
Base Code 분석
- 라이브러리
import argparse
import pandas as pd
from tqdm.auto import tqdm
import transformers
import torch
import torchmetrics
import pytorch_lightning as pl # Lightning을 사용- Dataset
class Dataset(torch.utils.data.Dataset):
def __init__(self,inputs,target=[]):
self.inputs = inputs
self.targets = targets
# 학습 및 추론 과정에서 데이터를 1개씩 꺼내오는 곳
def __getitem__(self,idx):
# 정답이 있다면 else문을, 없다면 if문 수행
if(self.targets) == 0:
return torch.tensor(self.inputs[idx])
else:
return torch.tensor(self.inputs[idx]), torch.tensor(self.targets[idx])
# 입력하는 개수만큼 데이터를 사용합니다.
def __len__(self):
return len(self.inputs)- Dataloader
class Dataloader(pl.LightningDataModule):
def __init__(self,model_name,batch_size,shuffle,train_path,dev_path,test_path,predict_path):
super().__init__()
self.model_name = model_name
self.batch_size = batch_size
self.shuffle = shuffle
self.train_path = train_path
self.dev_path = dev_path
self.test_path = test_path
self.predict_path = predict_path
self.train_dataset = None
self.val_dataset = None
self.test_dataset = None
self.predict_dataset = None
# HuggingFace에서 pretrained된 Tokenizer를 들고옴
# AutoTokenizer를 사용함으로 model_name을 넣어주면 HuggingFace에 저장된 모델을 자동으로 불러옴
self.tokenizer = transformers.AutoTokenizer.from_pretrained(model_name, max_length = (160)
self.target_columns = ['label']
self.delete_columns = ['id']
self.text_columns = ['sentence_1', 'sentence_2']
def tokenizing(self, dataframe):
data = []
# tqdm을 통해 for문 진행상황을 Progress Bar로 볼 수 있게 함
# iterrows를 통해 행 순환 반복 접근
# desc를 사용하여 tqdm 설명을 추가할 수 있습니다.
for idx, item in tqdm(dataframe.iterrows(), desc='tokenizing', total=len(dataframe)):
# 두 입력 문장을 [SEP] 토큰으로 이어붙여서 전처리합니다.
text = '[SEP]'.join([item[text_column] for text_column in self.text_column)
# add_special_tokens 옵션을 통해 [CLS], [SEP] 등을 자동으로 붙여준다.
outputs = self.tokenizer(text, add_special_tokens=True, padding='max_length', truncation=True)
data.append(outputs['input_ids'])
return data
def preprocessing(self,data):
data = data.drop(columns=self.delete_columns)
# 타겟 데이터가 없으면 빈 배열을 리턴
try:
targets = data[self.target_columns].values.tolist()
except:
targets = []
# 텍스트 데이터를 전처리
inputs = self.tokenizing(data)
return inputs,targets
# trainer.fit 및 trainer.test시 사용될 setup을 설정
def setup(self, stage='fit'):
if stage == 'fit':
# 학습 데이터와 검증 데이터셋을 호출합니다
train_data = pd.read_csv(self.train_path)
val_data = pd.read_csv(self.dev_path)
# 학습데이터 준비
train_inputs, train_targets = self.preprocessing(train_data)
# 검증데이터 준비
val_inputs, val_targets = self.preprocessing(val_data)
# train 데이터만 shuffle을 적용해줍니다, 필요하다면 val, test 데이터에도 shuffle을 적용할 수 있습니다
self.train_dataset = Dataset(train_inputs, train_targets)
self.val_dataset = Dataset(val_inputs, val_targets)
else:
# 평가데이터 준비
test_data = pd.read_csv(self.test_path)
test_inputs, test_targets = self.preprocessing(test_data)
self.test_dataset = Dataset(test_inputs, test_targets)
predict_data = pd.read_csv(self.predict_path)
predict_inputs, predict_targets = self.preprocessing(predict_data)
self.predict_dataset = Dataset(predict_inputs, [])
# Pytorch Lightning에서는 Dataloader을 반환해주는 방식으로 사용
def train_dataloader(self):
return torch.utils.data.DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=args.data.shuffle)
def val_dataloader(self):
return torch.utils.data.DataLoader(self.val_dataset, batch_size=self.batch_size)
def test_dataloader(self):
return torch.utils.data.DataLoader(self.test_dataset, batch_size=self.batch_size)
def predict_dataloader(self):
return torch.utils.data.DataLoader(self.predict_dataset, batch_size=self.batch_size) - Model
class Model(pl.LightningModule):
def __init__(self, model_name, lr):
super().__init__()
self.save_hyperparameters()
