
본 포스팅은 매주 토요일마다 진행되는, 교재 '파이썬 머신러닝 완벽 가이드'(권철민, 위키북스)를 활용한 스터디 활동 중에 작성한 포스팅입니다.
《 INTRO: 머신러닝, XGBoost, 위스콘신 유방암 데이터 세트 》
ⓐ 머신러닝 (Machine Learning; ML)
머신러닝의 방식 中, '지도학습'은
'지도학습':
레이블(Label), 즉 명시적인 정답이 있는 데이터가 주어진 상태에서 학습하는 방식입니다.
지도학습의 대표적인 유형인 '분류(Classification)'는
'분류(Classification)':
① 학습 데이터의 피처 & 레이블값(결정값, 클래스 값)을 머신러닝 알고리즘으로 학습해 모델을 생성하고,
② 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측하는 것입니다.
즉, 기존 데이터가 어떤 레이블에 속하는지에 대한 패턴을 알고리즘으로 학습한 뒤에, 새롭게 관측된 데이터에 대한 레이블을 판별하는 것입니다.
오늘 포스팅에서는 분류를 구현하는 다양한 머신러닝 알고리즘 中,
'앙상블 방법(Ensemble Method)'을 집중적으로 다뤄보려합니다!
1. 앙상블 방법
'앙상블 학습(Ensemble Learning)을 통한 분류':
"여러 개"의 분류기(Classifier)로부터의 예측들을 결합(ensemble)함으로써 단일 분류기보다 신뢰성이 높고 정확한 최종 예측을 도출하는 기법
앙상블은 '분류'에서 가장 각광 받고 있는 방법 중 하나입니다.
물론 이미지, 영상, 음성, NLP 영역에서는 현재 신경망에 기반한 딥러닝이 머신러닝계를 선도하고 있지만, 이를 제외한 정형 데이터의 예측 분석 영역에서는 앙상블이 매우 높은 예측 성능으로 많은 분석가와 데이터 과학자들에게 애용되고 있습니다.
앙상블은 일반적으로 '배깅(Bagging)'과 '부스팅(Boosting)' 방식으로 나뉩니다.
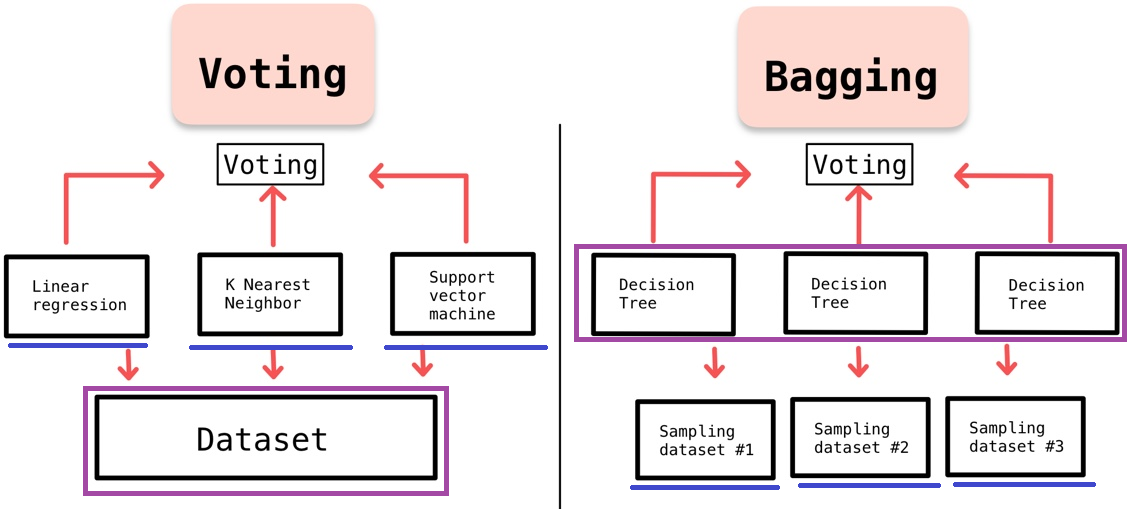
1) '배깅(Bagging)':
각각의 분류기가 모두 "같은" 유형의 알고리즘 기반이지만,
데이터 샘플링을 서로 '다르게' 가져가면서 학습을 수행하는 방식
- EX) 랜덤 포레스트 알고리즘cf) 보팅(Voting) vs. 배깅(Bagging)
'보팅(Voting)':
배깅과 달리, 일반적으로 서로 "다른" 알고리즘을 가진 분류기들을 결합하는 방식
2) '부스팅(Boosting)':
여러 개의 분류기가 "순차적으로" 학습을 수행하되, 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 앞의 분류기가 다음 분류기에게 "가중치를 부스팅"하면서 학습과 예측을 진행하는 방식
