
1. 프로젝트 개요
- 위키피디아 원시 말뭉치를 활용하여 관계 추출 태스크에 쓰이는 주석 코퍼스 제작
- Relation set의 구성 및 정의, 가이드라인 작성, 파일럿 및 메인 어노테이션, 그리고 간단한 모델 Fine-tuning의 과정을 통해 실제 데이터 제작의 workflow 경험
- 정밀한 가이드라인 제작의 중요성과 inter-annotator agreement(IAA)의 개념 체득
- 2022.12.07(수) ~ 2022.12.16(금) 13:00
2. 데이터 개요
2.1 데이터 설명
- 자동차와 관련된 부품(타이어, 브레이크, 엔진 등), 브랜드(기아, 볼보, 아우디 등) 등의 키워드 등을 중심으로 정보를 포함하는 데이터이다. 데이터는 부스트캠프 측으로부터 자동차 주제에서 도출된 키워드들을 위키피디아(CC BY-SA 3.0) 문서 제목을 기반으로 수집해 제공받았다.
3. RE 데이터 제작
3.1 Relation Map
‘자동차’ 주제의 문서들에서 relation extraction을 할 때 고려할 만 한 "Relation"과 해당하는 "Entity type"들을 직접 선정하는 작업을 진행하였다. 주어진 데이터 파일(txt-file)은 총 67개로, 939 rows(line)을 확인할 수 있었다. 팀원 당 188 rows를 할당하여 데이터를 검토 후, “Relation”과 "Entity type"을 논의하였다. 1차 논의로 Relation Map 및 가이드라인을 작성하였고, Pilot Tagging을 진행하며 Relation에 대해 재정의 후, 최종 Relation, Entity type를 결정하였다.
3.2 가이드라인
가이드라인
자동차 분야의 관계 추출 태스크를 위한 데이터 제작 과정을 설명하기 위해 작성하였다. 먼저 관계의 방향성, 관계없음 등의 Annotation 가이드라인을 예시와 함께 작성하고, Annotation 태깅 과정에서 발생할 수 있는 Data Error 등 관리자에게 보고가 필요한 사항 등을 정리했다. 마지막으로 태깅 과정에서 팀원들 간 질문이 나왔거나 함께 합의한 부분은 FAQ에 상세하게 정리해 누구나 쉽게 궁금증을 해결할 수 있도록 했다.
4. Tagging using Tagtog
4.1 문장 업로드
한 document는 의미가 통하는 한 개~3개 정도의 문장을 하나로 두었고, 한 document내에는 두 개의 entity만 존재하는 것을 원칙으로 하였습니다.
