
-
Semantic Text similarity(STS)
- 기계를 통해 서로 구조적으론 다르지만, 의미가 유사한 문장을 구별할 수 있어야한다.
-
NLP Tasks
- 주제분류
- 감성분석
- 개체명분석
- 형태소분석
- 대화
- 번역
-
Sequence to Sequence(S2S) Learning
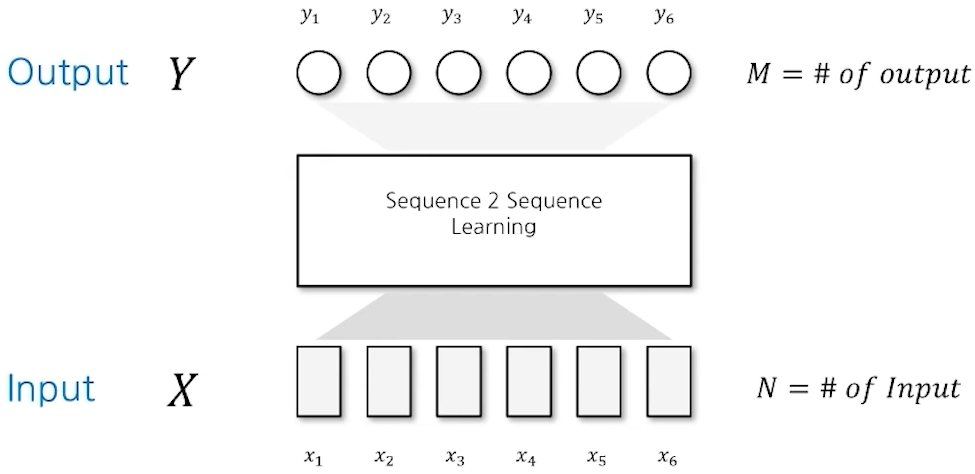
- S2S - Cases
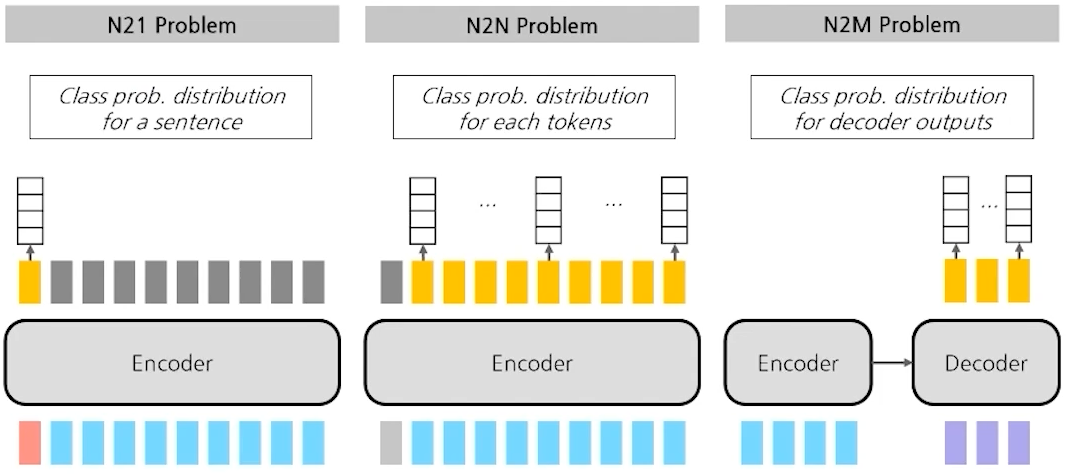
- N21 Problem
- Input : Sentence or Multiple Sentences
- Output : A Class prob. Distribution as output
- Topic Classification
- 주어진 텍스트 조각의 주제를 예측
- STS
- 두 문장 사이의 의미적 동등성의 정도를 측정(점수)
- Natural Language Inference
- 가설 문장과 전제 문장 간의 관계를 추론
- NLU에서는 문장 간의 함축과 모순을 이해
- 두 문장(가설과 전제 문장)이 입력
- 진실, 거짓, 미결정이 Class toekn(CLS)에 출력
- N2N Problem
- Input : Sentence or Multiple Sentences
- Output : Class prob. Distribution for each tokens
- Named Entity Recognition
- 구조화되지 않은 텍스트에서 개체명의 경계를 감지하고 유형을 분류
- 개체명은 사람, 위치, 조직, 시간 표현, 수량 및 금전적 가치와 같은 미리 정의
- 비정형 텍스트에서 지식을 추출하는 시스템을 구축하는데 개체명 인식이 필수적
- Morphology Analysis
- 입력되는 텍스트의 최소 형태소 단위를 찾는 것
- 형태소는 문을 구성하는 최소의 언어 단위
- 자연어 처리를 위한 단어의 최소단위인 형태소로 분리하기 위해 중요한 요소
- N2M Problem
- Input : Sentence or Multiple Sentences for Encoder and Decoder
- Output : Class prob. Distribution for each decoder outputs
- Machine Translation
- Dialogue Model
- Chatbot과 같이 사람과 대화하는 주고 받는 모델을 위한 문제
- Summarization
- Image Captioning
- N21 Problem
- S2S - Cases
-
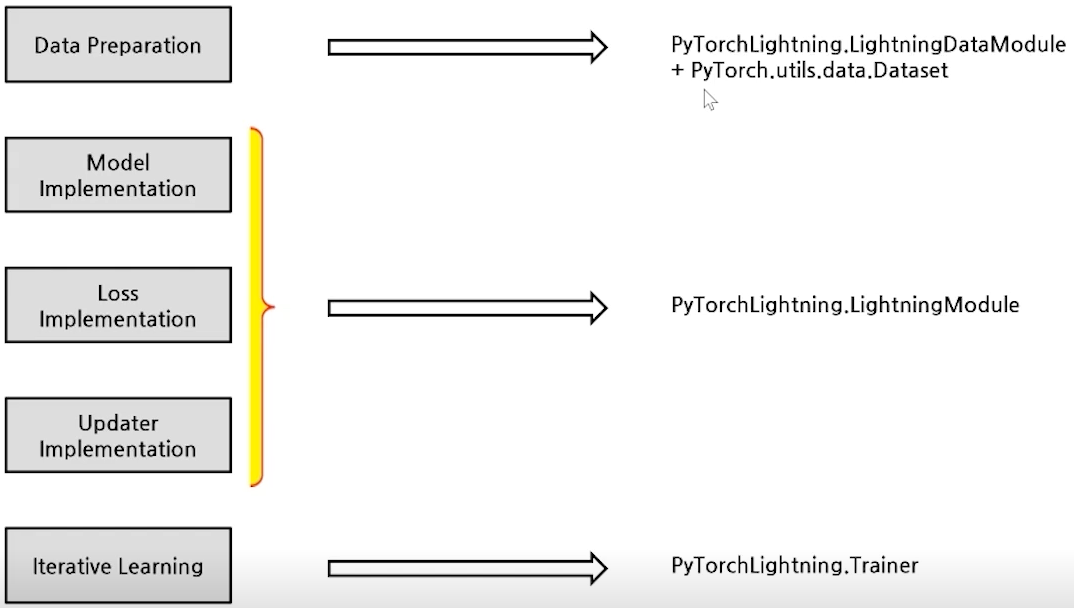
Pytorch Lightning
- Deep Learning Process
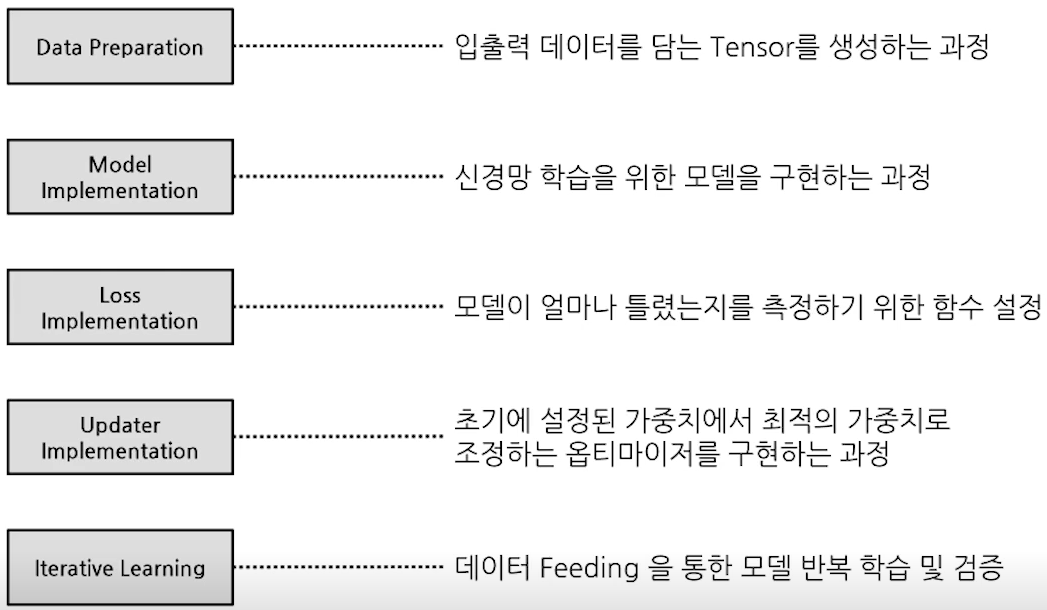 해당 Process를 Lightning을 통해 간단하게 제공
해당 Process를 Lightning을 통해 간단하게 제공

- Keras & PyTorch Lightning
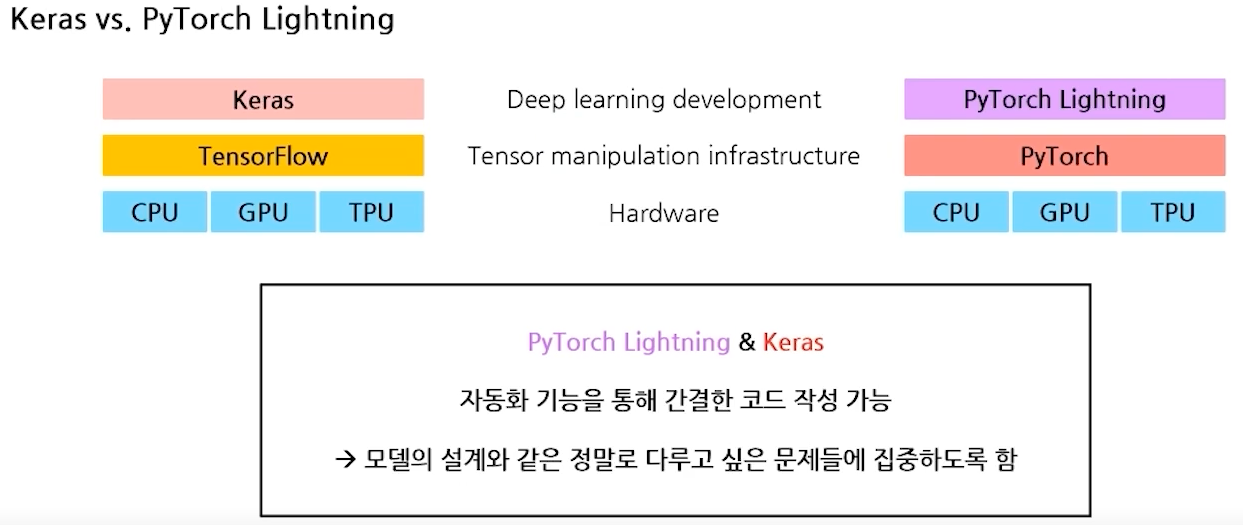
- 간략해진 Process
def prepare_data()로 데이터 다운로드 혹은 로드def setup()으로 데이터 분할#Data Preparation, dataloader()안에 생성 후 반환 def train_dataloader(self): return DataLoader(self.mnist_train, batch_size = self.batch_size, shuffle = True)- nn.Module pl.LightningModule
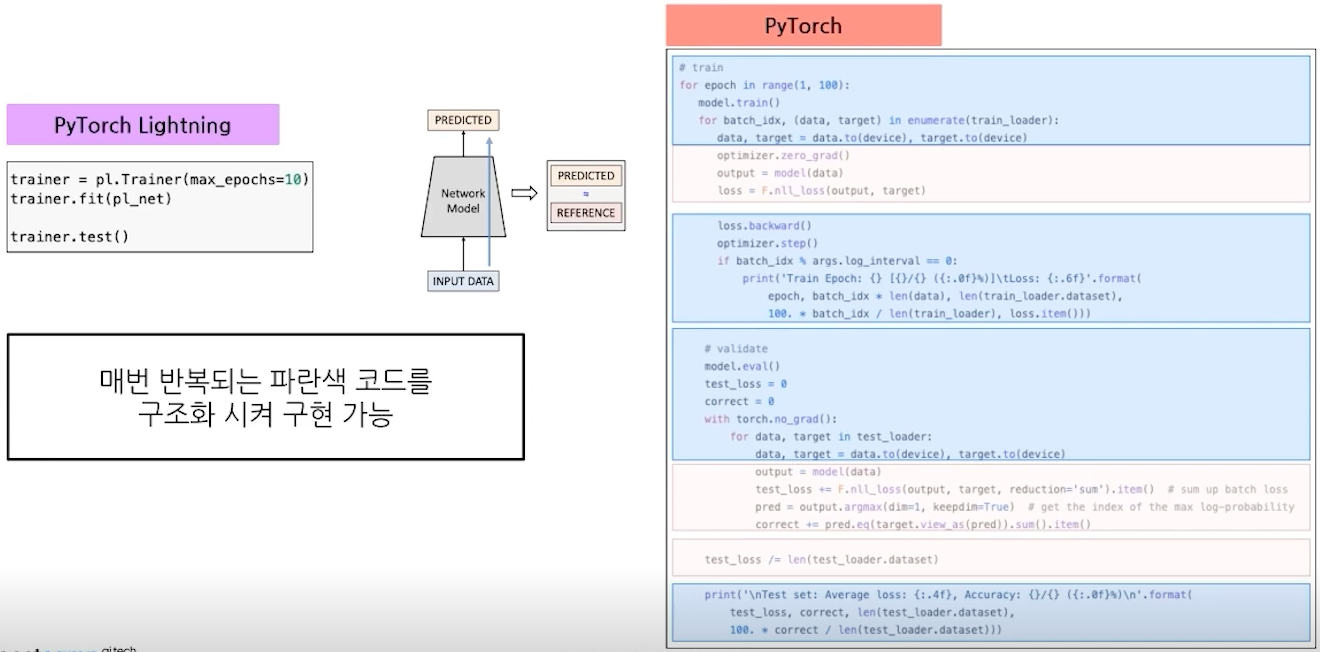
- Other API를 다 지원

- TorchMetrics : PyTorch 메트릭 API
- Deep Learning Process
