
Domain Shift
- train data와 test data를 같은 sample distribution에서 뽑았다고 가정할시 generation 문제를 경험합니다.
- CLIP 논문에서 딥러닝 모델이 인간보다 성능이 낮은 이유를 train dataset에서 'in-distribution performance'를 향상시키도록 학습하기 때문이라고 지적합니다.
- 그렇기에 앞서 얘기한 train data와 test data의 distribution 차이를 'Domain(Distribution) shift'라고 칭합니다.
- 이러한 문제를 해결하기 위해 'Domain Generation' 연구가 진행되고 있습니다.
- Domain Generation에서는 domain에서 불변(invariant)한 features를 뽑는데 집중합니다.
Robustness
- 도메인 변화에 효과적인 모델이라면 robustness가 높을거라 추론할 수 있습니다.
- Effective robustness : Distribution shift 하에서 정확도의 개선
- Relative robustness : Out-of-distribution 에서의 정확도의 개선
- Zero-shot CLIP모델은 이 중 Effective robustness를 개선했다고 언급합니다.
CLIP
소개
- CLIP은 인터넷에서 얻은 대규모 데이터셋을 이용, 이미지와 연관된 caption으로 사전학습한다. 그리고 자연어 지시문(reference)을 주면 zero-shot으로 모델을 downstream task에 적용할 수 있다.
- 자연어를 supervision으로 주어 학습한다. 이를 통해 대량의 image dataset labelling 작업을 피할 수 있다. 또한, 이를 통해 image 뿐만 아니라 자연어의 representation 또한 얻을 수 있다.
학습방식
- 1개의 batch에는 개의 (image,text)쌍으로 구성한다. 이를 통해 개의 Positive pair와 개의 negative sample을 얻을 수 있다.
- image,text를 동일한 embedding space로 보낸후, positive pair에서의 유사도(cosine similarity)는 최대화 negative pair의 유사도는 최소화 한다.
- CE Loss를 사용한다.