self.model_name = model_name
self.lr = lr
# 사용할 모델을 호출합니다.
# N21 Task의 일종인 STS이기에 AutoModelForSequenceClassification을 사용한다.
# 이 때 logit 한개를 output하면 되기에 num_labels = 1로 설정한다.
self.plm = transformers.AutoModelForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=model_name, num_labels=1)
# Loss 계산을 위해 사용될 L1Loss를 호출합니다.
self.loss_func = torch.nn.L1loss()
def forward(self,x):
# model에 input을 하고 나온 데이터 중 'logits'를 return
x = self.plm(x)['logits']
return x
def training_step(self,batch,batch_idx):
x,y = batch
logits = self(x) # foward
loss = self.loss_func(logits, y.float())
self.log("train_loss",loss) # loss를 train_loss로 로깅
return loss
def validation_step(self,batch,batch_idx):
x,y = batch
logits = self(x)
loss = self.loss_func(logits, y.float())
self.log("val_loss",loss)
self.log("val_pearson", torchmetrics.functional.pearson_corecoef(logits.squeeze(),y.squeeze())
return loss
def test_step(self,batch,batch_idx):
x,y = batch
logits = self(x)
self.log("test_pearson", torchmetrics.functional.pearson_corecoef(logits.squeeze(),y.squeeze())
def predict_step(self,batch,batch_idx):
x = batch
logits = self(x)
return logits.squeeze()
# 해당 Function을 통해 optimzer 설정 가능
# weight decay, LR Scheduler 등
def configure_optimizers(self):
optimizer = torch.optim.AdamW(self.parameters(),lr=self.lr)
return optimizer - 실행
if __name__ =='__main__':
# 하이퍼 파라미터 등 각종 설정값을 입력받습니다
# 터미널 실행 예시 : python3 run.py --batch_size=64 ...
# 실행 시 '--batch_size=64' 같은 인자를 입력하지 않으면 default 값이 기본으로 실행됩니다
parser = argparse.ArgumentParser()
parser.add_argument('--model_name', default='klue/roberta-large', type=str)
parser.add_argument('--batch_size', default=2, type=int)
parser.add_argument('--max_epoch', default=10, type=int)
parser.add_argument('--shuffle', default=True)
parser.add_argument('--learning_rate', default=1e-5, type=float)
parser.add_argument('--train_path', default='../data/train.csv')
parser.add_argument('--dev_path', default='../data/dev.csv')
parser.add_argument('--test_path', default='../data/dev.csv')
parser.add_argument('--predict_path', default='../data/test.csv')
args = parser.parse_args()
# dataloader와 model을 생성합니다.
# dataloader와 model을 생성합니다.
dataloader = Dataloader(args.model_name, args.batch_size, args.shuffle, args.train_path, args.dev_path,
args.test_path, args.predict_path)
model = Model(args.model_name, args.learning_rate)
# gpu가 없으면 'gpus=0'을, gpu가 여러개면 'gpus=4'처럼 사용하실 gpu의 개수를 입력해주세요
trainer = pl.Trainer(gpus=1, max_epochs=args.max_epoch, log_every_n_steps=1)
# Train part
trainer.fit(model=model, datamodule=dataloader)
trainer.test(model=model, datamodule=dataloader)