-
Tokenization
- What is Tokenization?
- 신경망의 경우 입력은 항상 '숫자' 그러므로 사람의 언어를 '숫자'로 변경하려면 2가지 문제를 해결해야햔다.
- 어떤 단위로 쪼갤 것인가? : Tokenization
- 어떤 숫자로 바꿀 것인가? : Embedding
- 신경망의 경우 입력은 항상 '숫자' 그러므로 사람의 언어를 '숫자'로 변경하려면 2가지 문제를 해결해야햔다.
- Text를 숫자로 변환하려는 시도
- The Bag of Words Representation
- 단어가 나타난 횟수를 세어 text를 숫자로 변환
- TF-IDF(Term Frequency-Inverse Document Frequency)
- = tf
- tf : frequency of x in y
- df = number of documents containing x
- = total number of documents
- 단어의 빈도와 역 문서 빈도를 사용하여 DTM내의 각 단어들 마다 중요한 정도를 가중치 변환
- Word2Vec
- 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화
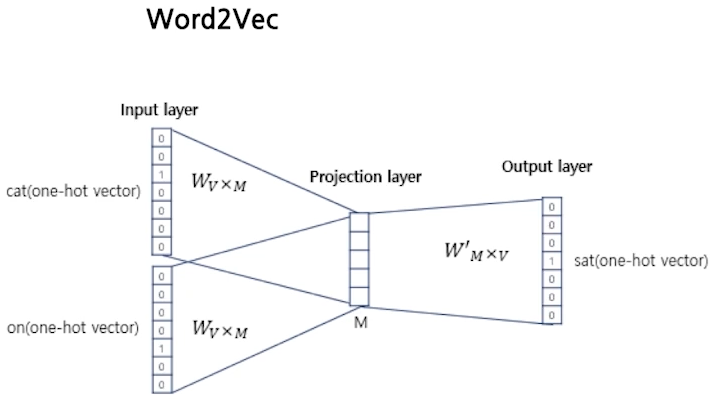
- 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화
- The Bag of Words Representation
- Tokenization Methods
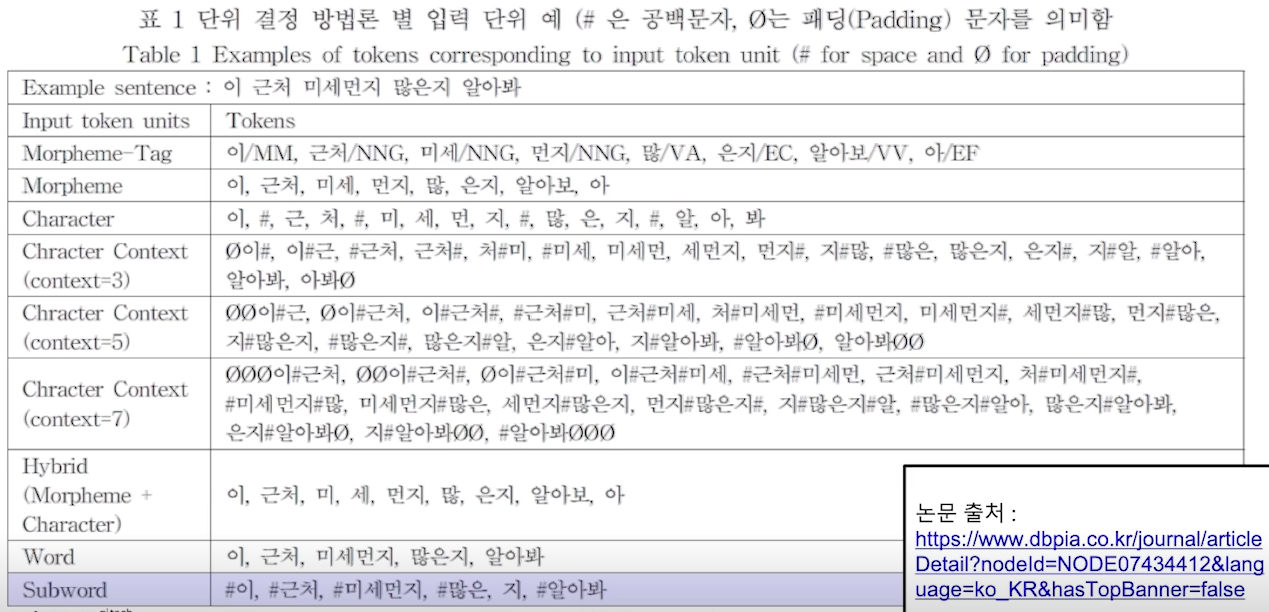
- Character-based Tokenization
- Character 단위로 token화 하는 방법
- 상대적으로 긴 lenth가 만들어 지므로, 많은 메모리 및 계산량 필요
- Word-based Tokenization
- Text를 delimiter 단위로 token화 하는 가장 흔한 방법. 주로 space 단위
- 언어에 따라(특히 한국어) 띄어쓰기가 효율적이지 않은 경우도 많음
- Subword-based Tokenization
- 문장 혹은 단어를 통계적으로 의미있는 단위로 묶거나 분할해서 처리
- Tokenization이 2개의 sub 어휘 ([token,ization])로 나눠짐
- Byte Pair Encoding(BPE) : 어휘를 묶어 나가는 알고리즘 중 하나
- Tools
- KoNLPy : 다양한 형태소 분석, 태깅 라이브러리, 한국어 정보처리 파이썬 패키지
- SentencePiece : Google이 공개한 Tokenizatione 도구
- BPE, unigram 방식 등 다양한 subword units 지원
- English and others
- Huggingface Tokenizers : 기배포된 다양한 언어모델들의 tokenization 방법과 어휘사전 등을 지원
- Character-based Tokenization
- What is Tokenization?
-
Transformer
- 배경
- 기존의 신경망(NN)은 Sequence data에 대해서는 처리하기 어려움
- Sequence data의 처리를 위한 RNN 등장
- RNN의 문제점
- 순차적 모델링 방식 (Data2를 살펴볼 때 Data1 및 Data3이 동시에 고려될 수 없음)
- 지역 정보만 활용하기에 원거리에 있는 정보가 원활하게 활용되기 힘듦
- 문제점들
- How to encode Multiple items?
- How to encode Long-term Dependency?
- How to encode Sequential information?
- How to encode Fast?
- How to make Simple Architecture for Encoder and Decoder?