- 예측 성능이 뛰어나 앙상블 학습을 주도하고 있음
- EX) 그래디언트 부스트, XGBoost, LightGBM (Light Gradient Boost)
2. 결정 트리
'결정 트리(Decision Tree)':
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리(Tree) 기반의 분류 규칙을 만드는 것
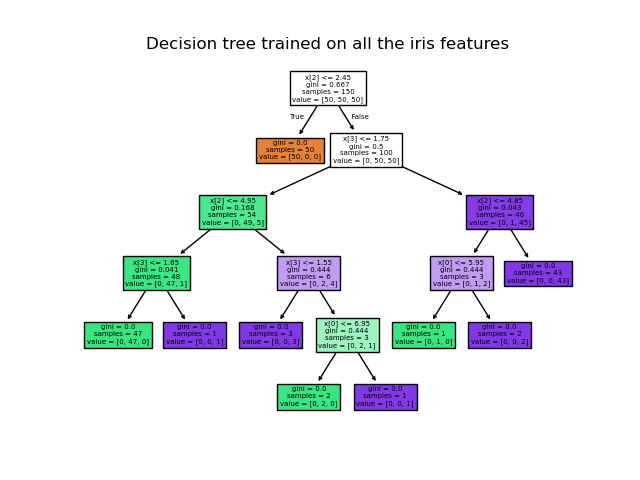
결정 트리는 ML 알고리즘 中 직관적으로 이해하기 쉬운 알고리즘이자, 앙상블의 기본 알고리즘입니다.
데이터의 어떤 기준을 바탕으로 규칙을 만들었는가에 따라 분류의 효율성이 결정되기 때문에, 결정 노드의 규칙이 알고리즘의 성능을 크게 좌우합니다.
ⓑ XGBoost
XGBoost는 트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나입니다.
유명한 캐글 경연 대회(Kagggle Contest)에서 상위를 차지한 많은 데이터 과학자가 이 XGBoost를 이용하면서 널리 알려졌습니다.
XGBoost의 주요 장점은 다음과 같습니다:
- 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간
- 과적합 규제
- Tree pruning (나무 가지치기)
- 자체 내장된 교차 검증
- 결손값 자체 처리
XGBoost의 핵심 라이브러리는 파이썬이 아닌 C/C++로 작성되어 있는데, XGBoost 개발 그룹이 파이썬에서도 XGBoost를 구동할 수 있도록 파이썬 패키지 "xgboost"를 제공하고 있습니다 😎👍
xgboost 패키지 내에는 '파이썬 래퍼 XGBoost'와 '사이킷런 래퍼 XGBoost'가 함께 존재합니다.
쉽게 말해,
-
파이썬 래퍼 XGBoost:
사이킷런과 호환되지 않는 독자적인 XGBoost 전용의 패키지 -
사이킷런 래퍼 XGBoost:
사이킷런과 연동할 수 있는 래퍼 클래스(XGBClassifier & XGBRegressor)를 제공하여 fit()과 predict()와 같은 표준 사이킷런의 개발 프로세스 및 다양한 유틸리티를 활용할 수 있도록 한 패키지
이렇게 이해하시면 됩니다 😁😁
아래 BODY 파트에서는
각각의 래퍼 XGBoost ( 파이썬 래퍼 XGBoost / 사이킷런 래퍼 XGBoost )로 위스콘신 유방암 예측을 실행해보고, 그 결과를 비교해보겠습니다!
ⓒ 위스콘신 유방암 데이터 세트
우리가 다루게 될 데이터 세트는 '위스콘신 유방암 데이터 세트'입니다.
