
1. ODQA 프로젝트 개요
- MRC(Machine Reading Comprehension)란 주어진 지문을 이해하고, 주어진 질의의 답변을 추론하는 태스크이다.
- 본 ODQA 대회에서 모델은 질문에 관련된 문서를 찾아주는 “Retriever”와 찾아온 문서를 읽고 적절한 답변을 찾아주는 “Reader”로 구성된다.
- 데이터의 구성은 다음과 같다.

- 평가지표로는 Exact Match(EM), F1 Score를 활용한다.
- Exact Match (EM): 모델의 예측과, 실제 답이 정확하게 일치할 때만 점수가 주어진다. 즉 모든 질문은 0점 아니면 1점으로 처리된다.
- F1 Score: 부분 점수를 제공한다. 예를 들어, 정답은 "Barack Obama"지만 예측이 "Obama"일 때, 겹치는 단어도 있는 점을 고려해 부분 점수를 받을 수 있다.
2. 협업
Notion
프로젝트 일정 관리를 위해 노션의 칸반보드를 활용하여 각 팀별, 팀원별 태스크 진행 상황을 공유했다.
- Rule
- 칸반보드를 통한 진행상황 업데이트 및 카카오톡 공유
- Task Deadline 설정
- Progress를 통해 진행사항 공유
Git
GitFlow 전략을 활용하여 branch를 관리하였다.
- Rule
- develop에 기능 업데이트 시, UPDATE.md 추가