- Attention : Sequence를 서로 Blending 해보자
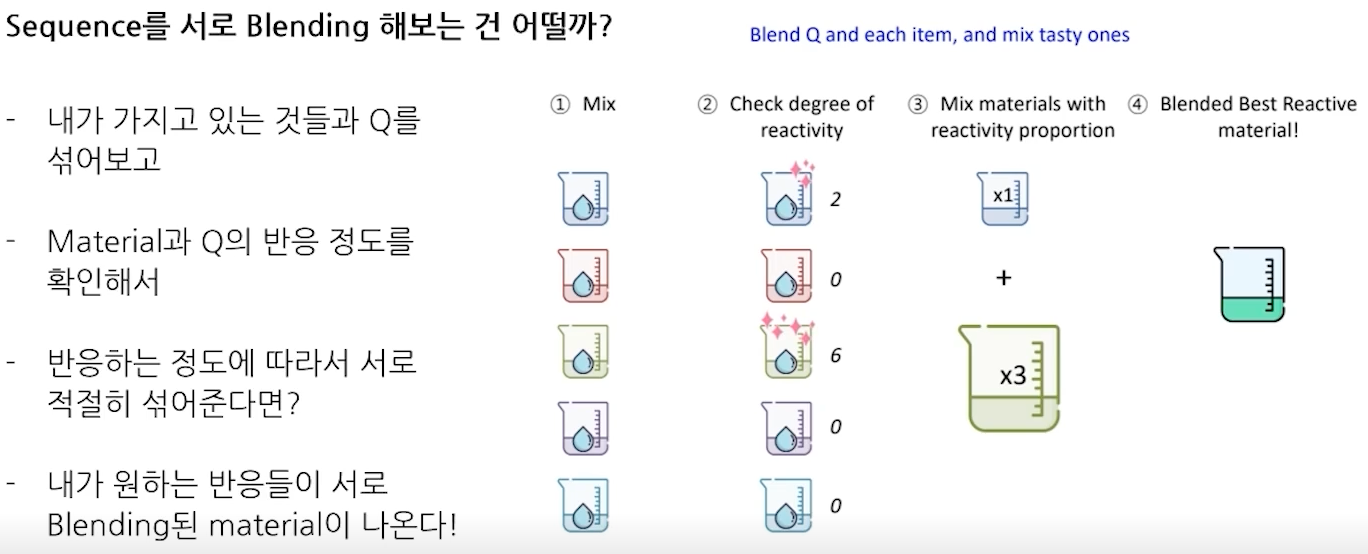
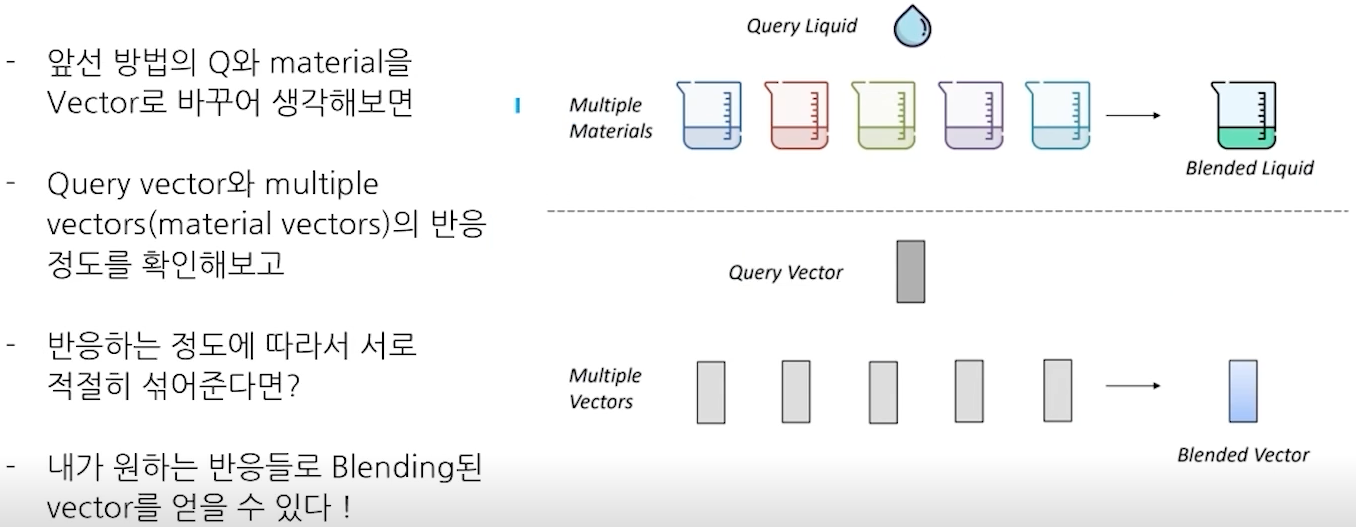
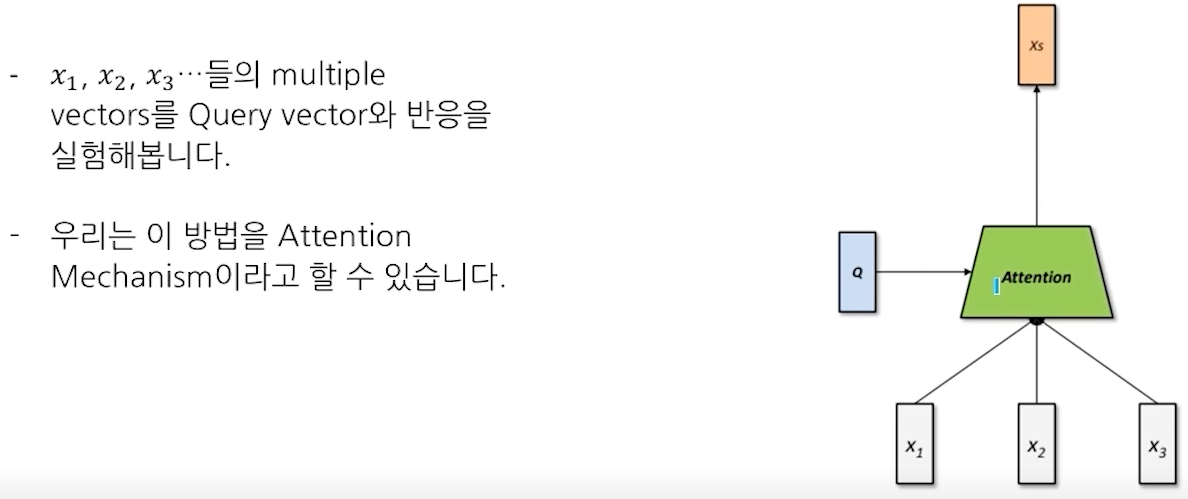
- 다양한 Attention Mechanism

- Mechanism
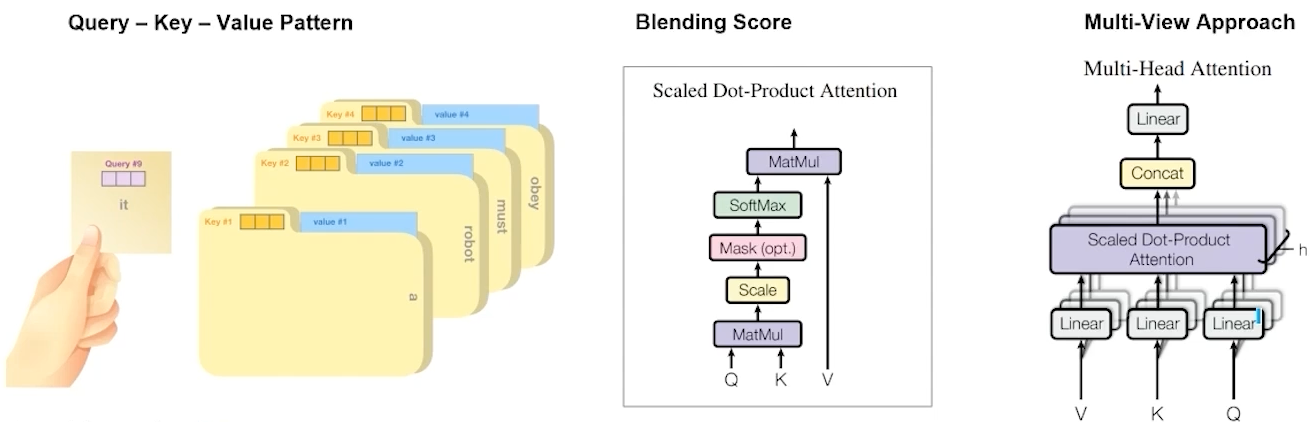
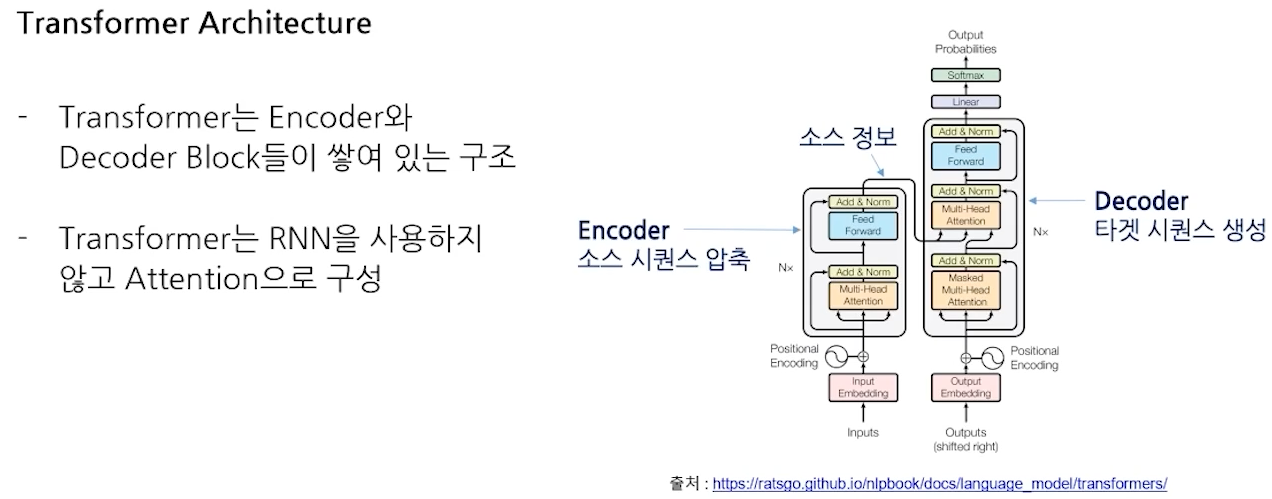
- Transformer Architecture
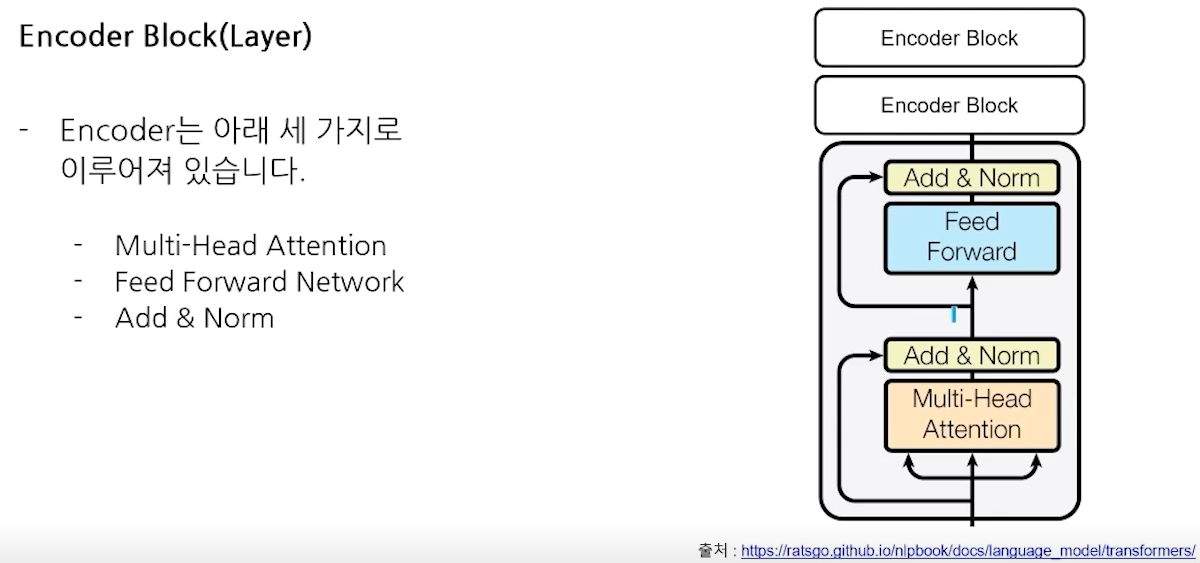
- Encoder Block(Layer)
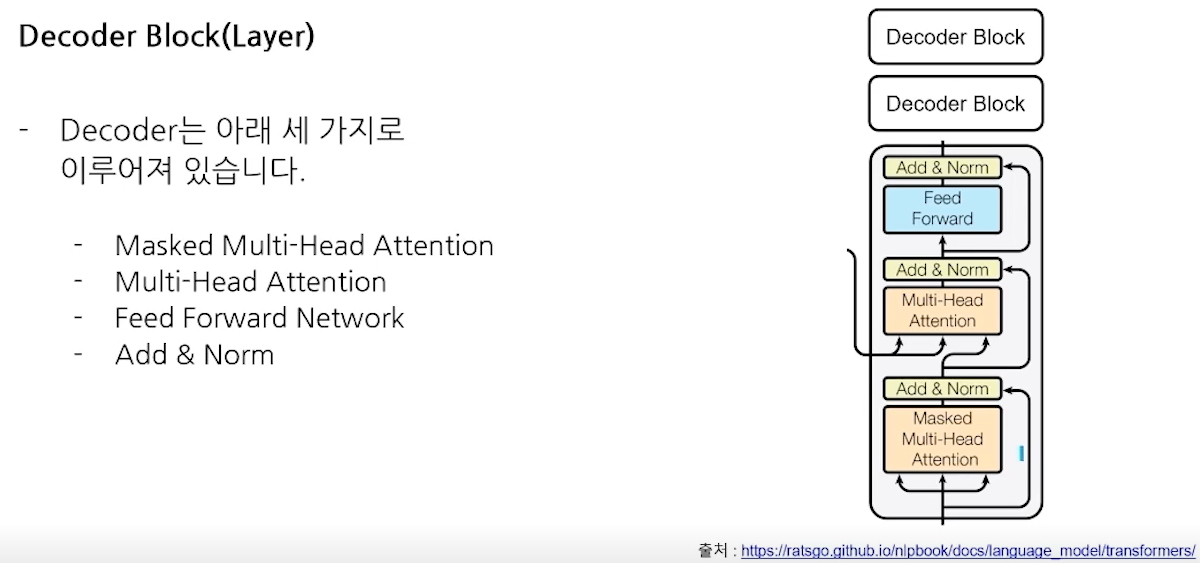
- Decoder Block(Layer)
- 배경
-
N21