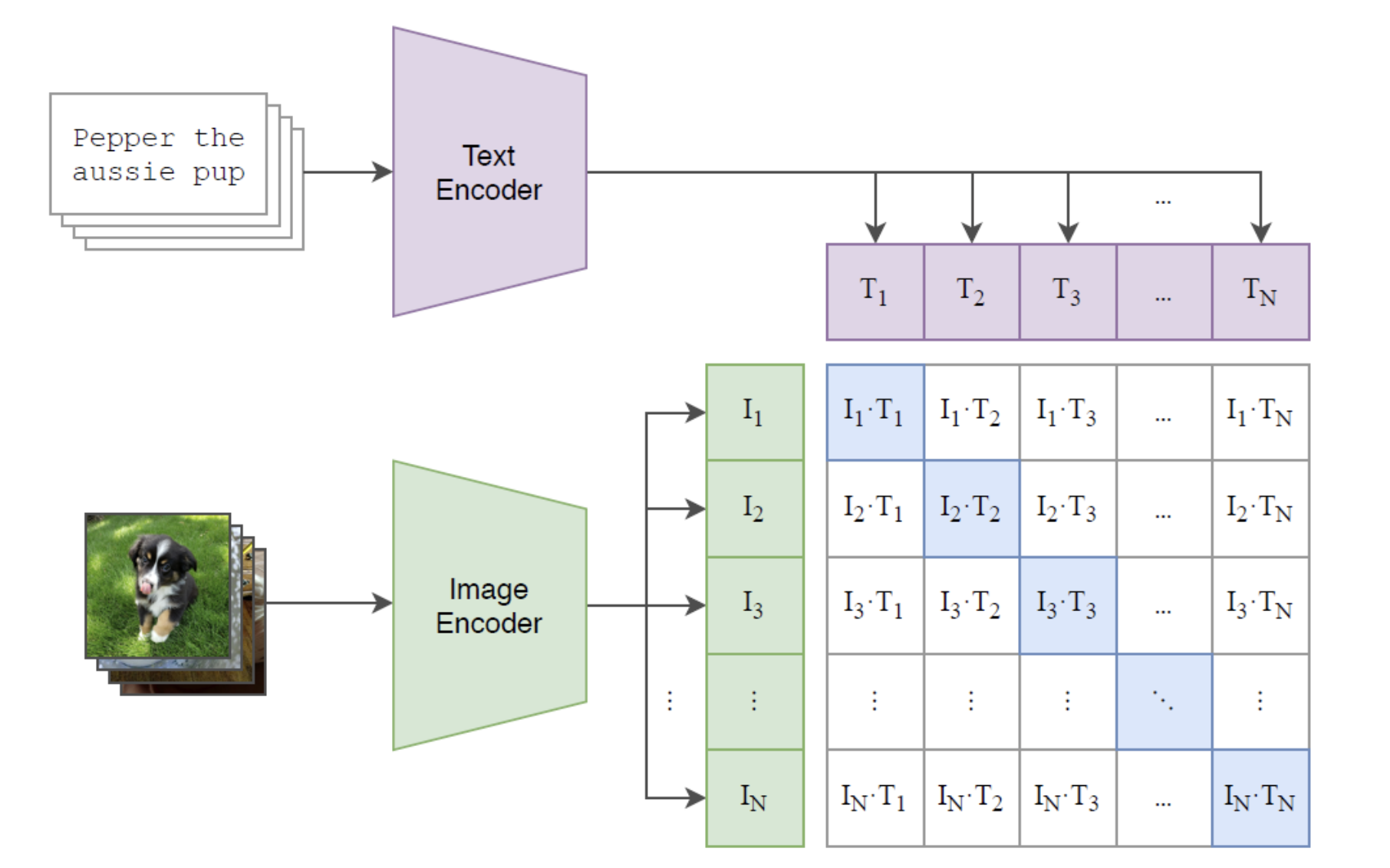
# image_encoder - ResNet or Vision Transformer
# text_ encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n,l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder (I) #[n, d_i]
T_f = text_encoder (T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = 12_normalize(np.dot(I_f, W_i), axis=1)
T_e = 12_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
# logits을 구할 때 transpose 해주었기에 axis가 다름
loss_i = cross_entropy_loss (logits, labels, axis=0)
loss_t = cross_entropy_loss (logits, labels, axis=1)
loss = (loss_i + loss_t) /2실험
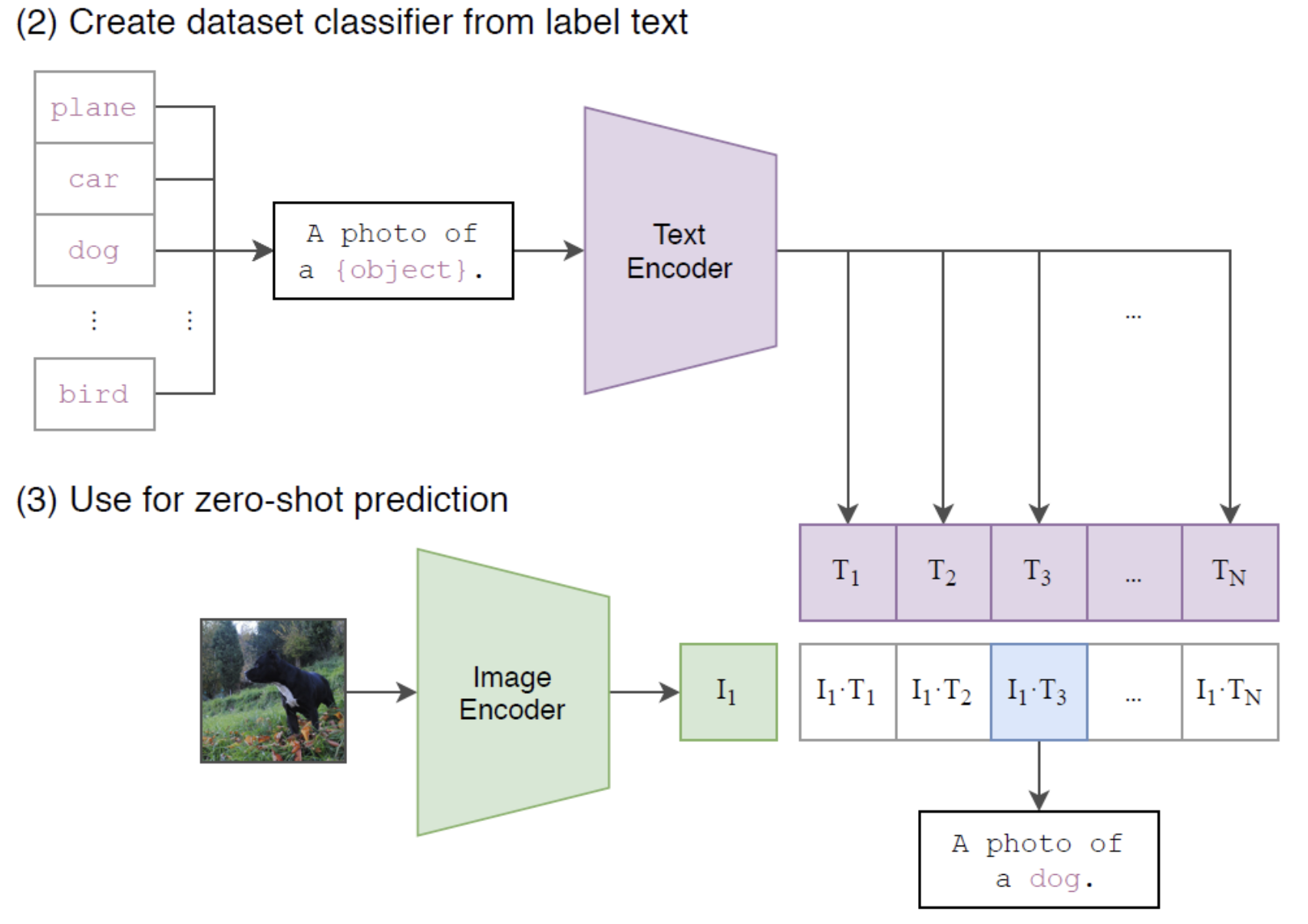
- Using CLIP for zero-shot transfer
- 이미지 분류의 경우 이미지가 주어지면 데이터셋의 모든 class와의 (image,text)쌍에 대해 유사도를 측정하고 가장 그럴싸한(probable) 쌍을 출력한다.
- 구체적으로는 그림과 같이, 데이터셋의 class name들을 "A photo of a {class}." 형식의 문장으로 바꾼 뒤, 주어진 이미지와 유사도를 모든 class에 대해 측정하는 방식
- Prompt engineering and ensembling
- 절대다수의 이미지 데이터셋은 class를 그냥 단순히 숫자로 구성된 id만으로만 저장해 두고 있다.
- 또 다의성 문제도 있는데, class name 외에 추가적인 정보가 없는 경우 다른 class로 인식할 수 있는 문제도 존재한다.
- CLIP을 zero-shot으로 이미지 분류를 시킬 때 하나의 문제는 class name은 대부분 한 단어 정도인 데 비해 사전학습한 데이터는 그렇지 않다는 점이다.