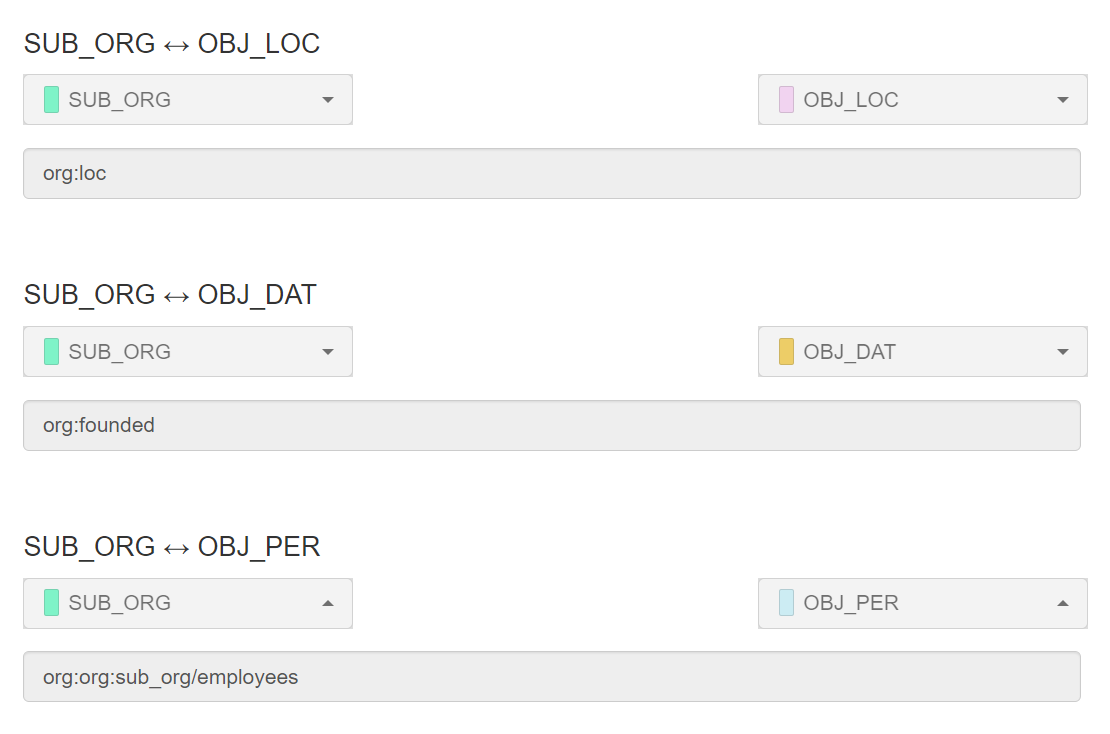
4.2 Entity와 relation 설정
Tagging에 필요한 모든 entity와 relation을 설정해주었습니다. 또한 no_relation용 entity인 SUB_no, OBJ_no 또한 설정해주었고, relation 또한 설정해주었습니다.

4.3 Tagtog ann.json csv 파일로 변환
Tagging이 완료된 json 파일은 다음과 같은 형식을 띄고 있다.
{
"annotatable": {
"parts": [
"s1v1"
]
},
"anncomplete": false,
"sources": [],
"metas": {},
"entities": [
{
"classId": "e_1",
"part": "s1v1",
"offsets": [
{
"start": 0,
"text": "크라이슬러"
}
],
"coordinates": [],
"confidence": {
"state": "pre-added",
"who": [
"user:daniel0801"
],
"prob": 1
},
"fields": {},
"normalizations": {}
},
{
"classId": "e_30",
"part": "s1v1",
"offsets": [
{
"start": 28,
"text": "닷지"
}
],
"coordinates": [],
"confidence": {
"state": "pre-added",
"who": [
"user:daniel0801"
],
"prob": 1
},
"fields": {},
"normalizations": {}
}
],
"relations": [
{
"classId": "r_42",
"type": "linked",
"directed": false,
"entities": [
"s1v1|e_1|0,4",
"s1v1|e_30|28,29"
],
"confidence": {
"state": "pre-added",
"who": [
"user:daniel0801"
],
"prob": 1
}
}
]
}딕셔너리 형식인 json파일을 DataFrame으로 변환 후, csv파일로 저장하여 우리가 원하는 데이터 형식으로 변환해주었다.
5. 데이터 검증
5.1 Fleiss’ Kappa 계산
목표 값인 0.7에 조금 미치지 못하는 값을 얻을 수 있었으며, 이를 바탕으로 일부 relation에 대한 수정을 진행했다.