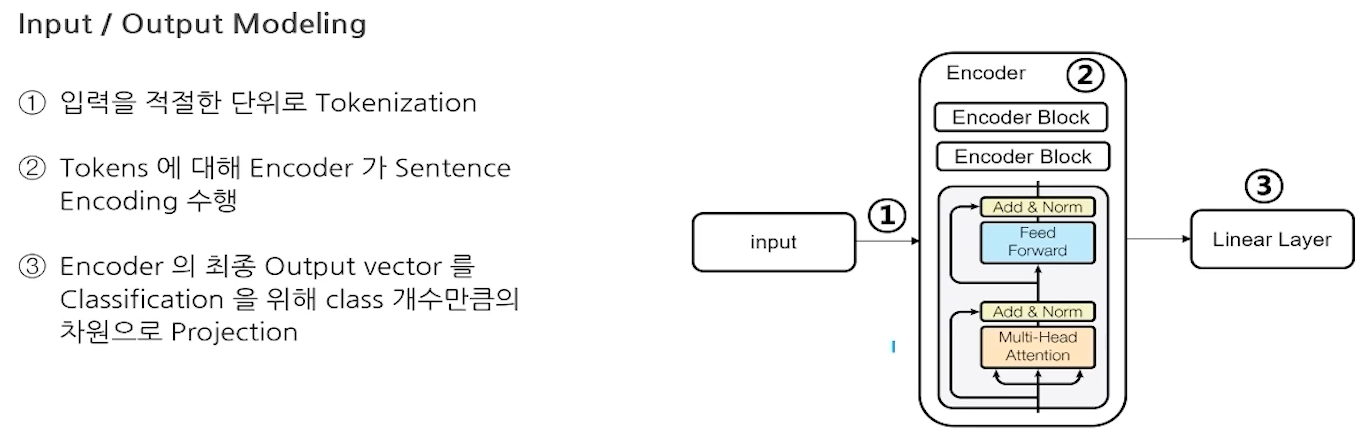
- N개의 input으로 1개의 output을 구하는 문제.
- Encoder + Fully Connected Layer 형태의 모델을 사용
- Transformer 계열에서의 Input
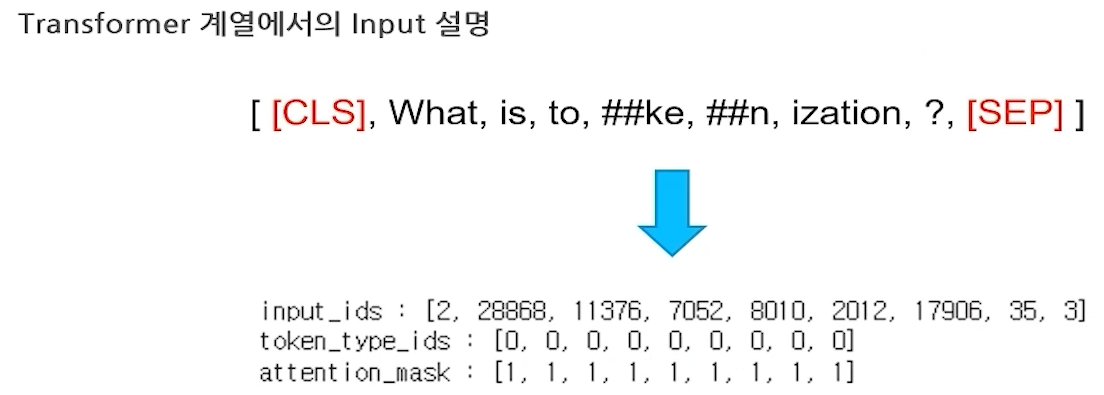
- input_ids : 모델의 입력, Embedding된 Token
- token_type_ids : Segment Embedding과 비슷하게, 몇번 째 Sentence인지 구분
- attention_mask : Attention을 할 벡터인지 구분, padding 값들은 0
- Output
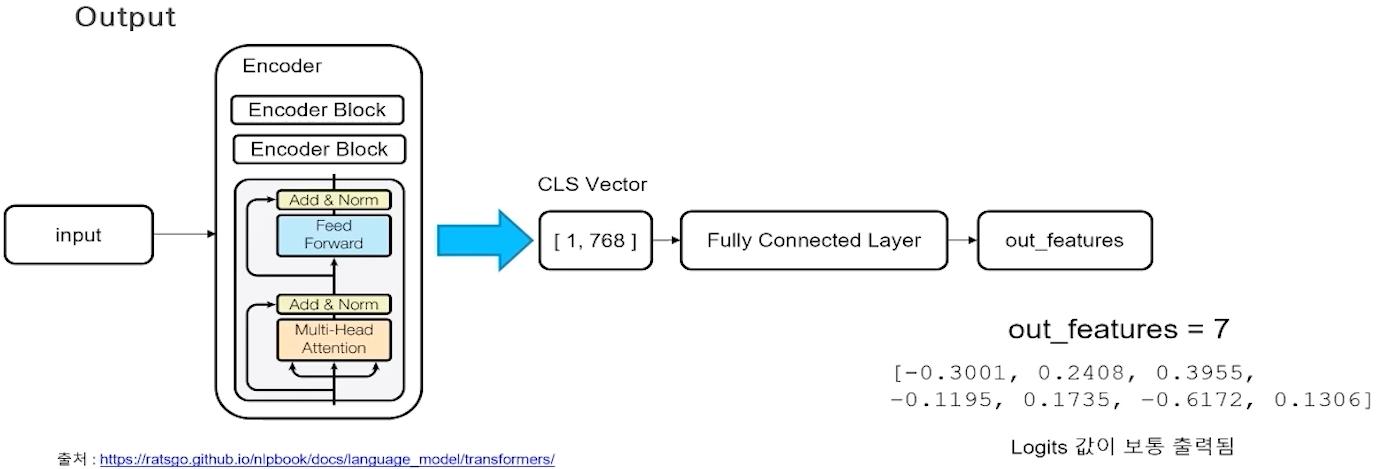
- Loss
- N21에서 '1'에 해당되는 output에 따라 사용되는 Loss function도 달라진다.
