
2차 프로젝트가 끝이 났다! 사실 한달전에 끝이 났다(🙀? 2차 프로젝트 끝나고 체력부족...으로 느낀점을 메모만 해놓고 글을 작성하지 못했다.)
기업협업이 끝난 지금 2차 프로젝트 스킵하고 바로 기업협업글을 작성해도 되지만 매 새 프로젝트를 할 때마다 달라지는 내 모습을 기록에 남기는 것도 나중에 돌이켜 봤을 때 꽤 흐믓할 것 같기 때문에 적어보기로 했다.
그럼 기업협업을 하기 전인 한달 전의 나로 빙의해서 글을 작성해보기로 했다. (중간중간 인지부조화가 올 수도 ㅎㅎ....)
1차프로젝트에서의 교훈
이전 게시글인 1차 프로젝트 돌아보기에서 말미에 적었던 것처럼 이번 2차 프로젝트에서는 총 3가지를 신경쓰기로 했다.
체력, 욕심줄이기, 테스트
체력
1차 프로젝트에서 체력이 부족했던 이유는 우선 개발을 처음해보고 프레임워크가 낯설다보니 더욱 시간을 갈아넣을 수밖에 없었던 것 같다. 더욱이 구현하고 싶은 기능은 많았으나 실력부족으로 더욱 체력의 한계까지 밀어붙였던 것 같다.
물론 기능을 추가로 할 수 있었으나 이번에는 더많은 기능 구현보다는 안정적인 기능을 구현하고 조금 더 자신을 돌보기로 했다. 이를 위해서 삽질의 시간을 줄였다.
삽질하는 게 사실 그 순간에는 힘이들지만 막상 해결하고나면 그만큼 쾌감을 주는 것이 없는 것같다. 다만 이번 2차프로젝트에서 내가 맡은기능들은 대부분 1차에서 이미 구현한 동기들이 있었다. 그래서 기능에 대해서 2시간 정도 고민을 해보고 답이 떠오르지 않으면 해당기능이 나온 코드를 참고했다.
이 과정에서 '왜 이렇게 구현했지?'하는 코드는 직접 그분에게 질문을 해서 맥락에 대해서 물어보려고 했다. 거인(까지는 아니더라도)의 어깨위에서 기능의 구현보다는 기능의 안정성과 효율성에 대해서 고민을 할 수 있었다.
욕심줄이기
위에 언급한 것처럼 2차 프로젝트에서는 욕심을 많이 줄여서 기능의 안정성이 최우선이고 그 이후에 효율성을 끌어올리기 위해 노력했다.
특히 이 때 db hit를 줄이는 prefetch related, aggregate 을 새롭게 사용해보았다. 실제로 logging을 찍어 sql 쿼리를 확인을 해보니 눈에 띄게 쿼리가 줄어들었다.
추가적으로 테이블을 계속 만들고 지우지 않고 테스트를 빠르게 진행하도록 classmethod를 사용했다.
만일 기능을 더 만들려고 했다면 이런 시도를 하지는 못했을 것 같다. 이렇데 코드를 작성하고 나니 시연발표를 할 때 에러가 나올까봐 마음을 졸이지 않았다. (솔직히 조금은 걱정했다 ㅎ)
테스트
특히 2차프로젝트에서는 unit test를 필수적으로 하도록 멘토님이 요구하셨다. 처음해보는 unit test라 낯설었고 심지어 필터기능을 담당했기 때문에 테스트해야 하는 내용이 엄청났다. 다른분의 테스트 케이스 100줄을 합해 총 991줄의 테스트코드가 나왔다...(사실 프로젝트 기간의 반을 여기에....)
그래도 기존에 postman으로만 파악했을 때 잡아내지 못했던 경우도 잡아낼 수도 있어서 훨씬 서비스의 신뢰가 생겼던 것 같다.
프로젝트 결과
깔끔 그 자체!
발표 순서는 우리 팀이 1순위라서 훨씬 좋았다. 특히나 우리팀이 빠르고 깔끔하게 발표를 마무리해주어서 예전 8팀 발표 2시간 반 걸리던 것이 1시간 반만에 끝났다. 특히나 M:M관계의 필터를 시연할 때 제대로 작동하는 것을 보고 뿌듯했던 것 같다.
담당한 기능
자 이제 기술블로그 본연의 목적으로 돌아와서 기술적인 부분에 대해서 적어보려고 한다.
