
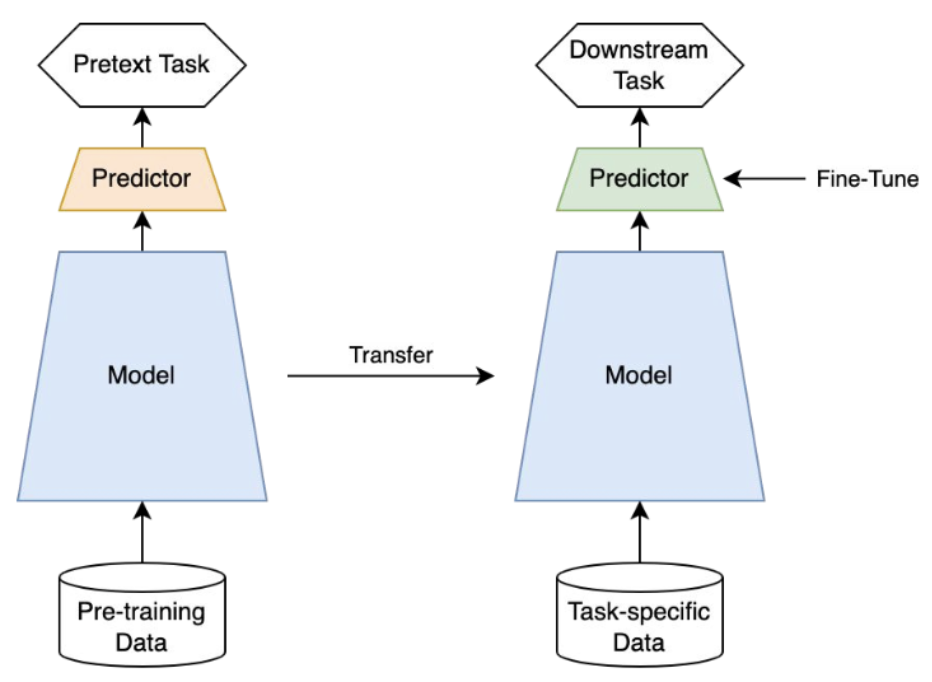
Self-Supervised Learning
- Supervision을 위한 대량의 labelled data를 얻기 위해서는 많은 cost를 사용해야한다.
- unlabelled dataset만으로 task-agnostic하게 데이터를 잘 표현하는 좋은 'representation'을 얻기위해 연구가 시작되었다.
- 즉 unlabelled dataset으로부터 좋은 representation을 얻고자하는 학습방식으로 representation learning의 일종이다.
- unsupervised learning과 다른 점은 label(y) 없이 input(x) 내에서 target으로 쓰일만 한 것을 정해서 즉 self로 task를 정해서 supervision방식으로 모델을 학습한다.
- self-supervised learning의 task를 pretext task라고 부른다.
- 해당 task를 통해 학습한 모델을 downstream task에 transfer하여 사용할 수 있으며 해당 downstream task의 성능으로 모델을 평가한다.
Method
- Self-prediction과 Contrastive learning으로 나눌 수 있다.
- Self-prediction
- 하나의 data sample내에서 한 파트를 통해서 다른 파트를 예측하는 task를 말한다.
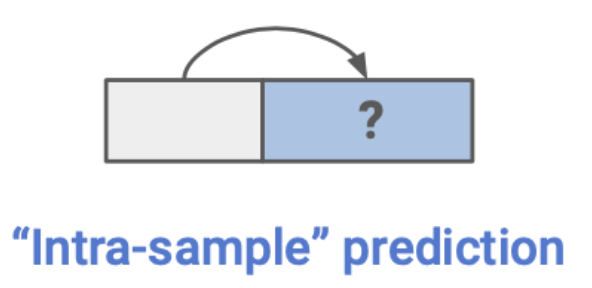
- 하나의 data sample내에서 한 파트를 통해서 다른 파트를 예측하는 task를 말한다.