- 숫자인 경우 : Regression : MSE 등
- MRC 문제(정답위치 숫자를 맞추는문제)
- 두 문장의 문장유사도 측정
- 추천등의 문제에서 추천정도를 맞추는 문제
- Category인 경우 : Cross Entropy(CE)
- 2개의 확률 분포가 얼마나 차이가 나는지를 잘 잡아 낼 수 있는 Score
- AutoModelForSequenceClassification 사용
-
N2N (Token Classification)
- 문장전체를 살피고, 특정 part의 의미나 역할을 분석할 때 사용
- 형태소 분석, 개체명 추출
- N21 Model(Encoder) : N개 token -> 1
- N개를 만드려면 여러 파트를 나누어 rotation 필요
- N2M Model(Encoder-Decoder) : N개 token -> M개 token
- N개의 딱 맞는 출력을 생성하기에 적합 X
- N2N : Token-wise하게 1:1 매칭이 필요한 task에 적합
- AutoModelForTokenClassification 사용
- 입력 형태
- task에 알맞게 다양한 형태로 Sequential하게 표현
- Character, Word, subword 등
- Transformer에서는 subword 주로 사용
- 출력 형태
- 출력 시, 입력과 토큰 개수를 동일하게 정해야 함
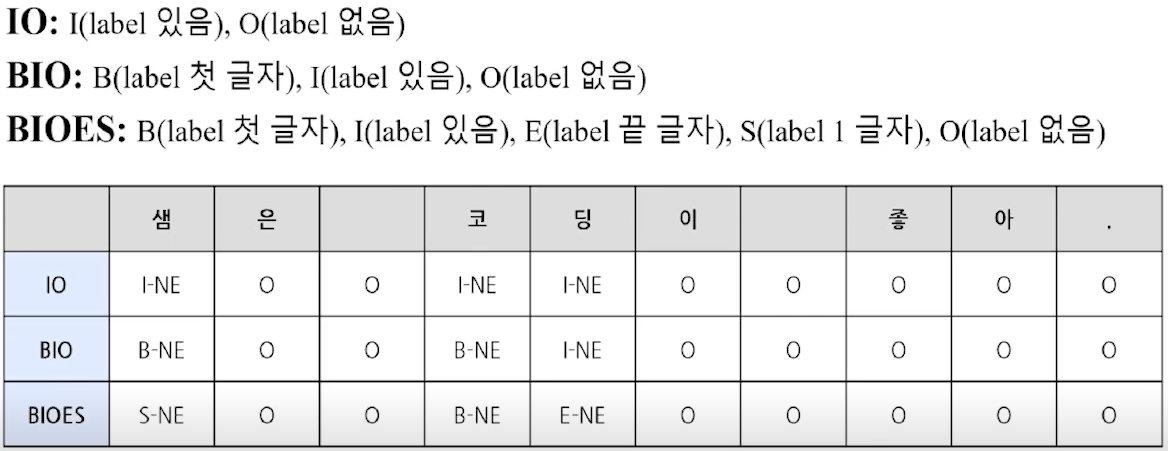
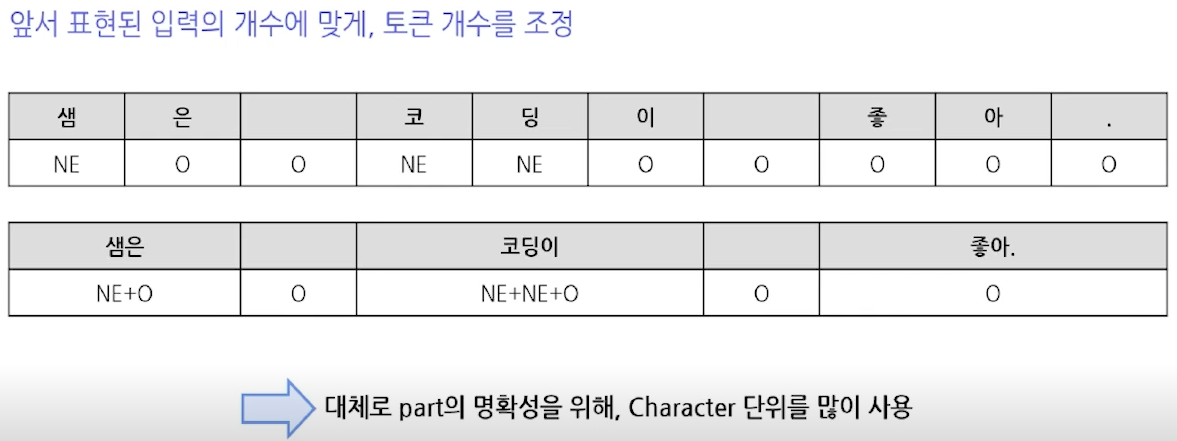
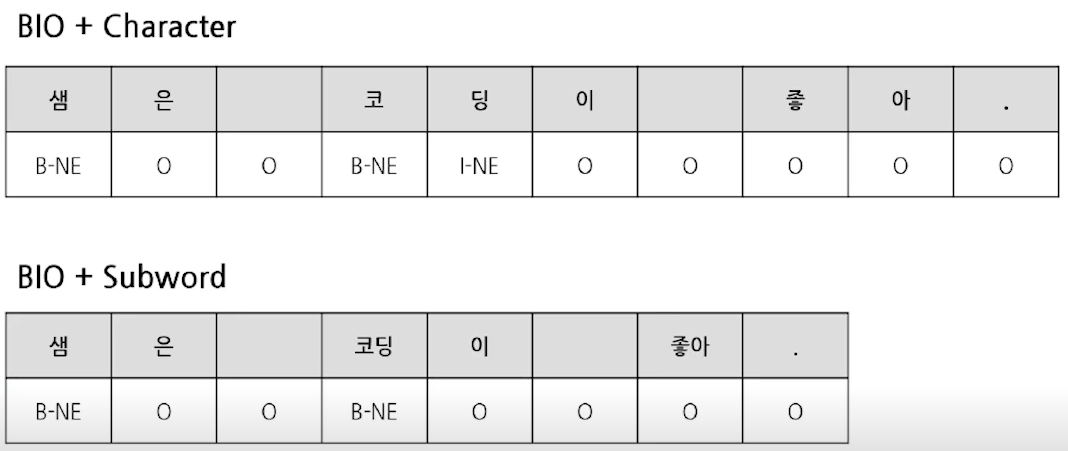
- 출력 시, 입력과 토큰 개수를 동일하게 정해야 함
- Loss 함수
- Cross Entropy
- argument 중 ignore_index = -100을 둠
- Padding 값을 무시하기 위해
