ALBERT : A Lite BERT 에 대해 알아보자
BERT
Bidirectional
Encoder
Representations from
Transformers.
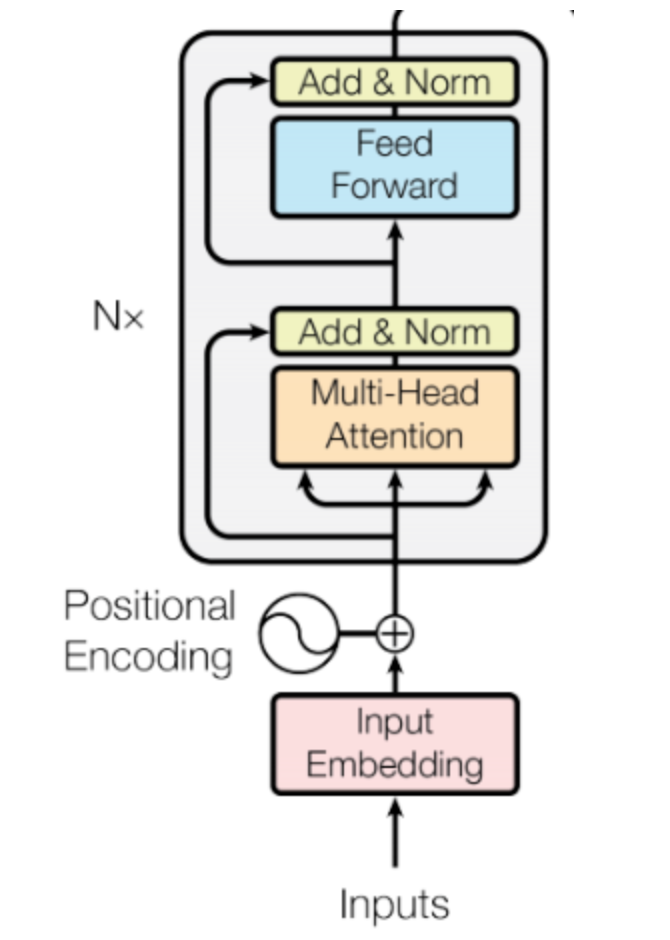
BERT의 내부는 Transformer와 거의 동일하다.
BERT는 Transformerd의 Encoder를 활용하여 만들어졌으며 Masked Language Model이다.
BERT는 pre-training을 2가지 task를 통해 진행하였다.
- Masked Language Model
- 중간 단어를 가리고(15%), 원래 단어가 무엇인지 예측하는 방식
- Two sentence Task(Next Sentence Prediction)
- 2개의 문장이 주어졌을 때 서로 붙어서 나타나는 문장인지 예측하는 task
하지만 BERT의 parameter가 커질 경우 GPU 메모리 한계 문제와 Inference가 느린 문제가 발생하였고 이에 BERT의 세부적인 내용과 파라미터 수를 개선한 ALBERT가 등장하였다.
ALBERT
발췌 : ALBERT 논문 리뷰
ALBERT에선 파라미터 감소와 학습 속도를 올리기 위해 다음과 같은 테크닉을 사용하였다.
- Factorized Embedding Parameterization
- 임베딩 행렬을 두 행렬로 분해하고, 히든레이어와 단어 임베딩을 분리하였다.
- Cross-Layer Parameter Sharing
- Transformer의 각 Layer간 같은 파라미터를 공유
- Sentence-Order Prediction
- NSP 대신 문장 사이의 순서를 학습하여 문장간의 일관성을 효율적으로 학습시킨다.
모델의 크기가 클 때 발생하는 문제점
일반적으로 모델은 크기가 클 때 성능이 좋지만 크기를 키웠을 때 메모리가 부족하거나 학습 시간이 너무 오래 걸리는 문제 등이 존재한다.
또한 본 논문은 일반적인 상식과 다르게 모델이 너무 커지면 성능이 떨어짐을 실험적으로 보여준다.
Memory Limitation
모델이 클 경우 메모리량이 부족하여 OOM이 발생할 수 있다.
예시로 VRAM 12GB인 Titan X GPU를 사용할 때, BERT Large에 Input Sequence가 384 이상이면 Max Batch Size가 0이 되는 문제가 발생한다.
Training Time
BERT Base의 경우 16개의 TPU로 4일의 기간이 소요되었다.
