
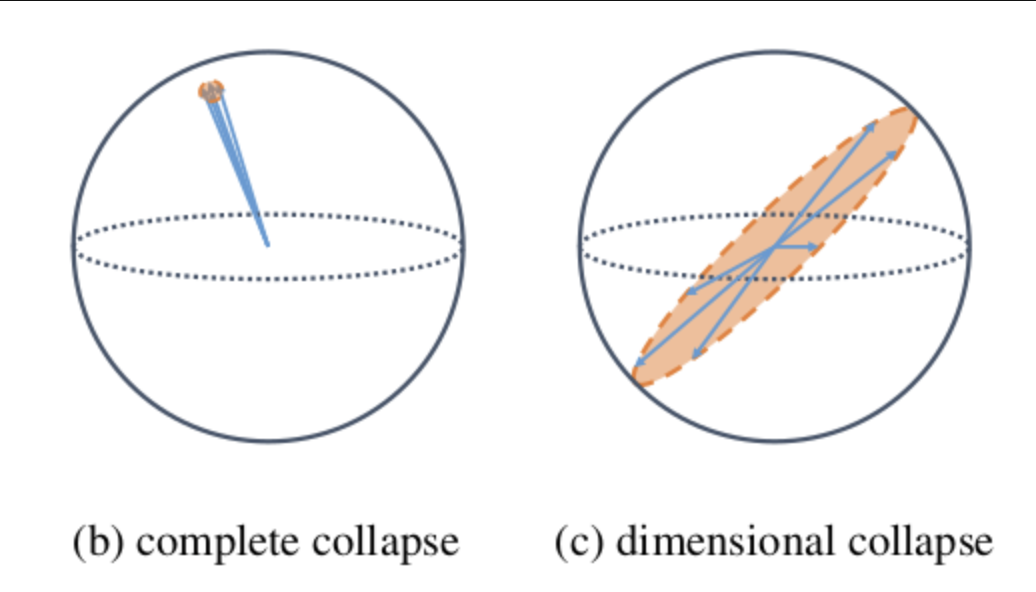
collapse problem
-
해당 문제는 두 가지의 예시로 나눌 수 있습니다.
- GAN
- generator와 discriminator의 학습 균형이 맞지 않아 discrimnator의 학습 속도가 빨라짐
- generator가 '진짜'같은 이미지를 생성하는 본 목적을 잃고 discriminator가 가장 헷갈려하는 똑같은 이미지만을 생성
- Mode collapse
- Representation learning (contrastive learning)
- 같은 이미지(positive pair)끼리는 embedding vector가 가깝게 나오도록, 다른 이미지(negative pair)끼리는 멀어지도록 metric learning
- 네트워크 입장에서 계속 같은(augmentation 이기에 동일하진 않음) 이미지끼리 embedding vector를 가깝게 하는 것으로 받아들이고 네트워크는 계속 둘이 같은 이미지 (similarity=1)이 되도록 embedding vector를 output
- 이를 해결하기 위해 negative pair를 사용, positive pair만을 사용하면 Collapsing 발생
- complete collapse problem
- GAN
-
즉 Contrastive learning은 negative pair 사용을 통해 complete collapse problem을 해결
-
하지만 dimensional collapse는 해결하지 못했다.
dimensional collapse
- Contrastive learning 의 경우 negative sample과 positive sample의 repulsive effect를 통해 complete collapse problem을 완화하는데, 그럼에도 embedding vector가 특정 dimension으로 표상되는 dimensional collapse 문제가 발생
- 즉 임베딩 벡터가 모든 임베딩 스페이스에 있는 것이 아닌 a lower-dimensional subspace에 존재하는 dimensional collapse 문제가 발생한다.
- 논문[1]의 저자들은 이러한 이유가 두 가지의 이유에서 야기된다고 한다.
- strong augmentation along feature dimensions
- implicit regularization driving models toward low-rank solutions.
- In general, over-parameterized neural networks tend to find flatter local minima.
- Dimensional Collapse caused by Strong Augmentation
- data augmentation 에 의한 variance가 data distribution 자체의 variance 보다 클 때, weight collapse
- Dimensional Collapse caused by Implicit Regularization
- Implicit Regularization : explicit regularization 과 달리 별도의 penalty term이 없음에도 불구하고, deep network 에서 서로 다른 layer의 weight 의 interplay 로 인해 모델이 low-rank solution 을 찾으려는 tendency
MoCo
- constrastive learning의 다양한 방법론들이 기본적으로 dictionary look-up이라고 주장
- 매우 많은 key가 존재하는 dictionary에서 query로 들어온 데이터에 대해 positivie key에 대해서는 유사도가 높아야하고 negative key에 대해서는 유사도가 낮아한다.