- argument 중 ignore_index = -100을 둠
- Cross Entropy
- 평가 방법
- Recall, Precision, F1 score, Accuracy
- Macro : 모든 label을 고려한다. 각 라벨별 결과 도출 후, 이에 대한 평균 계산
- Weighted Macro : Label frequency를 weight로 사용
- Micro : 전체만 본다. 라벨에 대한 제한 없이, 전체 데이터에 대한 결과 계산
- 문장전체를 살피고, 특정 part의 의미나 역할을 분석할 때 사용
-
N2M
- N개의 데이터를 입력으로 받아 M개의 데이터를 출력하는 태스크
- Encoder + Decoder 모델이 주로 활용됨
- Encoder의 역할
- 입력 정보를 잘 인코딩하기 위해 활용함
- 긴 Sequence 정보를 잘 추출하는게 중요함
- Decoder의 역할
- 인코딩된 정보를 활용하여 출력 Sequence를 순차적으로 생성함
- 인코딩된 정보와 앞서 생성된 토큰을 함께 활용하여 다음 토큰을 생성함
- Task Example
- 번역
- 품사 태킹 문제
- 질의응답
- 이미지 태깅
- 대표적인 모델 : Transformer
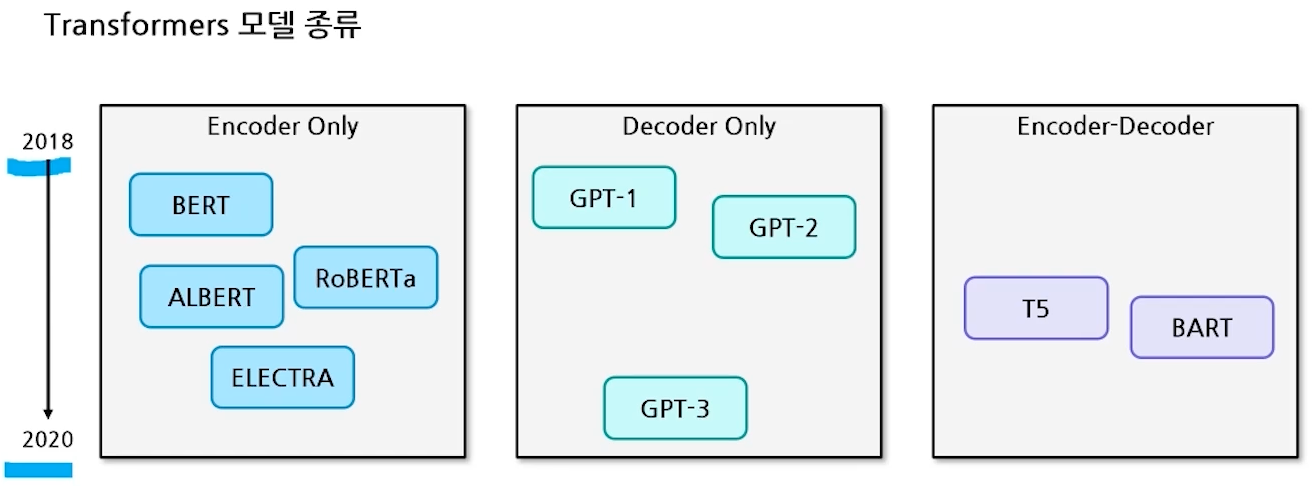
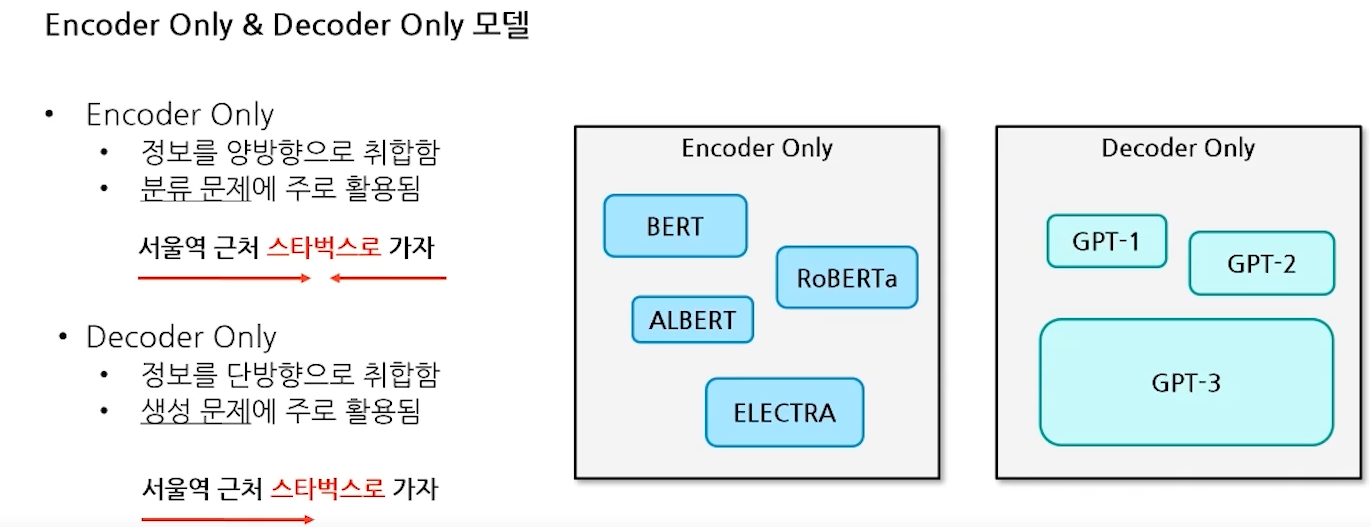
- Encoder Only 모델 학습방법

- Decoder Only 모델 학습방법

- Encoder-Decoder 모델
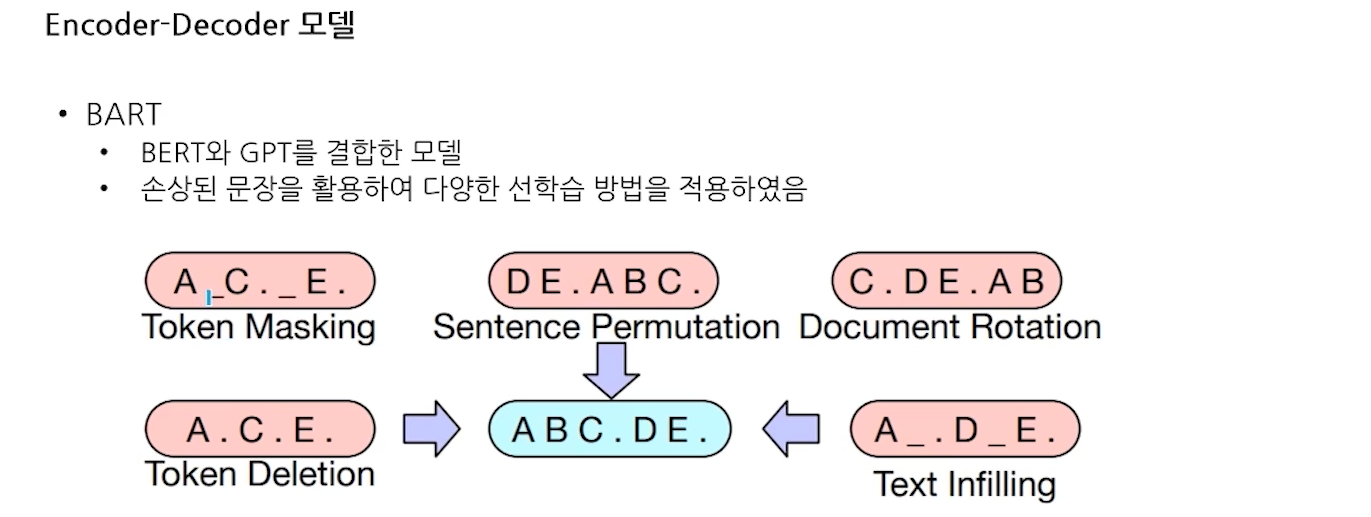
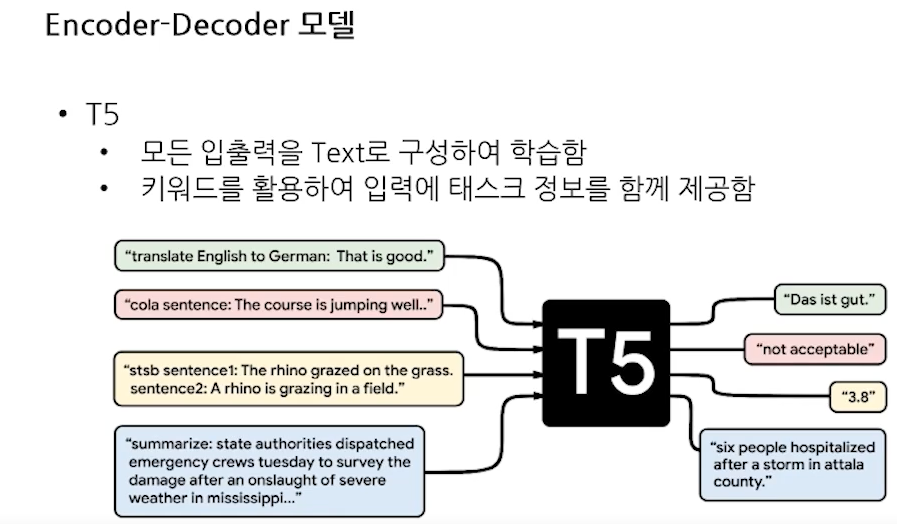
- Encoder-Decoder 동작 과정
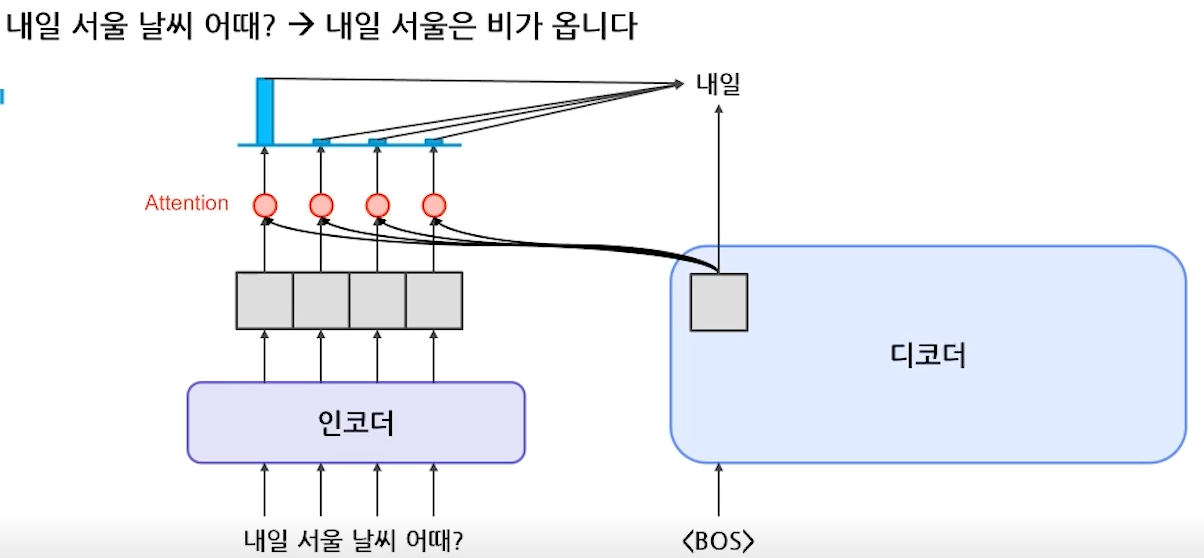
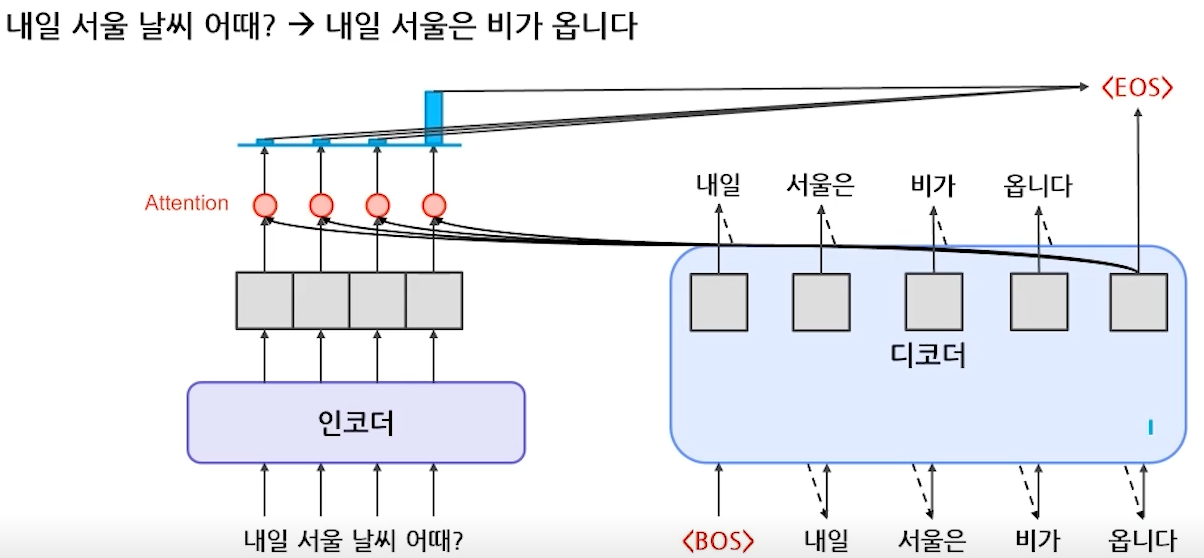