- P&R : Develop branch에 push or 수정 시, 코드리뷰
- Pre-commit : black, isort, autoflake
- GitHub action
- Pre-commit
- Git commit convention
3. 나의 역할
기획
기존 MRC Task에 대해 조사했으며, 적용할 아이디어를 모색했다.
- Retriever : BM25, Elastic Search, Top-K
- Dataset : KorQuad, AI HUB Wiki
- Method : Curriculum Learning
일정 관리
취합한 아이디어를 바탕으로 데드라인을 설정했다.
대회 초반 제출 기회를 활용하기 위해 베이스라인 코드와 sweep을 통해 하이퍼파라미터 튜닝한 모델을 초반에 제출하여 베이스 모델을 선정하는 아이디어를 제시했다.
모델
팀원과 함께 베이스라인 코드를 Pytorch Lighting으로 이식했다.
베이스 모델 선정을 위한 실험 과정을 제시하였으며 표를 통해 실험 결과를 공유했다.
모델 추론 결과와 Curriculum Learning의 전제가 동일하다는 것을 제시했다.
XAI 라이브러리인 SHAP를 제시하였으며 이를 추론 결과 분석에 활용하는 아이디어를 제시했다.
Curriculum learning에 적합한 LR Scheduler를 제시했다.
4. 프로젝트 진행 과정
1. EDA
Reader 데이터 분석