- Encoded된 query q와 encoded된 키 , , 이 있고 하나의 키 만 q에 매칭되는 positive key이고 나머지 K개의 키는 매치되지 않는 negative key
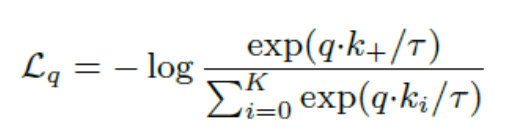
- 충분히 큰 크기의 dictionary를 queue 형태로 두고, dictionary에서 negative sample들을 추출
- 일반적으로 Dictonary의 크기는 batch size보다 크며 default 값으로 65536개를 사용
- 만약 256개의 batch 단위로 학습을 한다면 하나의 입력 이미지에 대해 query와 key를 생성하여 positive pair를 이루고 dictionary에 이미 들고있는 65536개의 key와 negative pair
- 학습이 완료되면 학습 과정에서 생성된 256개의 key들이 가장 오래된 256개의 key들을 대체
- 학습에 따라 dictionary의 구성이 update되기 때문에, 이를 dynamic dictionary라고 부름
- queue 구조의 큰 dictionary를 이용하게 되면, key encoder를 학습하는 수많은 negative sample들에 대해 gradient를 전파해야하기에 학습이 어려워짐
- 이를 해결하기 위해 key encoder를 따로 학습하지 않고, 학습된 query encoder를 그대로 가져와서 이용해봄
- 실험 결과 수렴안됨, 빠르게 변화되는 query encoder를 그대로 이용해서 key를 계산하게 되면 key 값들의 consistency가 유지되지 않아서
- 이를 해결하기 위해 momentum update를 이용해서 key encoder를 천천히 진화시키는 방법을 사용, m=0.999
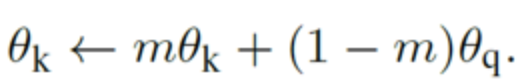
- 일관성 있는 dictonary의 구성을 위해 MoCo는 queue 형태의 dictionary와 momentum update를 이용한 key encoder의 변화로 이를 가능하게 함
- 기존 방법들과 비교
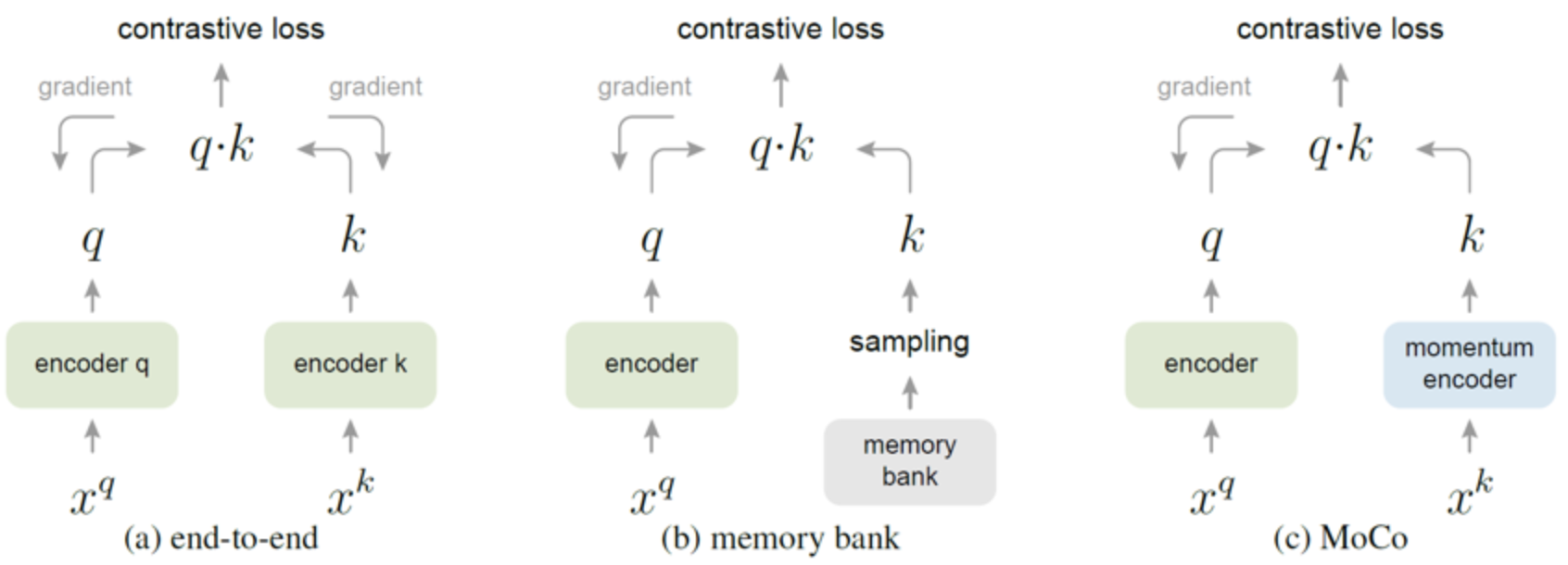
- (a) : key encoder도 query encoder와 마찬가지로 똑같이 학습
- queue 형태의 dictionary를 사용하는 것이 아니라, mini-batch에 해당하는 sample들을 batch로 이용했기 때문에 GPU memory 크기에 제약