# 학습이 완료된 모델을 저장합니다.
torch.save(model, 'model.pt')개요
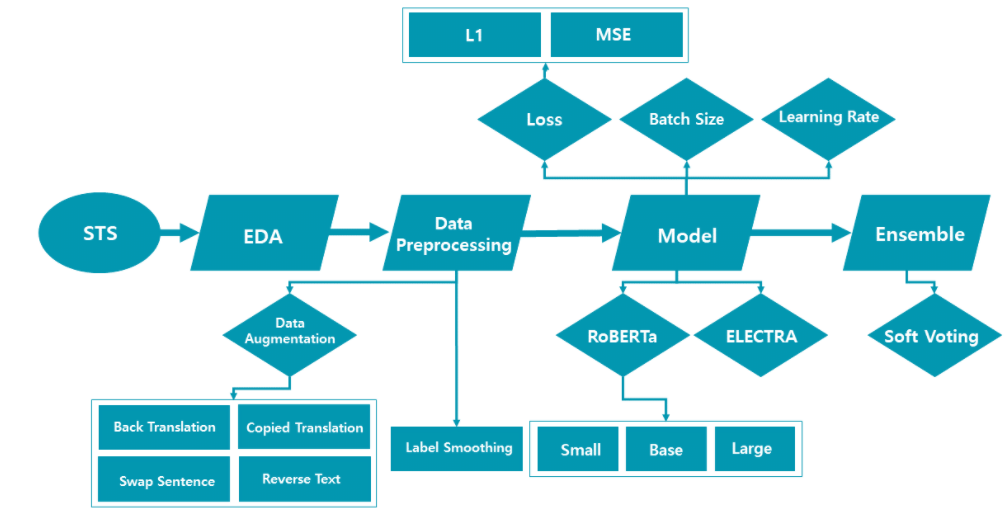
Base Pretrained Model 선택
- Ensemble에 사용될 모델과 Base 모델을 정하기 위해 다양한 모델을 테스트 했습니다.
- Default Setting
- Batch_size : 16
- LR : 1e-5
| 모델명 | Test_Pearson | Setting | 사용 여부 |
|---|---|---|---|
| klue/roberta-small | 0.8551 | X | X |
| klue/roberta-base | 0.8916 | X | X |
| klue/roberta-large | 0.9019 | B_S : 8, LR : 1e-6 | O |
| jhgan/ko-sroberta-multitask | 0.8477 | X | X |
| snunlp/KR-SBERT-V40K-klueNLI-augSTS | 0.8628 | X | X |
| sentence-transformers/paraphrase-multilingual-mpnet-base-v2 | 0.82 | X | X |
| beomi/KcELECTRA-base | 0.9113 | X | O |
| snunlp/KR-ELECTRA-discriminator | 0.9267 | X | O (SOTA) |
- Test 결과 Roberta Large가 가장 성능이 좋을 것이라 예측했지만 ELECTRA 계열이 성능이 가장 좋았습니다.
Baseline 수정
- CallBacks, EarlyStopping 추가
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
,,,
checkpoint_callback = ModelCheckpoint(monitor='val_pearson',
save_top_k=1,
save_last=True,
save_weights_only=False,
verbose=False,
mode='max')
earlystopping = EarlyStopping(monitor='val_pearson', patience=2, mode='max')
...
trainer = pl.Trainer(
gpus=-1,
max_epochs=cfg.train.max_epoch,
log_every_n_steps=cfg.train.logging_step,
logger=wandb_logger, # W&B integration
callbacks = [checkpoint_callback, earlystopping]
)- WandB, WandB Sweep 연동
import wandb
from pytorch_lightning.loggers import WandbLogger
wandb_dict = {
'user' : 'API_KEY'
}
...
parser.add_argument('--wandb_username', default='user')
parser.add_argument('--wandb_project', default='ELECTRA')
parser.add_argument('--wandb_entity', default='sts')
...
sweep_config = {
'method': 'bayes',
'parameters': {
'lr':{
'distribution': 'uniform', # parameter를 설정하는 기준을 선택합니다. uniform은 연속적으로 균등한 값들을 선택합니다.
'min':1e-5, # 최소값을 설정합니다.
'max':5e-5 # 최대값을 설정합니다.
},
'batch_size': {
'values': [16, 32]
},
},
'name' : 'snunlp-KcELECTRA-nof',
'metric':{'name':'val_pearson', 'goal':'maximize'},
'early_terminate' : {'type' : 'hyperband', 'max_iter' : 10, 's' : 2, 'eta': 3},
"entity" : 'sts',
'project' : 'ELECTRA'
}
...
# Sweep 안쓰는 경우
wandb.login(key = wandb_dict[cfg.wandb.wandb_username])
model_name_ch = re.sub('/','_',cfg.model.model_name)
wandb_logger = WandbLogger(
log_model="all",
name=f'{cfg.model.saved_name}_{cfg.train.batch_size}_{cfg.train.learning_rate}_{time_now}',
project=cfg.wandb.wandb_project,
entity=cfg.wandb.wandb_entity
)
...