담당한 기능은 상품페이지 조회 API + 필터링 , 상품 검색 API 구현이었다.
자세한 코드는 깃허브에서 확인이 가능하다.
django q객체를 이용한 필터링
1차 프로젝트에서 담당했던 기능은 상품상세조회 API라서 필터링을 다룰 일이 없었다. 이번에는 상품 전체조회 API에 여러가지 필터링이 적용되는 API를 만들어야 했기 때문에 django에서 지원하는 q객체 q=Q()를 사용해서 여러개의 조건을 한 번에 적용하는 식으로 진행했다.
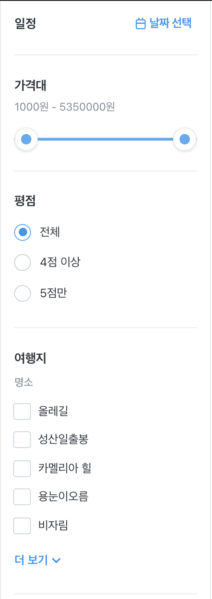
query parameter
쿼리 파라미터 원리
sub_category = request.GET.get("sub_category",None)
main_category = request.GET.get("main_category",None)
q = Q()
if sub_category:
q &= Q(subcategory__name = sub_category)
if main_category:
q &= Q(subcategory__maincategory__name = main_category)
원리라고 거창하게 적었지만 사실 프론트에서 값이 들어오면 truty하게 작성된 q 객체가 생성이 되어 적용되는 것이고 그렇지 않으면 false이기 때문에 그대로 지나간다.
범위 필터링
landmarks = request.GET.getlist("landmarks",None)
if score:
score =score.split("~")
q &= Q(average_review_score__gte = score[0])
q &= Q(average_review_score__lte = score[1])쿼리파라미터가 범위로 적용되는 부분이 점수, 날짜, 가격 총 3가지가 있었다. 이 부분은 처음 구현한 방법은 프론트에서 해당 데이터의 시작과 끝값 두가지를 보내주면 해당하는 리스트에서 값을 순서대로 가져와 gte,lte를 적용하는 방식으로 작성했다.
다른 방법을 찾아보면 getlist를 쓰고 &로 연결된 데이터를 리스트에 담아서 접근을 하는 방법이 있는데 위에 경우에는 직관적으로 범위를 보여주고자 그대로 진행을 했고 landmark부분은 2개이상의 값이 들어가는 경우가 있어서 getlist를 사용했다.
query 최적화를 위한 리팩토링
특히 애를 먹었던 부분은 랜드마크 부분이었다. 예를 들어서 제주도의 상품은 랜드마크라는 정보를 가지고 있는데 이게 상품 하나에도 여러개의 랜드마크를 가질 수 있었다. (예를 들어 택시투어는 올레길 , 성산일출봉에도 포함) 즉 M:M 테이블 관계에서 자료를 조회해야 했다.
이와 더불어 리뷰도 비슷한 구조를 가지고 있었다.
테이블 구조가 참조의 참조 형태로 설계를 하여서 쿼리가 생각보다 복잡하게 나왔다. 특히 이 부분은 로깅을 찍어보니 터미널이 쿼리로만 가득차서 무언가 해결이 필요함을 제대로 느낄 수 있었다.
이를 해결하기 위해서 prefetch_related 와 annotate를 사용해서 코딩했다.
prefetch_related로 DB hit 감소
products= Product.objects.all().prefetch_related(
'subcategory',
'subcategory__maincategory',
'option_set__date_set',
'review_set',
'region',
'region__landmark_set'
)product 모델 자체가 다른 테이블과 참조관계가 많다보니 만일 그냥 조회하는 방식으로 진행을 하면 매 필터를 적용할 때마다 해당 테이블을 풀스캔을 하게 된다. 지금은 클론코딩이고 해당하는 자료가 많아야 30개지만 이후에 1천개 이상 넘어가게 되면 hellgate가 열리게 된다.
따라서 처음 db hit를 할 때 참조된 테이블의 컬럼자료까지 한번에 가져와서 다음 필터링을 적용한다면 db hit를 눈에띄게 줄일 수 있다.
annotate로 필요한 요소 연산한 컬럼 구현
Products.all().annotate(
average_review_score = ExpressionWrapper(Coalesce(Avg('review__score'),0),output_field= IntegerField())).filter(q)annotate는 django에서만 제공하는 기능이 아니라 SQL자체 문법이다. 이걸 ORM적으로 풀어낸 것이 django의 annotate인데 이 부분은 review의 갯수와 리뷰의 score를 바탕으로 정렬을 할 때 사용하였다.
