이전 상태의 vector를 수정
- Plug and Play Language Model(PPLM)
Multi-modal Language Model
- LXMERT
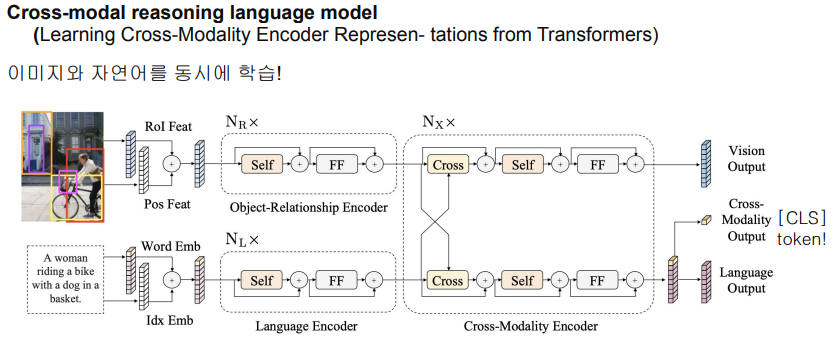
- 이미지 feature - 자연어 feature가 하나의 모델에 반영됨
- ViLBERT
- 자연어 token과 이미지 token을 [SEP]토큰 기준으로 segment 차이를 두어 학습 후 [CLS] 토큰을 통해 분류
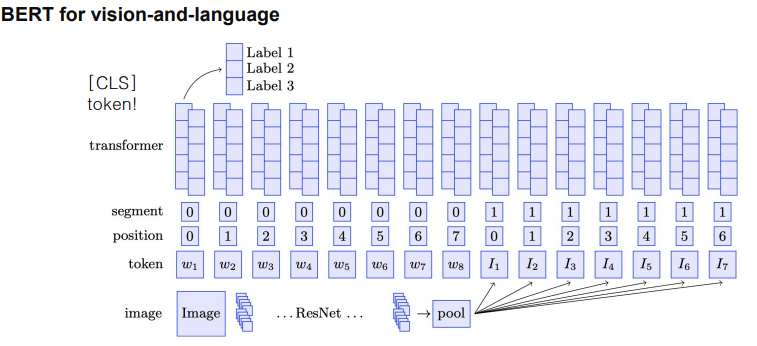
- 자연어 token과 이미지 token을 [SEP]토큰 기준으로 segment 차이를 두어 학습 후 [CLS] 토큰을 통해 분류
- DALL-E, CLIP 등
출처 : 네이버 커낵트 부스트캠프