5.2 모델 학습 및 결과
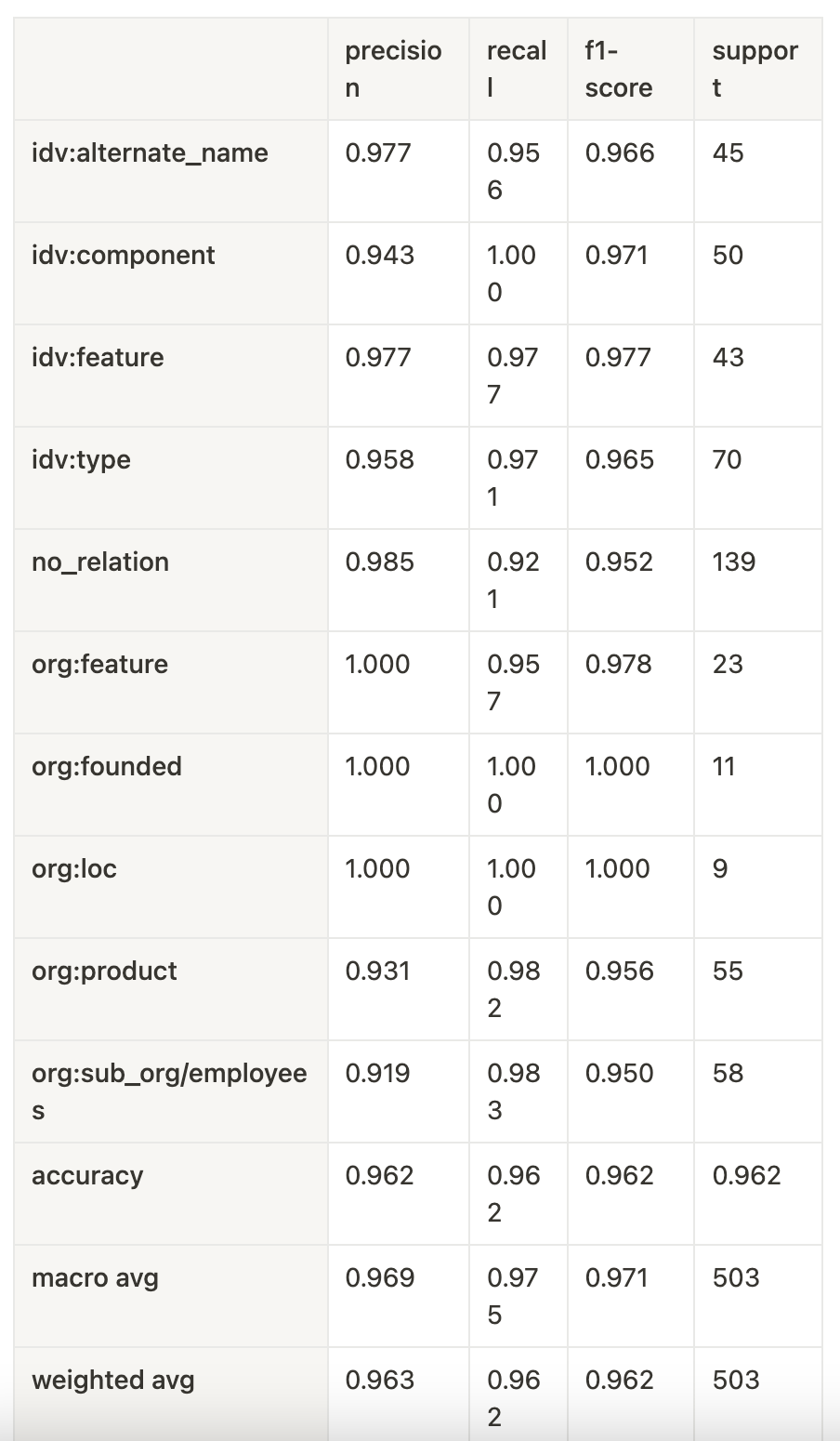
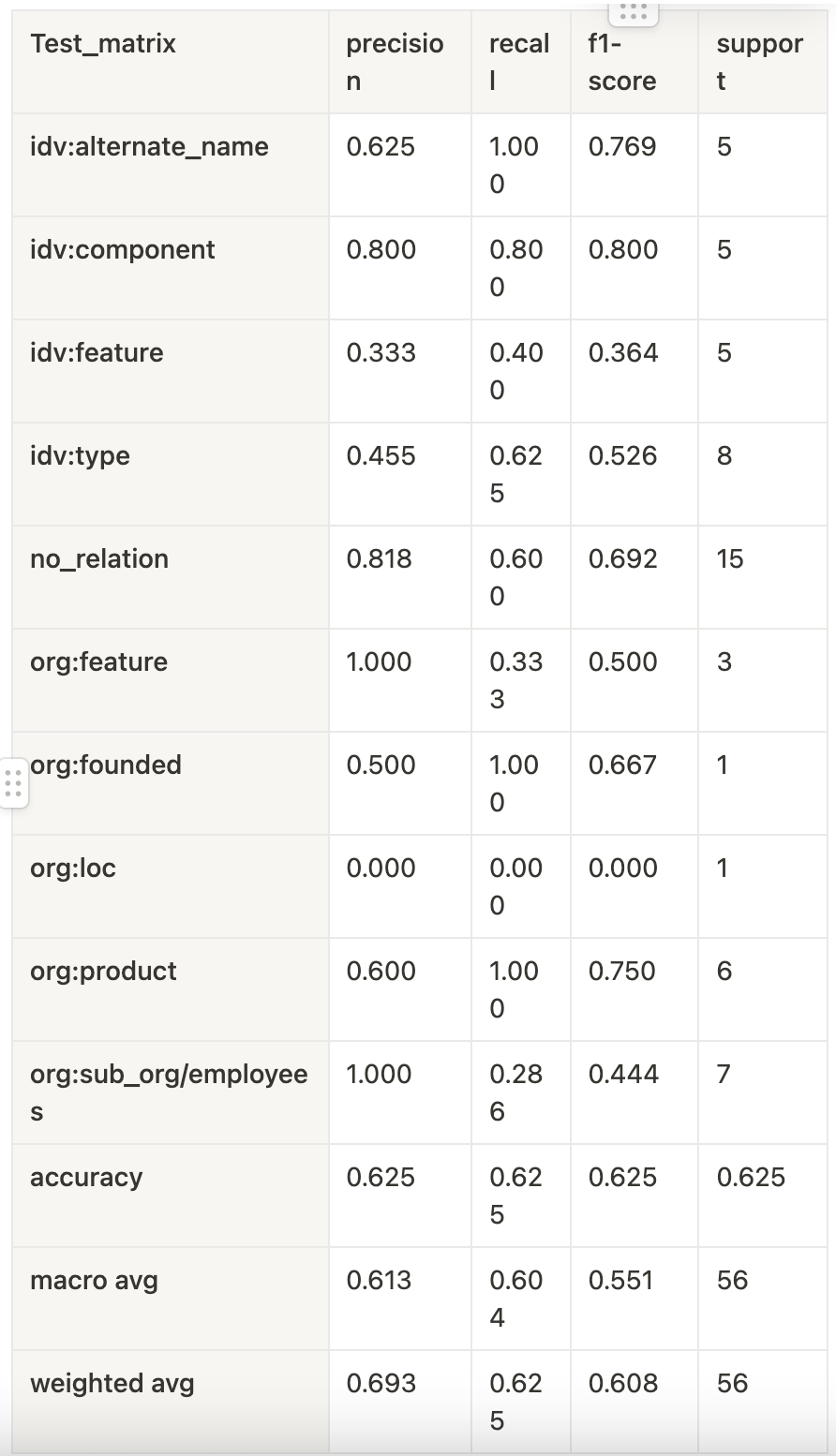
전체 503개의 데이터셋에 대해 8:1:1로 train:valid:test를 나누어 학습을 진행했다.
- Train

- Test

6. Discussion
- No_relation, org:sub_org/employees 의 2가지 relation에 대한 학습이 제대로 이루어지지 않았음을 확인했다.
- 애매한 label에 대해 idv:type 으로 예측하는 경우가 많았다. 이를 통해 guide line에서 idv:type에 대한 재정의가 필요함을 확인했다.