- Train & Valid 데이터 길이 분석
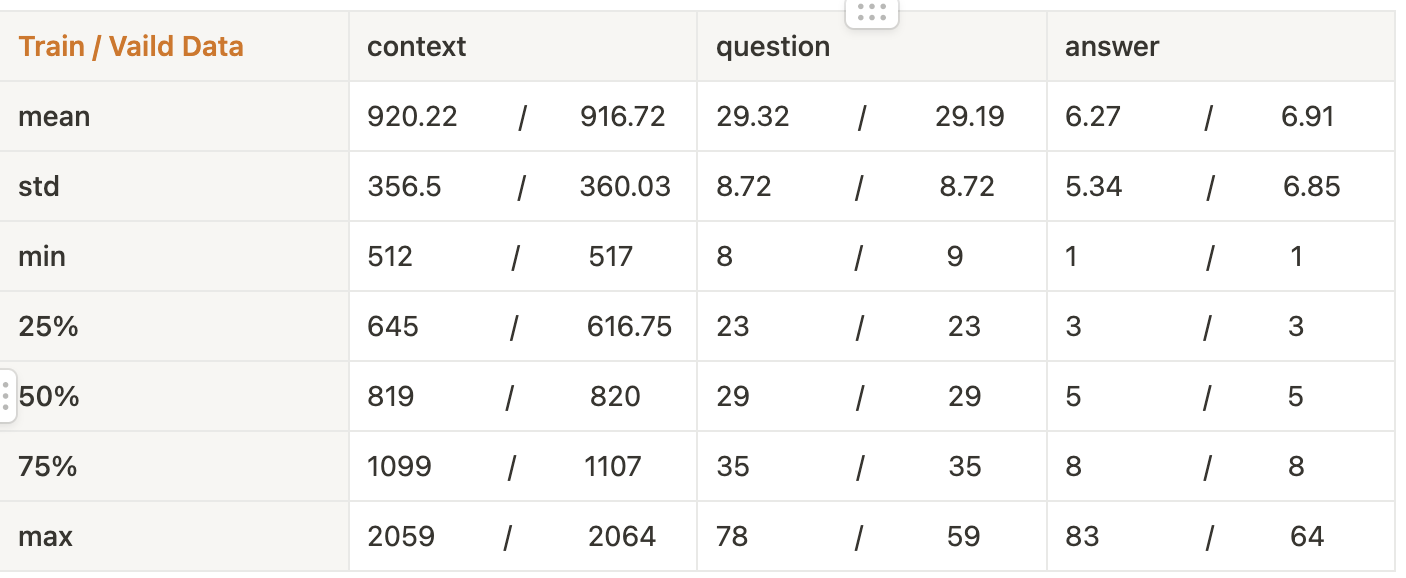
- Train과 Vaild 데이터 분포에 유의미한 차이가 없음을 확인
2. Pytorch Lightning 이식
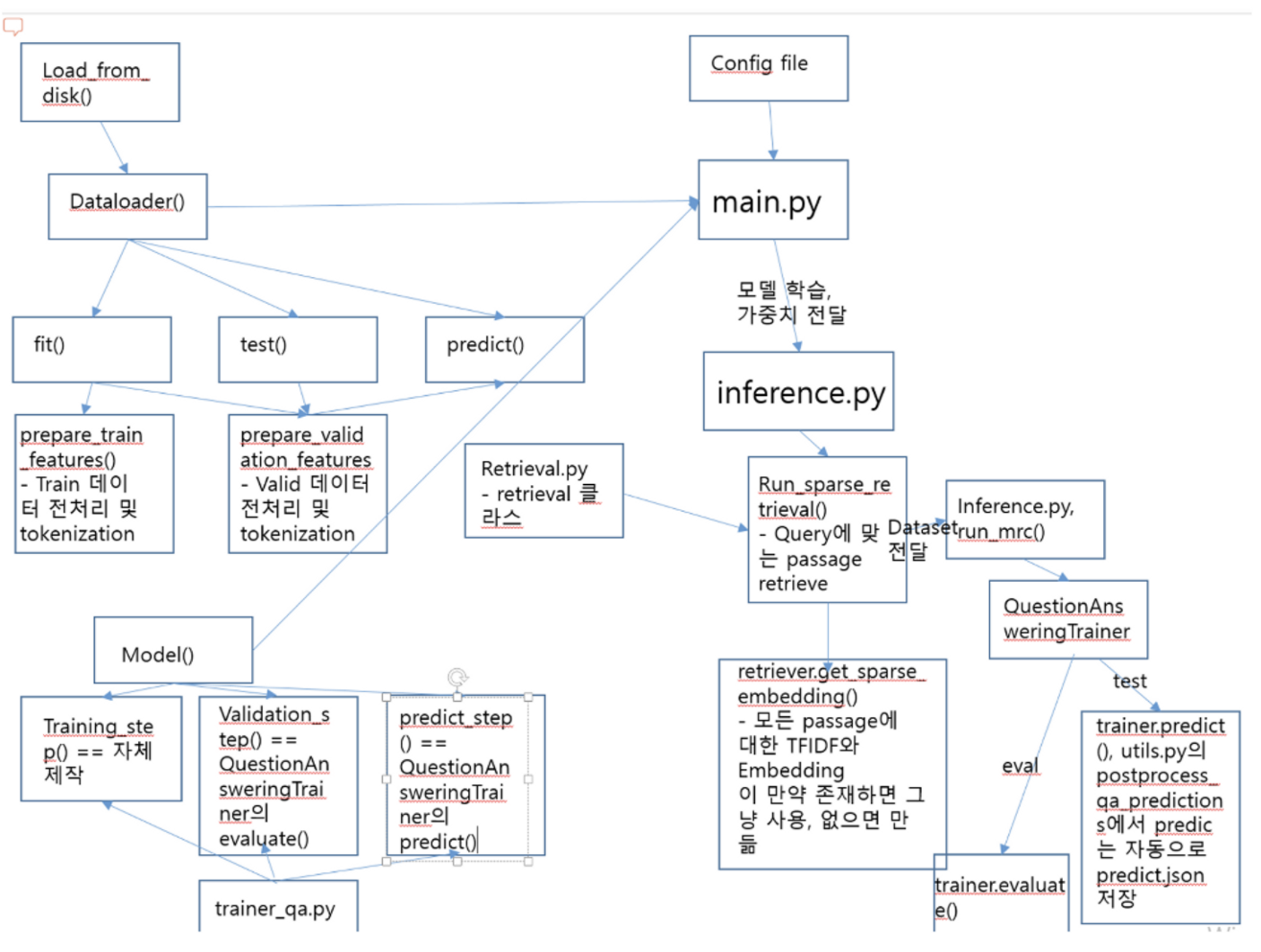
- 실험 편의 증대 및 유지보수를 위해 PL 이식
- PL Tuner 기능을 활용하여 LR, Batch size 초기값 세팅
3. Reader 백본 모델 선정
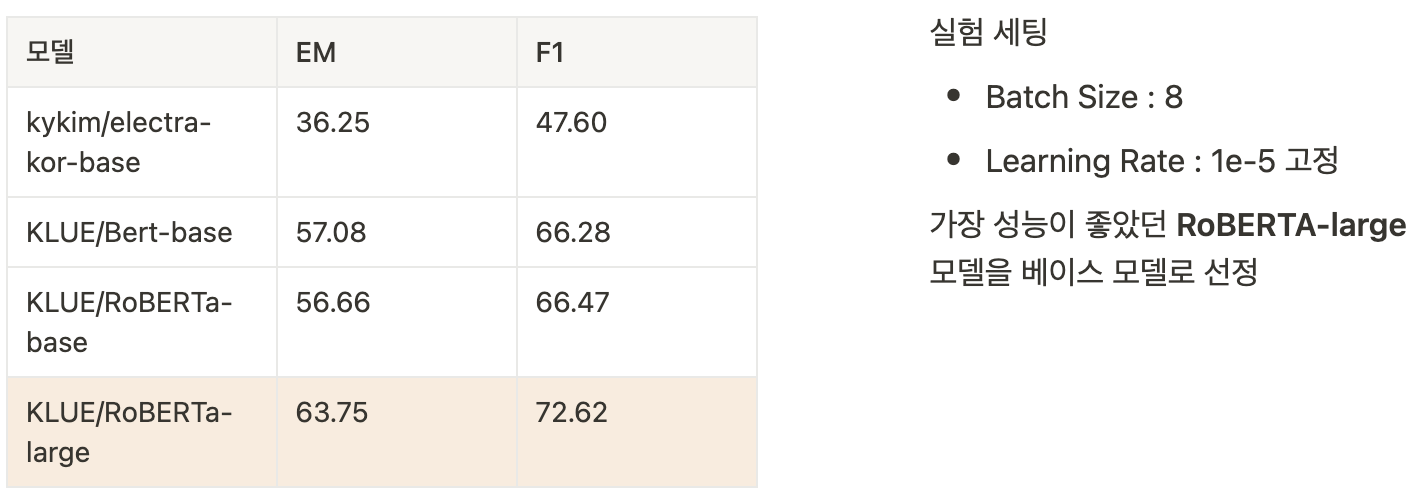
4. Retrieval 선정
후보군 선정
- Sparse Retrieval
- Term overlap을 정확하게 찾을 수 있기에 평가지표인 EM Score에 적합
- TF-IDF, BM25, Elastic Search
- Dense Retrieval (제외)
- 데이터셋 분석 결과 대부분의 정답이 context 내에 존재
- 평가지표가 EM Score이기에 해당 Retrieval의 장점인 semantic 정보 활용 의미가 퇴색
Retrieval 실험
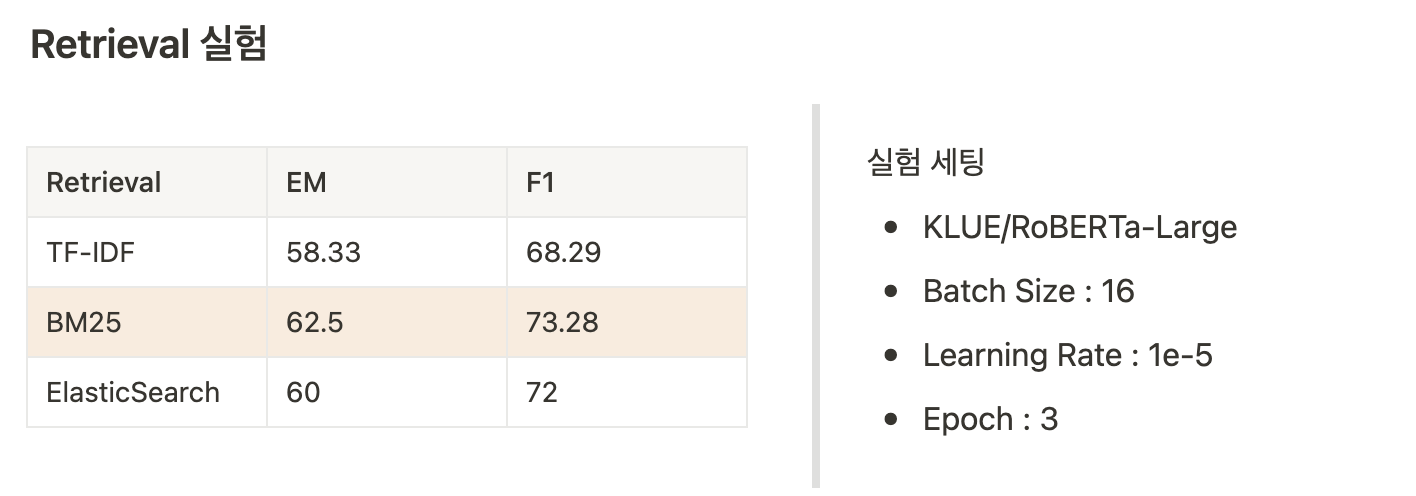
Top-K
- Retrieval의 결과물 개수(Top-K)를 10->40으로 변경
- EM Score : 42.5 -> 53.78