(https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data)
위스콘신 유방암 데이터 세트는
종양의 크기, 모양 등의 다양한 속성값을 기반으로 종양을 '양성 종양(benign tumor)'과 '악성 종양(malignant tumor)'으로 분류한 데이터 세트입니다.
양성 종양은 비교적 성장 속도가 느리고 전이되지 않는 것에 반해, 악성 종양은 주위 조직에 침입하면서 빠르게 성장하고 신체 각 부위에 확산되거나 전이되어 생명을 위협하기 때문에 빠르고 정확한 예측이 필요합니다.
따라서 위스콘신 유방암 데이터 세트에 기반해 종양의 다양한 피처에 따라 악성종양인지 양성종양인지를 XGBoost를 이용해 빠르고 정확하게 예측해 보겠습니다!
《 BODY: 위스콘신 유방암 예측 》
cf)
XGBoost 설치는 아나콘다를 이용하면 쉽게 할 수 있습니다!
설치 방법은 아래 링크를 참고해보면 30초 컷으로 해결 가능합니다 :)
https://joylife052.tistory.com/entry/XGBoost-eXtra-Gradient-Boost-%EC%84%A4%EC%B9%98
❗아나콘다를 이용한 XGBoost 설치가 안 되시는 분들, 주목❗
conda 명령어 자체가 not found라고 한다 등등
이런 오류 때문에 아예 시작조차 못 하고 계신다면
그냥 "구글 colab(코랩)" 쓰십쇼...
기존에 있던 python이랑 충돌 나서 이러는 것 같은데
저도 이거 계속 붙잡고 있다간 쌓여있는 다른 할 일 못하게 될 것 같아서
일단 구글 코랩으로 실행 환경 돌렸습니다...
나중에라도 이건 해결해야 할 것 같은데 일단 저처럼 지금 당장이 급하다면 then 구글 코랩 is the answer.. 입니다..
구글 코랩에서는 기본적으로 XGBoost도 내장되어있어서 설치도 필요 없습니다
(thank you해요, Sundar Pichai...)
아무튼 XGBoost 설치에 성공하셨다면
 '
'
위의 import 코드를 입력했을 때 아무런 에러 메세지가 나오지 않습니다 ㅎㅎ
일반적으로 머신러닝 모델을 구축하는 주요 프로세스는
① 피처 처리 (feature processing)
② ML 알고리즘 학습/예측 수행
③ 모델 평가
의 단계를 반복적으로 수행하는 것입니다.
저도 이 프로세스에 따라 위스콘신 유방암을 예측하는 머신러닝 모델을 구축해보겠습니다 😃😀
i) 파이썬 래퍼 XGBoost
① 피처 처리 (feature processing)
STEP 1-1. 필요한 모듈, 패키지 로드
import xgboost as xgb # xgboost 모듈 로딩
from xgboost import plot_importance # 피처의 중요도를 시각화해주는 모듈
import pandas as pd # 데이터 처리를 위한 패키지
import numpy as np # 선형대수와 통계를 위한 패키지STEP 1-2. 위스콘신 유방 데이터셋 호출
from sklearn.datasets import load_breast_cancer # 위스콘신 유방암 데이터 세트 ☞ 사이킷런에도 내장돼 있음
dataset = load_breast_cancer()STEP 1-3. 데이터를 DataFrame으로 로드 & 탐색
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
X_features= dataset.data
y_label = dataset.target
cancer_df = pd.DataFrame(data=X_features, columns=dataset.feature_names)
cancer_df['target']= y_label
cancer_df.head(3)
print(dataset.target_names)
print(cancer_df['target'].value_counts())
STEP 1-4. 데이터셋 분할 (학습용 / 테스트용 / 검증용)