Large의 경우 64개의 TPU로 4일의 기간이 소요되었다.
BERT Base를 V100 16개의 GPU를 통해 학습할시 5일 이상, Large의 경우 64개의 V100 사용시 8일 이상이 소요된다.
Model Degradation
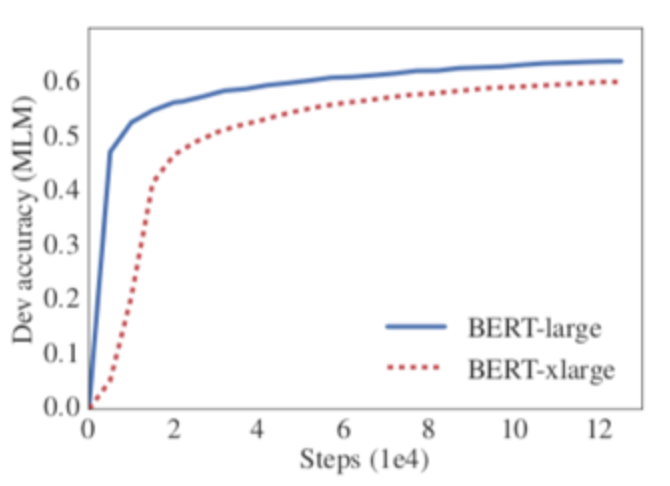
ALBERT 논문은 모델의 크기가 크다고 성능이 항상 높아지지 않음을 실험적으로 보여준다.
BERT Large보다 hidden size가 2배 큰 XLarge 모델이 성능이 오히려 떨어진다.
모델의 크기는 줄이며 성능은 높이기
앞선 문제점들을 극복 하기 위해 BERT에서 모델의 크기를 줄일 수 있는 방법과 NSP를 대체할 수 있는 방안을 제시합니다.
Factorized embedding parameterization
BERT에서는 Input Token Embedding Size(E)와 Hidden Size(H)가 같다.
ALBERT에서는 E를 H보다 작게 설정하여 Parameter 수를 줄인다.
E에서는 각 Token의 정보를 담고 있는 Vector를 생성하며, H에서는 Token들의 관계를 반영한 Contextualized Representation을 가지기에 담고 있는 정보량의 차이가 있을 것으로 가정하였다.
이에 E를 H보다 작게 설정하였다.
하지만 E와 H가 달라지면 차원이 맞지 않기에 Layer을 한 개 추가하였다.
그렇기에 기존 BERT의 x matrix를 x , x 로 변경하였다.
기존 BERT의 경우 가 약 30,000으로 상당히 크고 는 작은 값이기에 파라미터 수를 줄일 수 있었다.
Cross-layer parameter sharing
Cross-layer parameter sharing은 Transformer layer간 같은 파라미터를 공유하며 사용하는 것이다.
이는 각 Layer의 output이 다시 input으로 들어가는 형태로 Recursive Transformer라고 볼 수 있다.
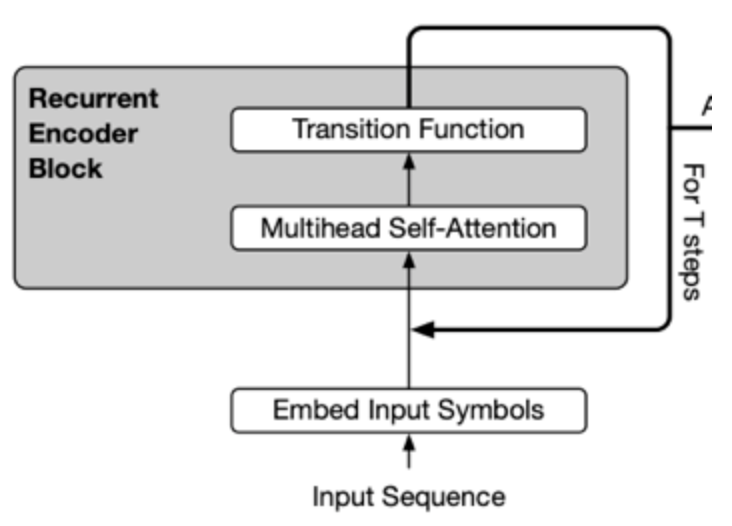
해당 방식을 통해 Self-attention Layer만을 공유 했을 때는 성능이 크게 떨어지지 않았지만 Feed Forward Network를 공유시에는 성능이 다소 떨어졌다.