- F1 Score : 53.78 -> 63.03
5. Reader Experiment
5.1 Curriculum Learning
- 모델의 추론 결과 틀린 문장의 경우 평균 context의 길이가 약 10% 긴 점을 확인
- 논문의 전제인 sample length와 모델 추론 분석 결과가 일치함을 확인

- Context 길이 기준으로 데이터셋 오름차순 정렬
- EM Score : 41.25 -> 42.5
- F1 Score : 51.31 -> 53.78
5.2 TAPT
KorQuAD 1.0 : 1,550개의 위키피디아 문서에 대해서 10,649 건의 하위 문서들과 크라우드소싱을 통해 제작한 63,952 개의 질의응답 쌍 데이터 사용
AI HUB 일반 상식 : WIKI 본문내용과 관련한 질문과 질문에 대응되는 WIKI 본문 내의 정답 쌍 데이터 사용
TAPT 수행
- 외부 데이터셋 사전 학습, 1 epoch
- 학습 데이터셋 fine tuning
결과
- EM Score : 52.5 -> 58.33
- F1 Score : 63.03 -> 68.29
6. Ensemble
- Hard Voting 수행
- 다양한 Retrieval 결과를 합집합으로 사용 후 모델 소프트 앙상블
7. 프로젝트 결과

- 순위 : Private 2/14
- EM Score : 66.39
- F1 Score : 77.36

AI 새싹