# cancer_df에서 feature용 DataFrame과 Label용 Series 객체 추출
# 맨 마지막 칼럼이 Label임. Feature용 DataFrame은 cancer_df의 첫번째 칼럼에서 맨 마지막 두번째 칼럼까지를 :-1 슬라이싱으로 추출.
X_features = cancer_df.iloc[:, :-1]
y_label = cancer_df.iloc[:, -1]
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(X_features, y_label,
test_size=0.2, random_state=156 )
# 위에서 만든 X_train, y_train을 다시 쪼개서 90%는 학습과 10%는 검증용 데이터로 분리
X_tr, X_val, y_tr, y_val= train_test_split(X_train, y_train, test_size=0.1, random_state=156 )
print(X_train.shape , X_test.shape)
print(X_tr.shape, X_val.shape)
# 만약 구버전 XGBoost에서 DataFrame으로 DMatrix 생성이 안될 경우 X_train.values로 넘파이 변환.
# 학습, 검증, 테스트용 DMatrix를 생성.
dtr = xgb.DMatrix(data=X_tr, label=y_tr)
dval = xgb.DMatrix(data=X_val, label=y_val)
dtest = xgb.DMatrix(data=X_test , label=y_test)② ML 알고리즘 학습/예측 수행
STEP 2-1. XGBoost의 하이퍼 파라미터 설정
params = { 'max_depth':3,
'eta': 0.05,
'objective':'binary:logistic',
'eval_metric':'logloss'
}
num_rounds = 400STEP 2-2. XGBoost 모델 학습 (← 학습용)
# 학습 데이터 셋은 'train' 또는 평가 데이터 셋은 'eval' 로 명기합니다.
eval_list = [(dtr,'train'),(dval,'eval')] # 또는 eval_list = [(dval,'eval')] 만 명기해도 무방.
# 하이퍼 파라미터와 early stopping 파라미터를 train( ) 함수의 파라미터로 전달
xgb_model = xgb.train(params = params , dtrain=dtr , num_boost_round=num_rounds , \
early_stopping_rounds=50, evals=eval_list )
STEP 2-3. 테스트 데이터셋 예측 (← 테스트용)
pred_probs = xgb_model.predict(dtest)
print('predict( ) 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨')
print(np.round(pred_probs[:10],3))
# 예측 확률이 0.5 보다 크면 1 , 그렇지 않으면 0 으로 예측값 결정하여 List 객체인 preds에 저장
preds = [ 1 if x > 0.5 else 0 for x in pred_probs ]
print('예측값 10개만 표시:',preds[:10])
③ 모델 평가
STEP 3-1. 예측 성능 평가
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))get_clf_eval(y_test , preds, pred_probs)