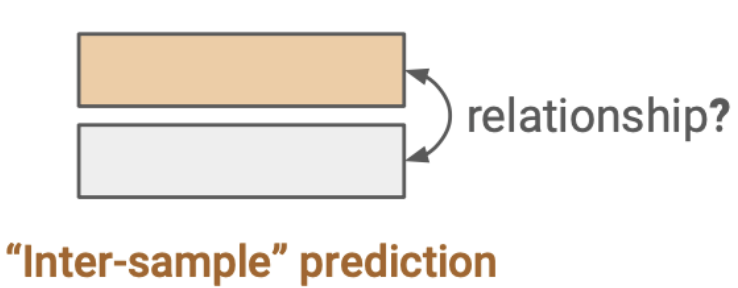
- Contrastive learning
- batch내의 data sample들 사이의 관계를 예측하는 task를 말한다.
- 두 샘플 사이의 관계를 학습하는 방식은 multiview learning에서 기원한 것이다.
- multiview learning은 같은 class를 가지는 두 샘플(positive samples)간의 공통 부분(=identity를 보여주는 부분=중요한 부분)을 학습하기 위한 방식이었다.
- 대표적으로 CCA(Canonical Correlation Analysis)를 예로 들 수 있다. 이런 방식들은 Siamese network를 기반하고 있으며, representation collapse라는 치명적 문제를 가지고 있어 이를 극복하기 위해 negative sample을 갖는 contrastive learning(SimCLR, MoCo등)으로 발전하거나 EMA(Exponential Moving Average)기반 Teacher-student 구조를 갖는 모델들(BYOL, DINO, SimSiam등)로 발전했다.
- 그러므로 contrastive learning은 관계를 학습하는 방식인 Multiview learning의 subset으로 볼 수 있다.
- batch내의 data sample들 사이의 관계를 예측하는 task를 말한다.
Self-prediction
- Autoregressive generation
- Autoregressive 모델의 경우 이전의 behavior를 통해 미래의 behavior를 예측한다.
- 예시 : GPT, PixelCNN
- Masked generation / prediction
- 정보의 일부를 마스킹하여 마스킹되지 않은 부분을 통해 missing영역을 예측하도록 한다. 이를 통해서 과거정보 뿐 아니라 앞뒤 문맥을 파악하여 relational 정보를 이해할 수 있다.
- 예시 : BERT
- Innate relationship prediction
- segmentation이나 rotation 등의 transformation을 하나의 샘플에 가했을 때도 본질적인 정보는 동일할 것이라는 가정으로 relationship을 prediction하는 방식이다.
- 예시 : segment shuffle로 순서를 예측, jigsaw 퍼즐 풀기
- Hybrid self-prediction
- 앞선 여러가지 방식을 활용
- 예시 : DALL-E
Contrastive learning
- Contrastive learning의 목적은 embedding space에서 유사한 sample pair들은 거리가 가깝게 그리고 유사하지 않은 sample pair의 거리는 멀게 하는 것이다.
- 유사한지/유사하지 않은지에 기준이 되는 현재 data point를 anchor라고 한다.
- anchor와 유사한 샘플을 positive point라고 하고 anchor와 positive pair를 이룬다. 반대로 anchor와 유사하지 않은 샘플을 negative sample이라고 하고 이는 anchor과 negative pair를 이룬다.