- 즉 상대적으로 적은 수의 negative sample 밖에 이용할 수 밖에 없음
- (b) : 데이터셋에 존재하는 모든 sample들의 representation을 memory bank에 두고, 임의로 몇 개의 sample을 골라 dictionary를 구성
- query에 해당하능 sample들로 memory bank를 update하면서 학습을 진행
- memory bank 안의 key들이 빠르게 변하는 query encoder의 결과값으로 update 되기 때문에, dictionary가 inconsistent해지고 학습이 제대로 되지 않았음
- 이를 해결하기 위해 key를 update할 때 momentum update를 적용, encoder가 아니라 key 값 자체가 update되기 때문에 한 epoch 뒤의 encoder output에 대한 값을 이용하게 되고, 마찬가지로 inconsistency 문제가 발생
- (c) : MoCo는 queue 구조를 활용한 dictionary를 이용하기 떄문에 충분한 양의 negative sample로 학습 가능 또한 memory-efficient하고 데이터셋의 크기가 클 때도 안정적으로 학습 가능
- memory bank의 경우 데이터셋의 크기가 크면, update 주기가 길어져 학습이 불안정해짐
- (a) : key encoder도 query encoder와 마찬가지로 똑같이 학습
Hard Negative Mixing for Contrastive learning : MoCHi
- batch size가 증가해도 항상 선형적으로 성능 향상은 아니였음
- batch size가 증가해도 hard negative sample이 많아지는게 아니어서 성능이 오르지 않는다고 주장
- dicision boundary 근처의 hard positive와 hard negative가 discriminative 피쳐들을 잘 배우게 도와주는데 ssl에선 이 점에 대해 무시되었음이라 주장
- matching probabilities를 구해 plotting 했을 때 few negatives offer significant contributions to the loss
- 대부분의 memory bank에 있는 negative들이 pretext task에 도움이되지 않는다고 주장
- A class oracle-based analysis