STEP 3-2. 시각화
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)
plt.savefig('p239_xgb_feature_importance.tif', format='tif', dpi=300, bbox_inches='tight')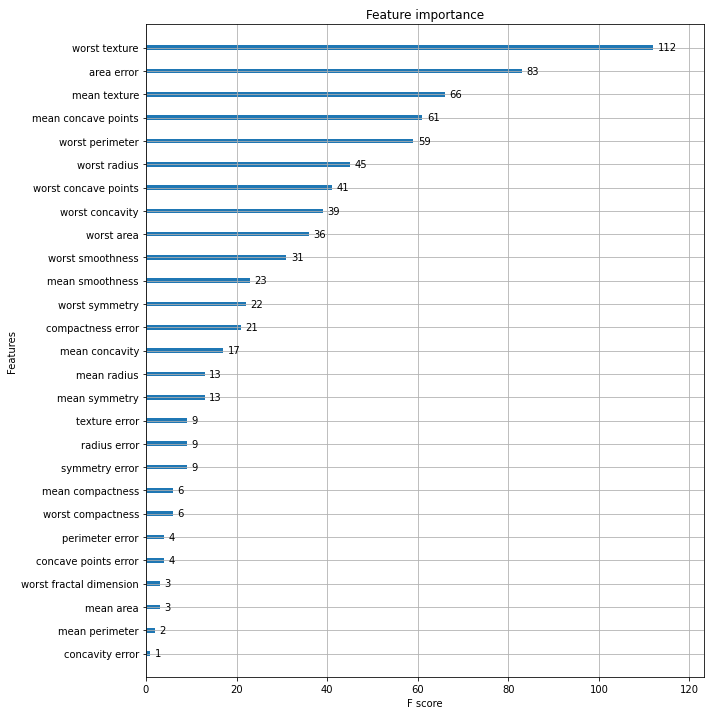
ii) 사이킷런 래퍼 XGBoost
① 피처 처리 (feature processing)
STEP 1. 사이킷런 래퍼 클래스 XGBClassifier import
# 사이킷런 래퍼 XGBoost 클래스인 XGBClassifier 임포트
from xgboost import XGBClassifier② ML 알고리즘 학습/예측 수행
STEP 2-1. XGBoost의 하이퍼 파라미터 설정
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3, eval_metric='logloss')STEP 2-2. XGBoost 모델 학습 (← 학습용)
xgb_wrapper.fit(X_train, y_train, verbose=True)STEP 2-3. 테스트 데이터셋 예측 (← 테스트용)
w_preds = xgb_wrapper.predict(X_test)
w_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]③ 모델 평가
STEP 3-1. 예측 성능 평가
get_clf_eval(y_test , w_preds, w_pred_proba)
STEP 3-2. 시각화
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3)
evals = [(X_tr, y_tr), (X_val, y_val)]
xgb_wrapper.fit(X_tr, y_tr, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)
ws100_preds = xgb_wrapper.predict(X_test)
ws100_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]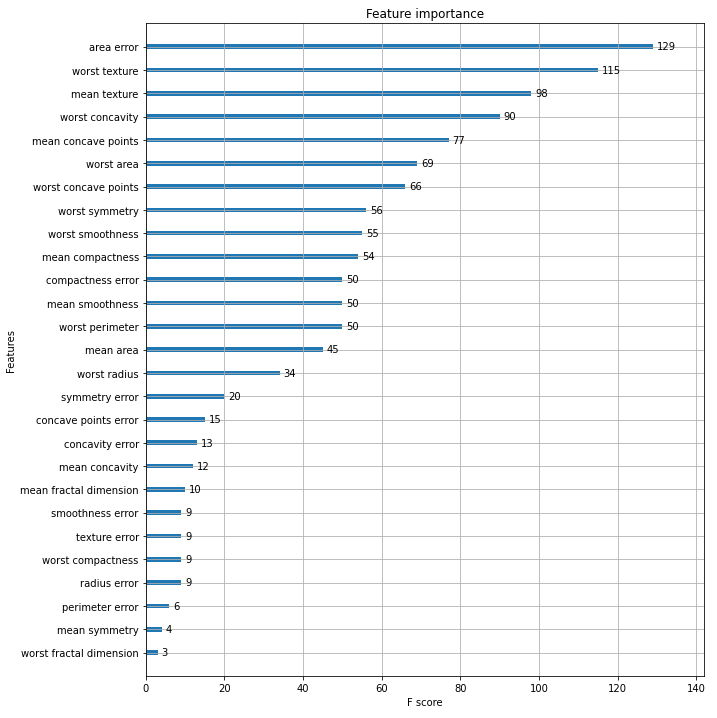
《 Outro: 파이썬 래퍼 XGBoost vs. 사이킷런 래퍼 XGBoost 》
파이썬 래퍼 XGBoost와 사이킷런 래퍼 XGBoost 각각의 'STEP 3-1. 예측 성능 평가' 단계에 집중해보면,
i) 파이썬 래퍼 XGBoost
ii) 사이킷런 래퍼 XGBoost
사이킷런 래퍼 XGBoost가 파이썬 래퍼 XGBoost보다 더 좋은 평가 결과가 나온 것을 확인할 수 있습니다!
이유는, 위스콘신 데이터셋도 원체 작은 편이었는데,
파이썬 래퍼 XGBoost에서는 조기 중단을 위해 최초 학습 데이터인 X_train을 다시 학습 X_tr과 X_val로 분리하면서 최종 학습 데이터 건수가 작아졌기 때문에 모델 성능이 낮아진 것으로 추정됩니다.
위스콘신 데이터셋이 작기 때문에 전반적으로 검증 데이터를 분리하거나 교차 검증 등을 적용할 때 성능 수치가 불안정한 모습을 보입니다.
하지만 데이터셋이 큰 경우에는, 원본 학습 데이터를 다시 학습과 검증 데이터로 분리하고, 여기에 조기 중단 횟수를 적절하게 부여하면, 일반적으로는 과적합이 개선되어 모델 성능이 향상될 수 있습니다.

잘 읽었어요~