- Anchor : 기준이 되는 데이터 샘플
- Positive pair : 기준이 되는 데이터 샘플과 같은 class를 가지는 상관관계가 높은 데이터 샘플
- View : anchor와 같은 semantic을 가지는 데이터샘플 (positive sample). anchor와 동일한 의미를 가지는 다른 샘플들을 생성할 수 있다. anchor 기준으로부터 augmentation을 한 샘플이나 아예 다른 modality가 view가 될수도 있다
- Negative pair: 기준이 되는 데이터샘플과 다른 class를 가지는 상관관계가 낮은 데이터샘플
- Background and theories : Siamese network를 기반으로 발전
- 입력으로부터 얻은 두개의 augmented views x1, x2에 대한 latent를 matching시키는 방식으로 작동하는 unsupervised learning
- different view간의 correlation을 최대화하거나 distance를 최소화하는 방식으로 작동
- 하나의 사물에 대해 다양한 관점으로 보며 다양한 관점들의 공통의 정보를 추출
- distance loss의 경우 모델의 출력이 constant가 되어도 loss가 작아질 수 있음 즉 representation이 잘 학습되지 않는 representation collapse 현상 발생
- 이를 해결하기 위해 negative sample이 등장하는 contrastive learning 방법 등장
- large batch size를 필요로하며 dimensional collapse을 해결하지는 못했음 (다음 게시물 참고)
- 공통 정보 추출은 infoNCE loss를 제안한 논문에서 이론적인 증명을 하였으며 view들 사이의 mutual information의 lower bound가 됨을 증명
-
constrastive learning
-
Alignment and Uniformity on the Hypersphere
- Alignment : 같은 class인 샘플들이 가까운 위치에 있어야함
- positive pair간 가까워지는 것이 alignment에 기여
- uniformity : 각각의 instance가 고유의 특성을 유지
- negative pair간 멀어지는 것이 uniformity를 만족하는데 기여
- negative pair간 같은 class의 샘플들도 존재, 같은 class의 샘플들 사이에서도 서로 다른 특징이 존재하는데 이를 살림
- Alignment : 같은 class인 샘플들이 가까운 위치에 있어야함
-
Inter-sample classification
- instance를 구별하는 일종의 classification task를 pretext task로 사용
- simliar(”positive”)와 dissimilar(”negative”) 후보들이 주어질 때, anchor data point와 simliar한게 무엇인지를 구별하는 pretext task
- 대표 논문 : MoCo, SimCLR
- positive sample과 negative sample을 어떻게 선정하는지가 성능에 크게 영향
- positive pair 고르는 방법 : augmentated view를 통해 원본의 distorted version을 만듬, 하나의 데이터에 대한 diffrent view 예로 RGB중 각 한채널씩만 가져가기 등
- negative pair 고르는 방법 : label이 있다면 label 정보 활용, 간단한 방법은 anchor가 아닌 다른 샘플들을 negative pair로 본다.
- batch내에 anchor와 positive인 샘플이 있다면 오히려 학습에 방해
- negative sample은 갯수가 많을 수록 representation collapse를 방지하는데 효과가 좋음 그래서 batch size를 크게 하거나 memory bank를 활용하는 방식을 사용하기도 함
- InfoNCE
- NCE에서의 noise를 multiple로 확장한 loss
- target data를 관계가 없는 noise samples와 구분하기 위해 categorical cross-entropy loss를 사용
- positive sample의 context vector와 input vector의 mutual information을 크게 가져가는 효과가 있다.
- infoNCE는 view들간의 mutual information의 lower bound(하계)이므로 이를 minimize 하는 것은 view들 사이의 mutual information을 maximize 하는 것
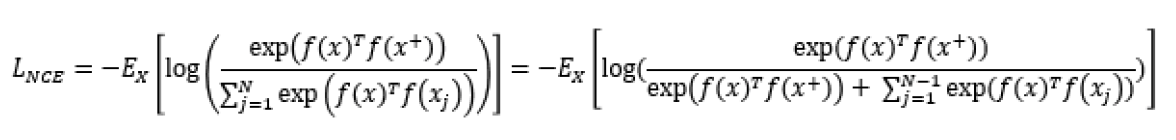
- positive pair간의 dot product는 크게, negative pair간의 dot product는 작게
-
Feature clustering
- positive pair 생성으로 instance를 discriminatio하는 것이 아니라 encoder를 통해 학습된 feature representation으로 데이터 샘플들을 clustering함으로써 만들어진 class들에 pseudo-label을 명시적으로 달고 이를 토대로 inter-sample classification을 진행하는 방식
- batch내의 anchor이외의 나머지 샘플들을 모두 negative sample로 보는 문제에 대한 대안으로 볼 수 도 있다.
-
Non-contrastive methods
- Contrastive learning의 가장 큰 단점은 representation collapse를 해결하기 위해 많은 negative sample이 필요하다는 것
- 그렇기에 negative pair가 없어도 이런 문제를 극복할 수 있는 방식들이 많이 개발
-
출처 : SSL
infoNCE : Oord, A. V. D., Li, Y., & Vinyals, O. (2018). Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.

AI 새싹