# 스윕 적용
def sweep_train(config=None):
wandb.init(config=config)
config = wandb.config
dataloader = Dataloader(args.model_name, config.batch_size, args.shuffle, args.train_path, args.dev_path,
args.test_path, args.predict_path)
model = Model(args.model_name, config.lr)
wandb_logger = WandbLogger(
log_model="all",
name=f'{model_name_ch}_{config.batch_size}_{config.lr}_{args.time_now}',
project=args.wandb_project,
entity=args.wandb_entity
)
trainer = pl.Trainer(gpus=1,
max_epochs=10,
log_every_n_steps=5,
logger=wandb_logger,
callbacks = [checkpoint_callback, earlystopping]
)
trainer.fit(model=model, datamodule=dataloader)
trainer.test(model=model, datamodule=dataloader)
output_dir_path = 'output'
if not os.path.exists(output_dir_path):
os.makedirs(output_dir_path)
output_path = os.path.join(output_dir_path,
f'{model_name_ch}_{config.batch_size}_{config.lr}_{args.time_now}_model.pt')
torch.save(model, output_path)
sweep_id = wandb.sweep(
sweep=sweep_config, # config 딕셔너리를 추가합니다.
project=args.wandb_project,# project의 이름을 추가합니다.
)
wandb.agent(
sweep_id=sweep_id, # sweep의 정보를 입력하고
function=sweep_train, # train이라는 모델을 학습하는 코드를
count=7 # 총 5회 실행해봅니다.
)
- yaml, OmegaConf을 활용한 Shell 파일 생성
from xml.dom.minidom import Entity
from omegaconf import OmegaConf
...
class Model(pl.LightningModule):
def __init__(self, config):
super().__init__()
self.save_hyperparameters()
self.model_name = config.model.model_name
self.lr = config.train.learning_rate
...
if __name__ == '__main__':
# 하이퍼 파라미터 등 각종 설정값을 입력받습니다
# 터미널 실행 예시 : python3 run.py --batch_size=64 ...
# 실행 시 '--batch_size=64' 같은 인자를 입력하지 않으면 default 값이 기본으로 실행됩니다
parser = argparse.ArgumentParser()
parser.add_argument('--config',type=str,default='base_config')
args, _ = parser.parse_known_args()
cfg = OmegaConf.load(f'./config/{args.config}.yaml')
...
model = Model(cfg)
trainer = pl.Trainer(
gpus=-1,
max_epochs=cfg.train.max_epoch,
log_every_n_steps=cfg.train.logging_step,
logger=wandb_logger, # W&B integration
callbacks = [checkpoint_callback, earlystopping]
)- Shell
#!/bin/bash
CONFIGS=("config_1" "config_2")
config_length=${#CONFIGS[@]}
for (( i=0; i<${config_length}; i++ ));
do
echo ${CONFIGS[$i]}
python3 train_y.py \
--config ${CONFIGS[$i]}
done- Config
path:
train_path: ../data/train.csv
dev_path: ../data/dev.csv
test_path: ../data/dev.csv
predict_path: ../data/test.csv
data:
shuffle: True
augmentation: # adea, bt 등등
model:
model_name: beomi/KcELECTRA-base
saved_name: beomi/electra
train:
seed: 21
gpus: 1
batch_size: 32
max_epoch: 30
learning_rate: 3e-5
logging_step: 1
wandb:
wandb_username: user
wandb_project: sts
wandb_entity: sts
EDA
- 다양한 가설을 세웠습니다.
형태소 분석을 통한 전처리데이터 출처에 따른 처리문장 길이 분포 체크띄어쓰기 및 맞춤법 교정중복 데이터 체크Binary Label 분포 체크- Lable 분포 체크
- 데이터 불균형 체크
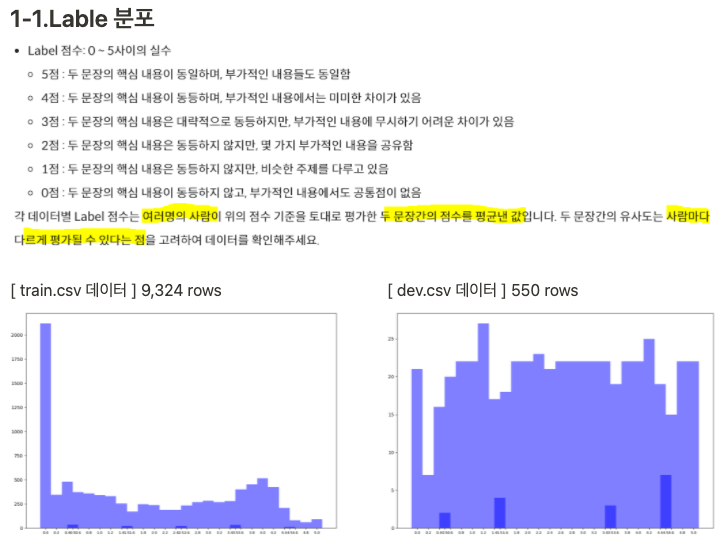
- 데이터 불균형 체크
Data Augmentation & pre-processing
- Back Translation
- 역 번역 시 부적절한 번역 결과와 발생하여 일관된 점수 기준이 중요한 STS Task에 적합하지 못하다고 판단하여 제외하였습니다.