- Decoding 방법
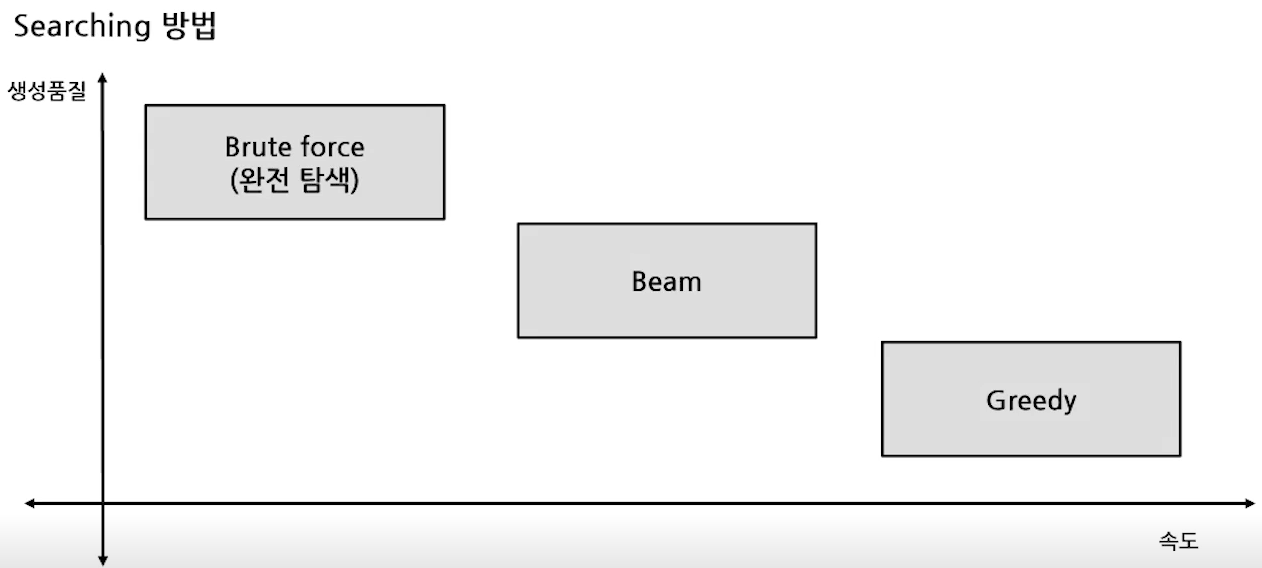
- 개선 테크닉

- Greedy search
- Greedy 알고리즘을 활용한 디코딩 방법
- 매 순간 현재 상태에서 가장 이익이 큰 것을 선택
- 시간 복잡도는 좋지만, 최종 결과가 최선이 아닐 수 있음
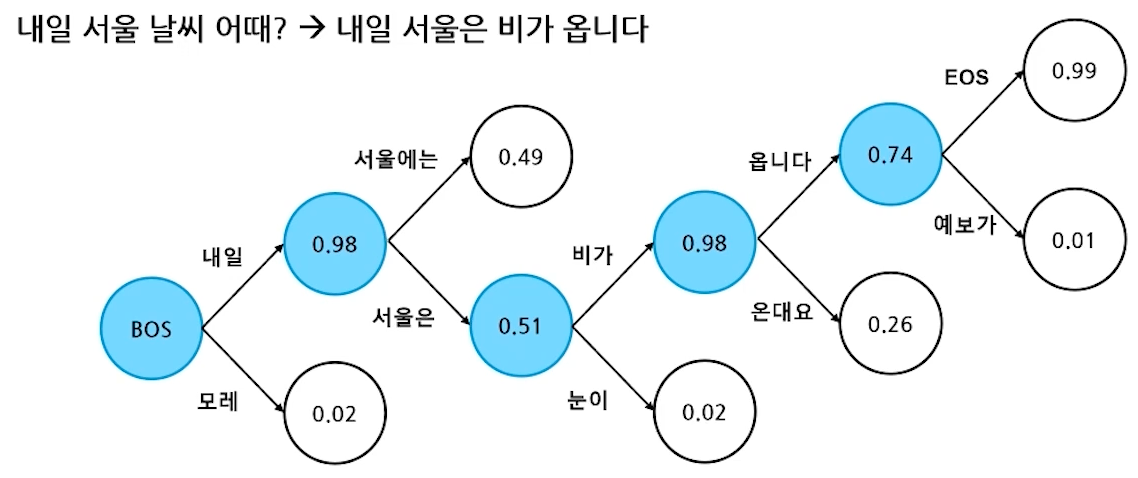
- Beam Search
- Greedy보다 더 많은 경우의 수를 고려함
- 매 순간 N개의 후보를 함께 선택하여 최종 결과를 생성함
- N = 1 이면 Greedy Serach와 동일함
- 항상 최선의 결과가 나오지는 않음
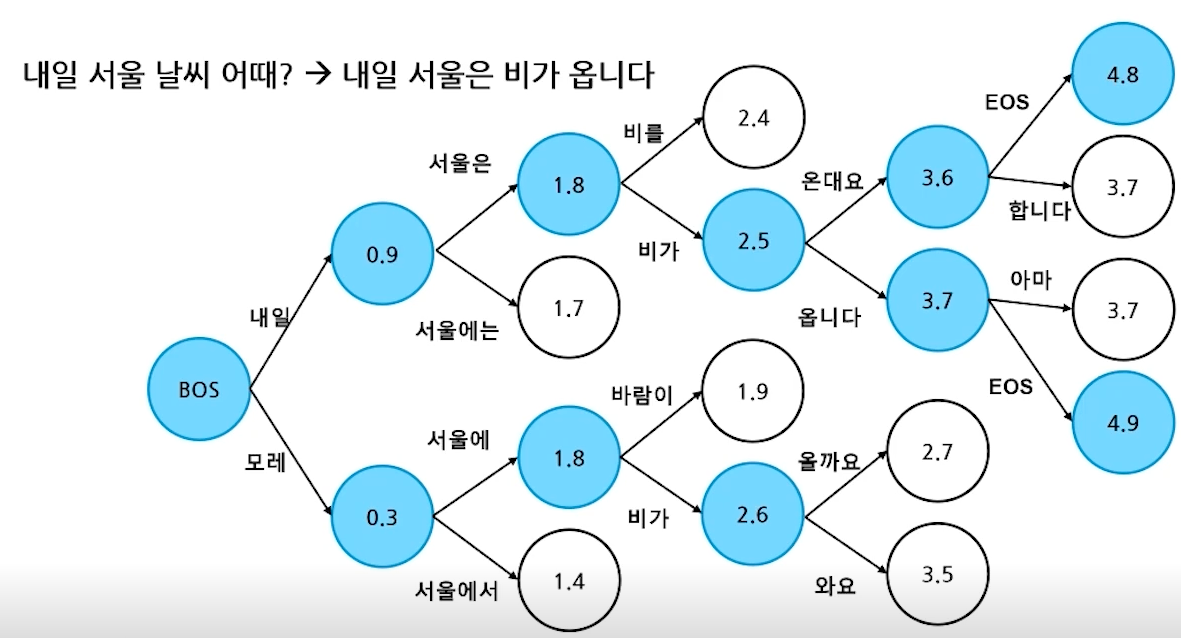
- Greedy search
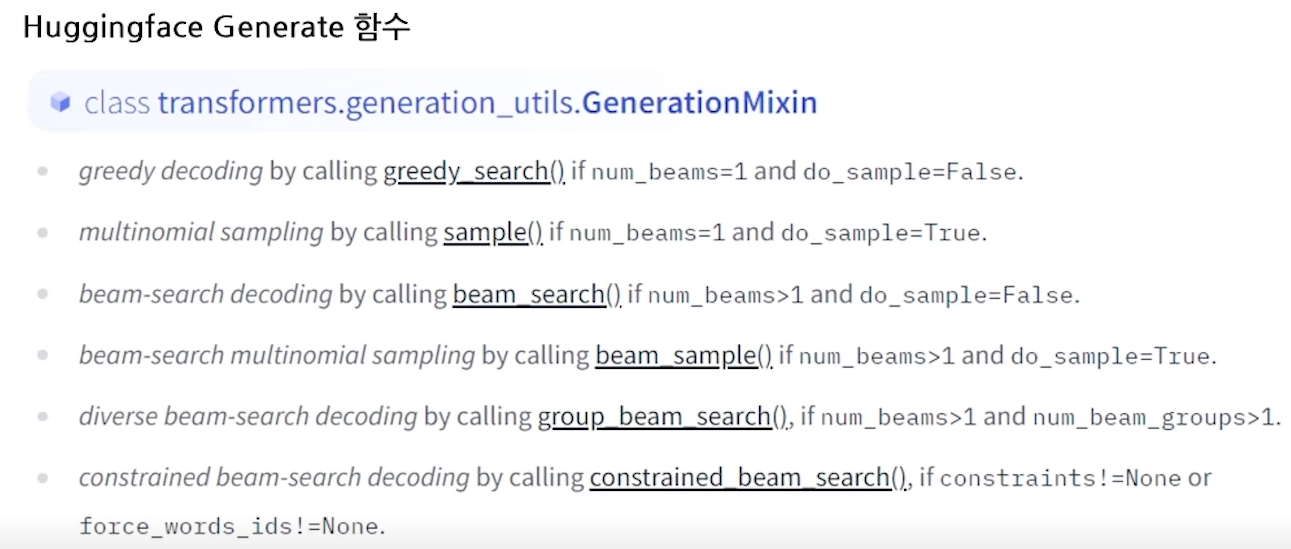
- Huggingface Generate 함수
- AutoModelForSeq2SeqLM 사용
# example self.config = transformers.BartConfig.from_pretrained('facebook/bart-base') self.encoder_decoder = transformers.AutoModelForSeq2SeqLM(config=self.config)- WandB sweep 설정
- Sweep config
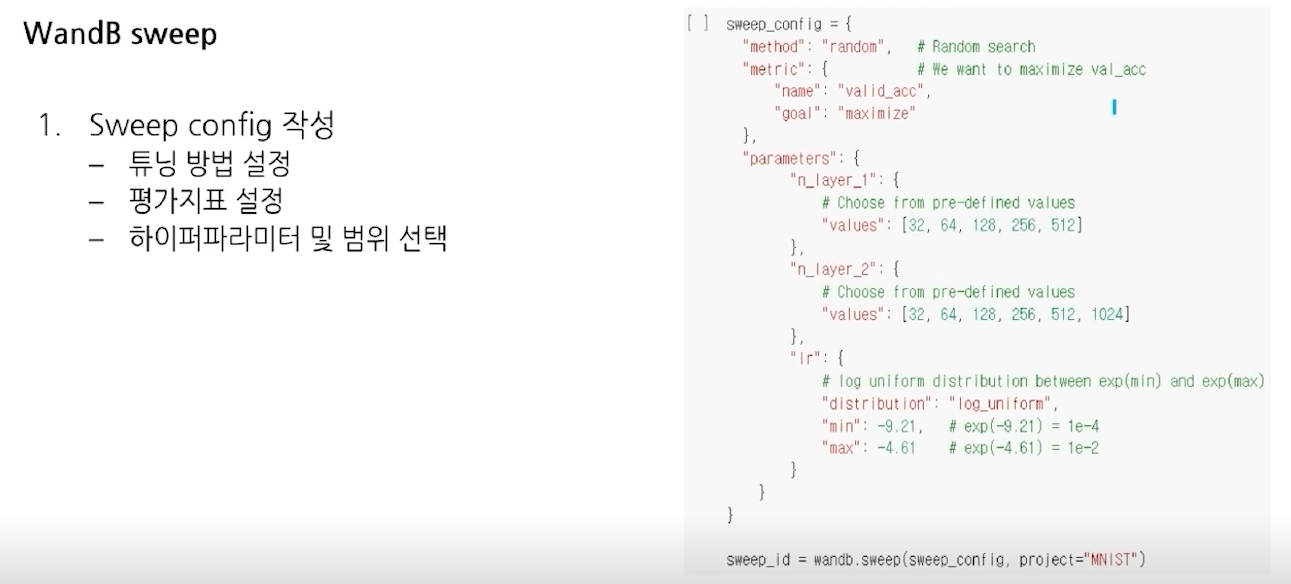
- Sweep 실행
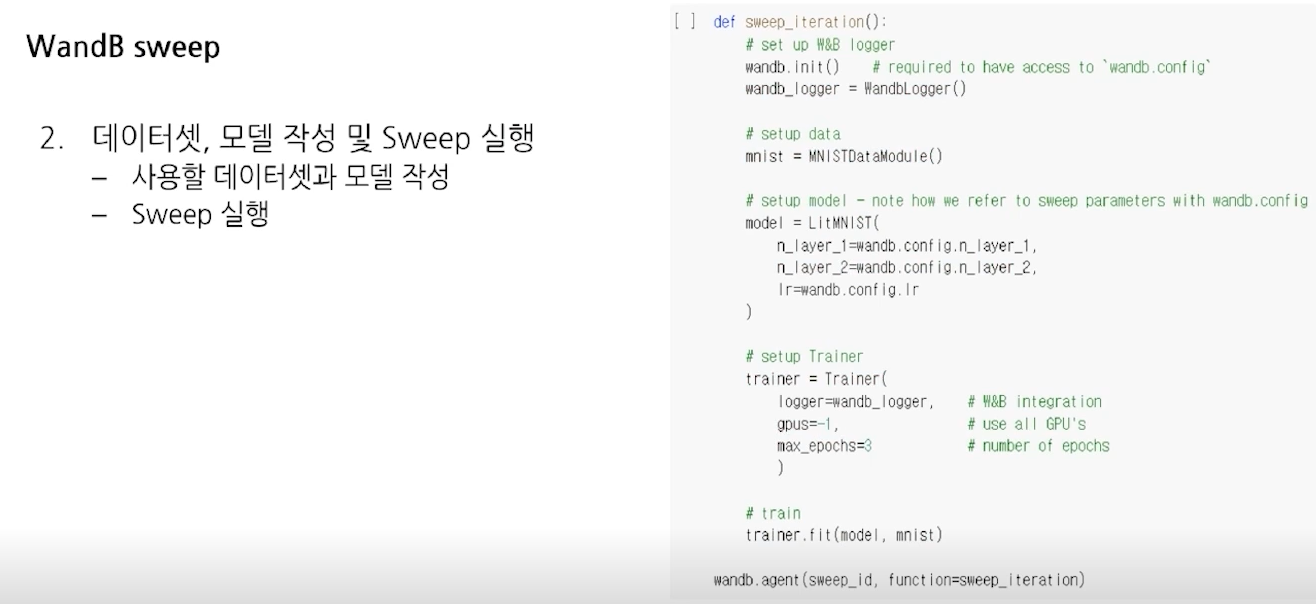
- Sweep config
-
Predcition Service 개발
-
Fastapi
- 웹 개발을 도와주는 도구
- 사용자(웹,모바일 등)의 요청을 수행함
- DB와 연결하여 데이터 작업을 수행함
- 속도와 안정성이 중요함
- 빠르고 배우기 쉽다.