- 그래서 위에서 설명한 것처럼 class name을 그대로 집어넣어 유사도를 측정하는 대신 "A photo of a {class}." 형식의 문장을 만들어서 유사도를 측정한다.
- GPT와 마찬가지로 각 task에 맞는 prompt text를 적절히 선택해주면 분류하는데 도움이 될 수 있다.
"A photo of a {label}, a type of pet."
"a satellite photo of a {label}."
"A photo of big {label}"
"A photo of small {label}"
- Robustness to Natural Distribution Shift : 즉 distribution shift에 상당히 robust하다.
- task에 보다 adaption을 시키거나 few-shot learning을 하면 accuracy는 증가하지만 robustness는 떨어진다.
한계
- SOTA 모델에 비해 성능이 떨어진다. 이를 해결하기 위해서는 계산량이 1000배 증가해야한다고 한다.
- Task-specific 모델과 비교하여 여러 유형의 세분화된 분류(즉, 좁은 범위에서의 분류 문제)에서 특히 약하다.
- 또한 사진에서 가장 가까운 자동차까지의 거리를 분류하는 task와 같은, CLIP이 사전학습 단계에서 학습했을 리 없는 새로운 종류의 문제에 취약하다.
- pretrain 단계에서 학습하지 않거나 양이 적은 데이터에 취약하다.
- CLIP이 일반적인 딥러닝 모델의 취약한 일반화(generalization)라는 근본적인 문제를 거의 해결하지 못했음을 의미한다.
- 인터넷에서 수집한 데이터를 사용하기에 사회적 편견(bias)도 학습하게 된다.
- Class design 즉 class 이름을 어떻게 추가하냐에 따라 성능이 갈릴 수 있다.
Hard negative sample
- CLIP 모델은 embedding space에서 distance를 조절하는 방식으로 학습하기에 mini-batch내에서 sample을 잘 구성하는 것이 중요
- 그렇기에 분류하기 어려운 이미지를 잘 분류하기 위해서는 random sampling 방식이 아닌 hard negative 샘플을 잘 구성해야함
How to make Hard negative sample
- 추후 작성 예정
출처 : domain shift
출처 : CLIP

AI 새싹