- query와 같은 클래스를 갖는 memory key에 있는 모든 negative 피쳐들을 FN(false negative)라고 정의
- 이를 제거하고 학습했을 때 성능이 더 좋아짐
- Mixing technique
- query와 모든 K개 만큼의 negative 샘플의 embedding 벡터간의 유사도를 측정 후 정렬
- sorting된 K 값들 중에서 n개를 가져와 두 negative간의 믹싱을 수행(interpolation, 보간)
- hard하게 negative간의 믹싱만 하는 것이 아닌 query와 negative 간의 믹싱도 제안
- 이를 통해 pretext task가 더욱 어렵게 학습이 됨
- 해당 테크닉을 다 사용했을 때 supervised learning과 불과 1% accuracy 차이
- 지도학습에 비해 alignment는 더 낮았지만 uniformity는 더 높음
Constrastive Clustering
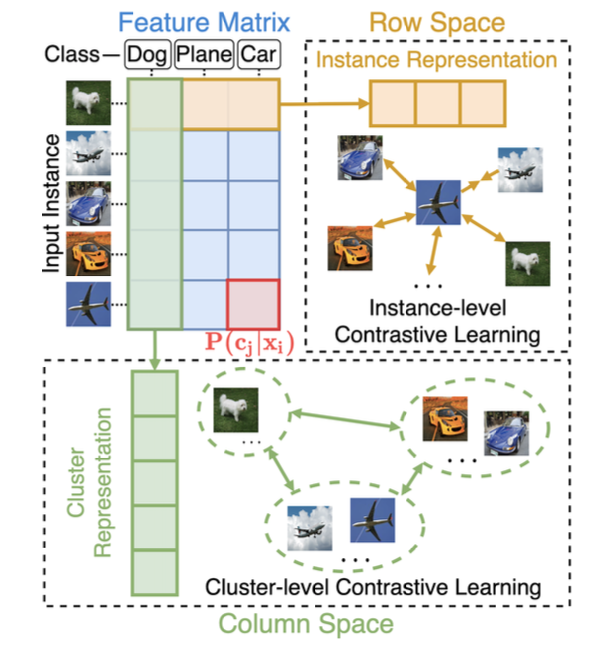
- Given datase, the positive and negative instance pairs are constructed through data augmentations and then projected into feature space
- conducted in the row and column space by maximizing the similarities of positive pairs while minimizing those of negative ones
- row of the feature matrix : could be regarded as soft labels
- columns could be further regarded as cluster representations
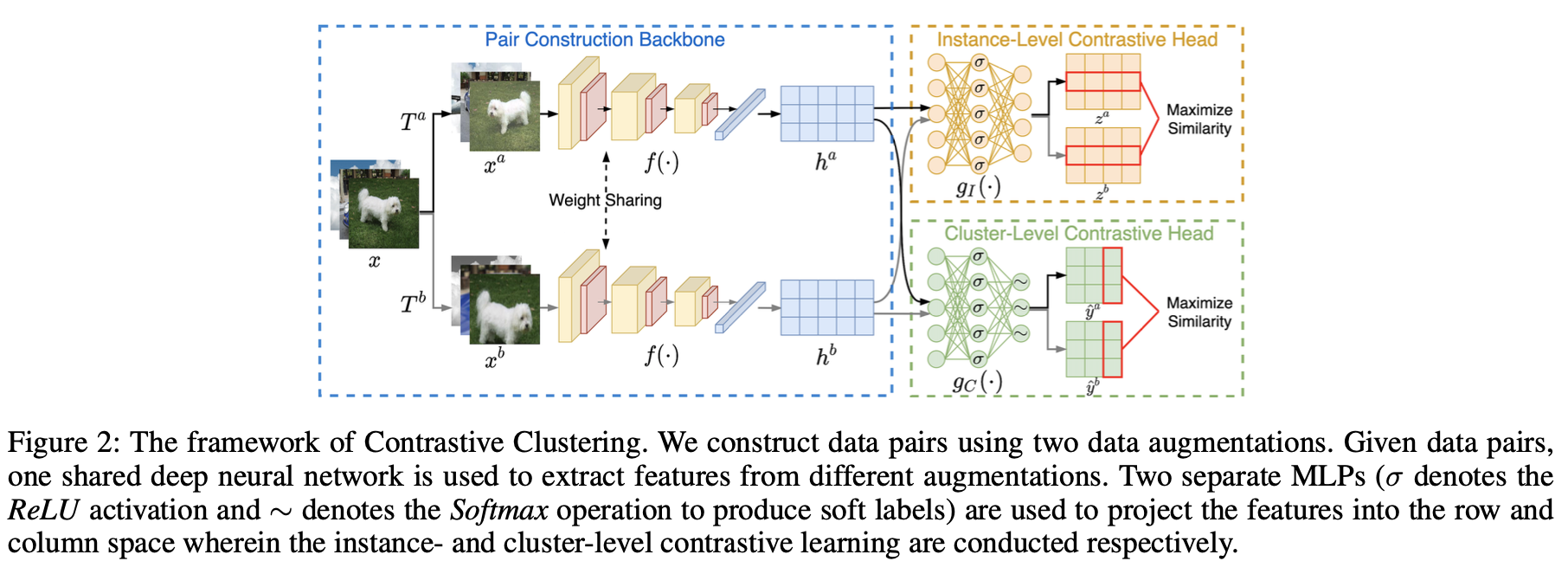
출처 : complete collapse problem
출처 : dimensional collapse
논문[1] : Jing, L., Vincent, P., LeCun, Y., & Tian, Y. (2021). Understanding dimensional collapse in contrastive self-supervised learning. arXiv preprint arXiv:2110.09348.
Strong augmentation의 일종인 AutoAugment 참고자료
출처 : MoCo

AI 새싹