Sentence Order Prediction
본 논문에서는 NSP 대신 Sentence Order Prediction(SOP)를 사용한다.
NSP는 첫 문장의 다음 문장을 맞출 때 실제 문장(positive sample) 혹은 임의의 문장(negative sample)을 사용하는데 이 때 임의로 뽑은 문장이 첫 문장과 연관성이 높을 가능성이 낮기에 너무 쉬운 태스크로 오히려 성능 하락에 원인이 되었다.
이에 반해 SOP는 실제 연속인 두 문장의 순서를 앞뒤로 바꾼 것과 원본으로 구성되며 문장의 순서가 옳은지 여부를 체크하기에 연관관계를 NSP보다 잘 학습할 것이라 가정하였다.
모델 성능
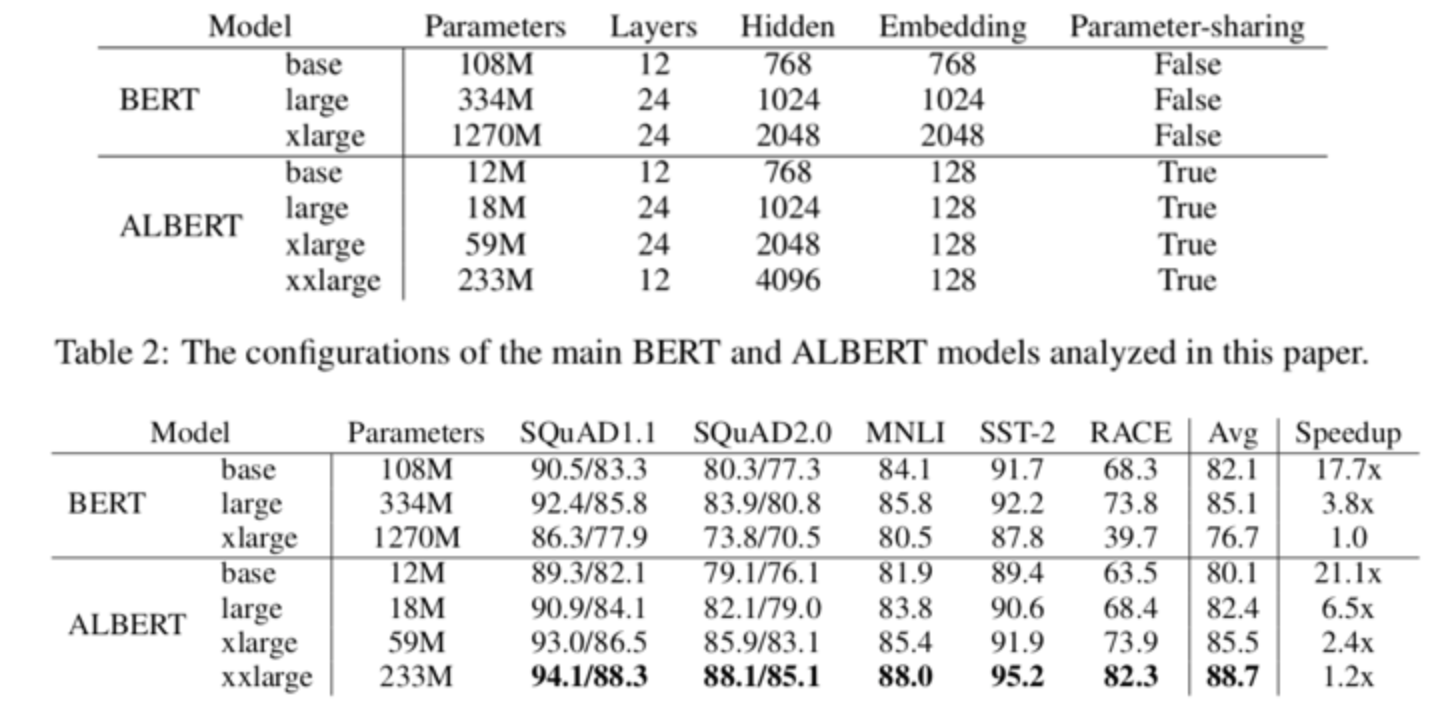
이는 모델의 성능을 향상시키며 모델의 크기를 줄일 수 있다는 Contribution을 주었다.