- 예시
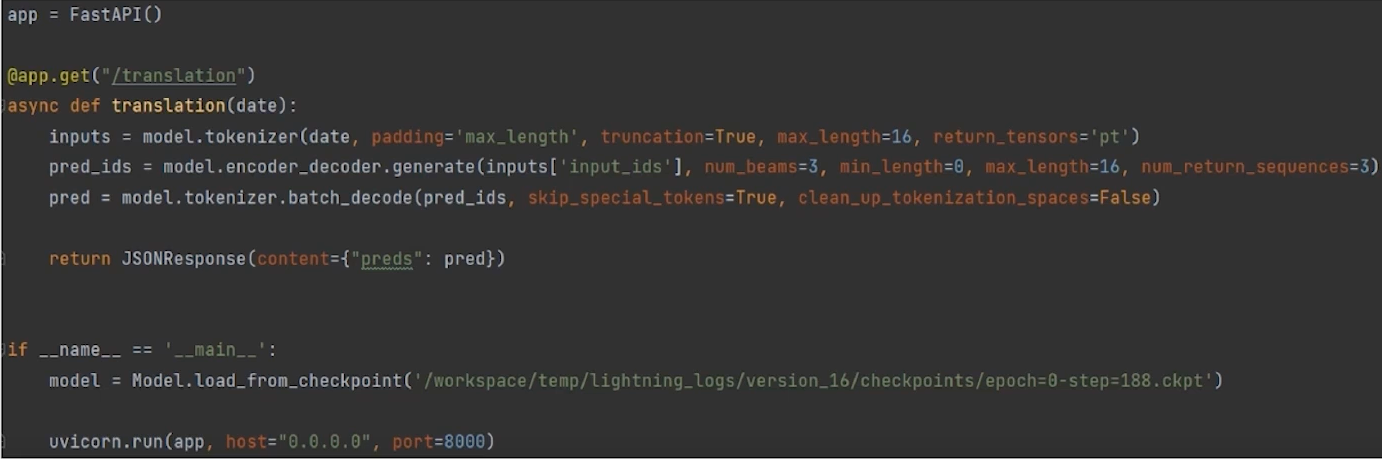
- 데코레이터와 입출력 부분으로 API 형식 정의
- 함수 내부는 Python과 동일하게 동작함
- 메인 파트에서는 학습해서 저장한 모델을 불러옴
- 외부에서 접속을 허용할 ip와 port 정보를 입력함
- host="0.0.0.0" : 외부 인터넷에서 접속 가능
- host = "127.0.0.1" : 내부 인터넷에서만 접속 가능
-
Streamlit
- Python 만으로 웹 뷰를 구현함
- 배우기 쉽고, 기본 디자인이 제공됨
- 데이터 및 결과에 대한 전달력이 우수함
- 딥러닝 모델 배포 및 테스트가 가능함
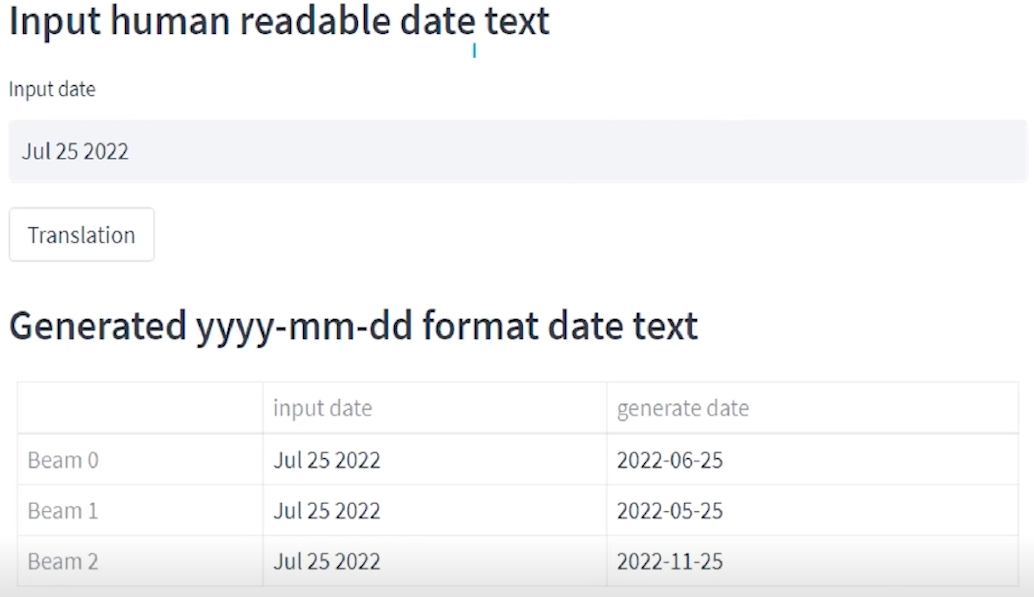
- 예시 (출력)

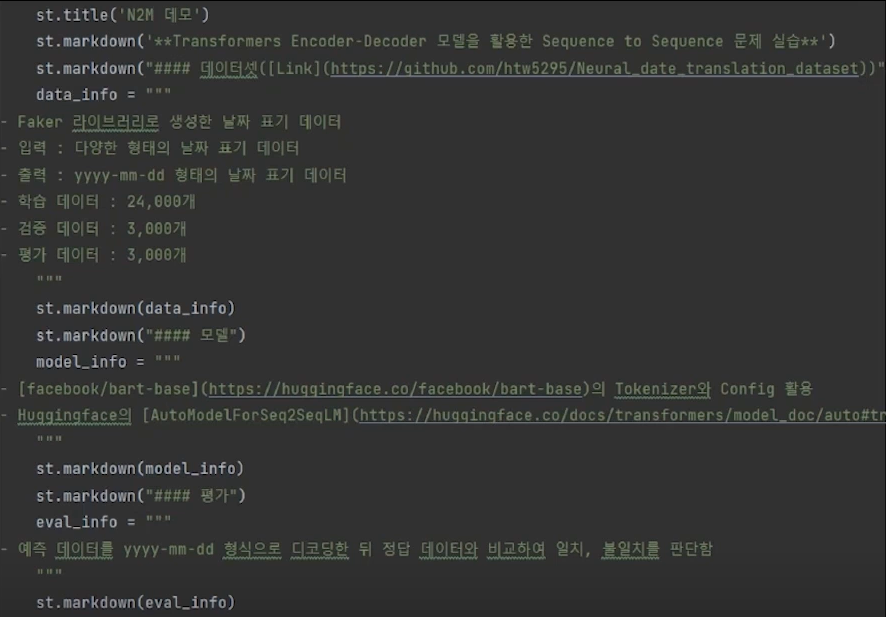
- 예시 (코드)
- 예시 (출력2)
- 예시 (코드2)
-
-
미션
-
EDA
# 입력의 두 문장을 토크나이징하여 길이와 unk 토큰의 개수를 분석합니다. def tokenizing(df): tokenizer = AutoTokenizer.from_pretrained('klue/roberta-small') sentence1_len = [] sentence2_len = [] sentence1_unk = [] sentence2_unk = [] for i, item in df.iterrows(): sentence1 = tokenizer(item['sentence1'])['input_ids'] sentence2 = tokenizer(item['sentence2'])['input_ids'] sentence1_len.append(len(sentence1)) sentence2_len.append(len(sentence2)) sentence1_unk.append(sentence1.count(tokenizer.unk_token_id)) sentence2_unk.append(sentence2.count(tokenizer.unk_token_id)) tokenized_df = pd.DataFrame([sentence1_len, sentence2_len, sentence1_unk, sentence2_unk]).transpose() tokenized_df.columns = ['1_len', '2_len', '1_unk', '2_unk'] print(tokenized_df.describe()) -
Train with Sweep
# Sweep을 통해 최적화된 hyperparameter를 찾기 import wandb sweep_config = { 'method': 'random', 'parameters' : { 'lr' : { 'distribution' : 'uniform', # parameter를 uniform하게 설정합니다. 'min' : 1e-5, 'max' : 1e-4 } } } if args.bce: sweep_config['metric'] = { # sweep_config의 metric은 최적화를 진행할 목표를 설정 'name' : 'val_f1', # F1 점수가 최대화가 되는 방향으로 학습을 진행 'goal' : 'maximize' } else: sweep_config['metirc] = {'name' : 'val_pearson', 'goal' : 'maximize'} # Pearson 점수가 최대화가 되는 방향 def sweep_train(config=None): wandb.init(config=config) config = wandb.config dataloader = Dataloader(args.model_name, args.batch_size, args.train_ratio, args.shuffle, args.bce) model = Model(args.model_name, config.lr, args.bce) wandb_logger = WandbLogger(project="klue-sts") trainer = pl.Trainer(gpus=1, max_epochs=args.max_epoch, logger=wandb_logger, log_every_n_steps=1) trainer.fit(model=model, datamodule=dataloader) trainer.test(model=model, datamodule=dataloader) # Sweep 생성 sweep_id = wandb.sweep( sweep=sweep_config, # config 딕셔너리를 추가합니다. project='project_name' # project의 이름을 추가합니다. ) wandb.agent( sweep_id=sweep_id, # sweep의 정보를 입력하고 function=sweep_train, # train이라는 모델을 학습하는 코드를 count=5 # 총 5회 실행해봅니다. ) -
KFold
# KFold Dataloader def setup(self, stage='fit'): if stage == 'fit': # 데이터셋 준비 total_data = self.read_json('train') total_input, total_targets = self.preprocessing(total_data) total_dataset = Dataset(total_input, total_targets) # num_splits 번 fold kf = KFold(n_splits=self.num_splits, shuffle=self.shuffle, random_state = self.split_seed) all_splits = [k for k in kf.split(total_dataset)] # k번째 fold 된 데이터셋의 index 선택 train_indexes, val_indexes = all_splits[self.k] train_indexes, val_indexes = train_indexes.tolist(), val_indexes.tolist() else: # 평가 데이터 준비 ... # 새 모델 생성 Kmodel = Model(args.model_name, args.learning_rate, args.bce) results = [] # K fold 횟수 3 nums_folds = 3 split_seed = 12345 # nums_folds는 fold의 개수, k는 k번째 fold datamodule for k in range(nums_folds): datamodule = KfoldDataloader(args.model_name, args.batch_size, args.shuffle, args.bce, k=k, split_seed=split_seed, num_splits=nums_folds) datamodule.prepare_data() datamodule.setup() trainer = pl.Trainer(gpus=1, max_epochs=1) trainer.fit(model=model, datamodule=dataloader) score = trainer.test(model=model, datamodule=dataloader) results.extend(score) # 모델의 평균 성능 if args.bce: result = [x['test_f1'] for x in results] score = sum(result) / nums_folds print("K fold Test f1 score: ", score) else: result = [x['test_pearson'] for x in results] score = sum(result) / nums_folds print("K fold Test pearson: ", score) -
Prediction_Check
results = trainer.predict(model=model, datamodule=dataloader) pred = torch.cat(results) wrongs = [] for i, pred in enumerate(preds): # test dataset에서 i번쨰에 해당하는 input값과 target값을 가져옵니다. input_ids, target = dataloader.test_dataset.__getitem__(i) if round(pred.items()) != target.item(): wrongs.append([dataloader.tokenizer.decode(input_ids).replace(' [PAD]', ''), pred.item(), target.item()]) wrong_df = pd.DataFrame(wrongs, columns=['text','pred','target'])
-
출처 : Naver Boost Camp

AI 새싹