- Copied Translation
- 해당 논문에서 영감을 얻어 사용하였습니다.
- Sentence 1을 Sentence 2로 복사하여, Label 5 데이터 셋 증강
- Train Dataset 분포 분석 결과 5 Label 데이터가 전체 데이터셋의 1%이기에 Sentence가 서로 같은 문장을 원 데이터셋에서 샘플링하여 5 Label 데이터를 추가하였습니다.
- Swap Sentence
- Sentence 1과 Sentence 2의 순서를 바꿔 증강
- Sentence 1과 Sentece 2의 Segment Embedding 값이 다르기에 변경 시 유의미한 데이터 증강이 될 것이라고 분석하였습니다. 시도한 방법 중 가장 효과가 좋았습니다.
- Reverse Text
- 문자를 역순으로 생성
- 단독 사용시 효과가 있었고 이를 통해 유의미한 노이즈 값을 생성할 수 있을 것이라 분석했지만 여러 기법과 함께 사용시 성능이 하락하여 제외하였습니다.
- Label Smoothing
- Train Dataset의 50% 이상이 0 Label 이기에 해당 Label을 50% 언더 샘플링 하였습니다.
- 이를 Copied Translation과 함께 사용할시 효과가 좋았습니다. 이를 원 분포인 Positive Skewness 분포에서 비교적 Uniform한 분포로 변경된 결과라고 분석하였습니다.
- 다음과 같은 다양한 기법들을 다양한 조건(비율, 기법 조합 등)으로 변경하며 Base Model에 적용하여 최적의 조합을 찾아내고자 하였습니다.
Optimization
- WandB Sweep을 사용하여 최적의 Hyperparameter을 찾기 위해 노력하였습니다.
- kr-ELECTRA의 경우 해당 조합이 증강 데이터를 적용했을 때 가장 성능이 좋았습니다.
- Loss : MSE
- LR : 3e-5
- Optimzer : AdamW
- Data : Label Smoothing, Copied Translation, Swap Sentence
- Val_Pearson : 0.9309
Ensemble 준비
- klue/roberta-large 최적화 시도를 하였습니다.
- Default 값인 LR : 1e-5를 사용할 경우 수렴하지 않는 문제가 발생하였습니다.
- klue/roberta-large의 경우 해당 조합이 가장 성능이 좋았습니다.
- Loss : MSE
- LR : 7e-6
- Optimzer : AdamW
- Data : Label Smoothing, Copied Translation, Swap Sentence
- Val_Pearson : 0.9256
Ensemble
- 평가 지표인 Pearson의 경우 선형이기에 Outlier에 취약한 특성이 있습니다. 이를 해결하기 위해 가중 평균을 도입, Outlier의 영향력을 줄였습니다.
- 앙상블은 소프트보팅 방식을 채용하였습니다.
- 각 모델의 성능을 가중치로 두어서 가중 평균을 구하는 방식으로 구현했습니다.
- 각 모델의 성능을 softmax 층에 통과시켜 나온 값과 각 모델이 출력한 logit 값을 곱하는 방식을 취했습니다.
- Swap Sentence 기법을 적용하여 Positive Skewness 분포인 데이터와 Copied Translation과 Label Smoothing을 적용하여 Uniform 분포를 가진 데이터를 학습한 모델을 앙상블하여 Test Dataset 분포에 의존적이지 않으며 General한 모델을 설계하였습니다.
- klue/roberta-large와 snunlp/KR-ELECTRA-discriminator을 앙상블하였습니다.
결과
<NLP 5조>
Pearson : 0.9368
등수 : 3등
- 데이터 분석을 통한 데이터 품질 개선(Undersampling, Data augmentation)
- 데이터셋에 적합한 Pretrained Model 선정 및 최적화
- 다양한 결과에 대한 앙상블(Soft Voting) 수행
출처 : Naver BoostCamp

AI 새싹