미리 리뷰 테이블의 자료를 가져와서 해당하는 리뷰들로 평균을 메긴 컬럼하나를 새로 만든 것처럼 작용하는 방법이다.
자주 조회할 예정인 컬럼이라면 미리 만들어두는 것이 매번 조회하는 것보다 효율적이다.
cf. Expression wrapper와 Coalesce같은 경우 unit test에서 null을 인식하지 못하는 에러가 나와서 해결하는 과정에서 넣은 코드다.
검색기능 구현
search_word = request.GET.get('search_word', None)
if search_word:
q &= Q(name__icontains = search_word)검색기능은 별도의 API를 만들지는 않고 기존 상품전체조회 API에 검색 키워드를 쿼리파라미터로 적용하는 방식으로 진행을 했다. 이런식으로 코딩을 하면 향후 서비스가 확대되어 다른 항공이나 숙박에 대해서 검색을 하는 메서드로 활용하지 못한다.
그럼에도 별도로 모듈화하지 않은 이유는 클론코딩의 목표자체가 여행상품에 타겟팅 되어있었기 때문에 추가로 함수화하지는 않았던 것 같다. 만일 다른 프로젝트나 현업에서라면 모듈화를 해서 함수의 재사용성을 높이도록 코딩할 것 같다.
추가로 검색기능도 icontains를 사용해 상품명 중에서 키워드를 포함한 것으로 사용을 했는데 현업에 가게 되면 조금 더 고도화된 검색기능을 공부하여 적용해보고 싶다.
구현 기능 테스트 코드 작성
이번 프로젝트에서는 unit test를 통해 기존에 postman에서 자체 통신테스트만 한 것보다 더 나아가 코드검증을 했다. 테스트가 필요한 로직에 사용된 테이블을 구성하고 해당 로직이 실행되었을 떄 결과 값도 미리 작성을 해서 에러를 검증했다.
필터링을 맡았기 때문에 만들어야 하는 테스트케이스도 많았고 거의 모든 테이블에 관련되어 있기 때문에 모든 테이블과 데이터도 다 만들어야 했다. 이 부분이 문제였는데 테스트 코드는 매 로직을 실행할때마다 새로 테이블을 만들고 데이터를 삽입하고 테스트가 끝나면 다시 테이블을 드랍한다. 로직 자체가 이게 계속 반복되다보니 한 번 만들고 테스트를 할 수 있는 방법에 대해서 고민을 했다. 특히나 삭제라든지 업데이트라든지 이런 로직이 아니라 조회만 하는 기능이었기 때문에 방법만 있다면 적용을 하면 좋을 것 같았다.
class ProductTestCase(TestCase):
@classmethod
def setUpTestData(cls):
MainCategory.objects.create(id=1,name='test')
SubCategory.objects.create(id=1,name='test', maincategory_id=1)
Region.objects.create(id=1,name='test')
User.objects.create(id=1,name='test', password='123')찾아보니 장고에서 unittest를 할 때 테이블 구성에서 @classsmethod를 적용하게 되면 이 부분이 적용이 된다고 했다. 실제로 기존에 2초 넘게 걸리던 시간이 1초 안쪽으로 계산되었다. 이렇게 불편함이나 의문이 있으면 방법이 있는지 찾아봐야겠다. (똑똑하신 분들이 이미 만든 게 많으니까!)
기능 구현 외적으로 무엇이 늘었나?
기능구현 + 최적화 + 안정성
기능구현과 더불어 코드의 성능과 그리고 에러가 발생하지 않도록 디버깅하는 과정까지 고려해야 한다는 점을 알게 되었다. 이 부분은 django가 아닌 다른 프레임워크를 공부하더라도 적용이 될 부분이니 원리를 파악하고 해당 프레임워크에서 제공하는 방법들을 익혀야겠다.
모듈화에 대한 고민
검색기능을 모듈화하지는 않았지만 그 일련의 고민 과정에서 모듈화에 대해서 고민해보게 되었다.내 기능에만 신경쓰는 것이 아니라 서비스 전체적인 시야로 코딩하는 것이 중요한 것 같다. 불필요한 코드의 반복은 안할수록 좋은 것이니까!
.jpeg)