[논문 리뷰] Large-scale Video Classification with Convolutional Neural Networks
Activity Recognition
안녕하세요, 오늘도 새로운 논문 리뷰로 다시 돌아왔습니다.
이번에 리뷰한 논문은 2014년에 출간된 논문인데요. CNN을 이용한 영상 분류에 관한 논문입니다. 축구 영상을 분석하고 싶다면, 영상 분석을 먼저 알아야겠죠?
그래서 기본으로 돌아가서 차근차근 배워보려고 합니다.
본 논문은 약 10년 전인 2014년에 쓰여졌으므로 딥러닝 관련 최신 기술과 일부 이론들이 언급되지 않을 수 있다는 점 알아두시면 좋을 것 같습니다.
1. Introduction
이미지와 영상은 인터넷 상에서 쉽게 찾을 수 있습니다. 최근, CNN은 image recognition, segmentation, detection 등 이미지 콘텐츠들을 이해하기 위한 모델로서 정의되어 왔습니다.
이것이 가능했던 이유는, 막대한 수의 파라미터와 라벨링된 데이터 셋이 학습 과정에 투입되었기 때문입니다.
그래서 이미지 콘텐츠에 좋은 성능을 보여왔던 CNN을 이용해 large-scale video classification을 시도합니다.
그래서 하나의, 고정된 이미지 정보에만 접근하는 것이 아니라, 복잡한 시간 정보까지 포함하겠다는 것입니다.
그래서 CNN을 이에 적용하기 위해 먼저 여러 측면에서 살펴봅니다.
실용적 관점에서,
2014년 기준, 당시 아직 영상 분류 벤치마크가 없었습니다. CNN을 위한 데이터셋을 얻기 위해, 487개의 클래스로 분류된 100만개의 유튜브 영상 즉, 새로운 Sports-1M 데이터 셋을 수집했습니다.
모델링 관점에서,
다음과 같은 질문들에 대답하고 싶어합니다.
i) CNN 구조에서 어떤 시간적 연결 패턴이 영상의 로컬한 움직임 정보를 가장 잘 활용하는가?
ii) 추가적인 움직임 정보는 CNN의 예측에 얼마나 영향을 미치며, 전체 성능을 얼마나 향상시키는가?
계산적 관점에서,
CNN은 학습 시간이 많이 필요합니다. 시간 정보를 포함하면 더 많은 시간이 필요하죠. 이를 완화시키기 위해 모델을 2가지 처리 stream으로 분리합니다. 저해상도에서 특징을 학습하는 context stream과 고해상도에서 중앙 부분만을 대상으로 학습하는 fovea stream입니다.
입력 차원이 감소함에 따라, 분류 정확도를 유지한 채, 실행 속도가 2~4배 증가하는 것을 관찰했습니다.
이제 다음 질문이 자연스럽게 떠오릅니다.
Sports-1M 데이터 셋에서 학습된 특징들이 더 작은, 다른 데이터 셋에서도 충분히 일반화될 수 있는가?
그럼 당연히 tranfer learning, 전이 학습을 해보겠다는 것이죠.
Sports-1M에서 학습한 저수준 특징들을 재활용함으로써, UCF-101 데이터 셋을 단독으로 학습했을 때(41.3%)보다 훨씬 높은 성능(65.4%)을 보였습니다.
지금까지 언급된 내용들은 아래에 자세히 리뷰되어 있습니다.
2. Related Work
video classification을 위한 일반적인 접근법은 3단계입니다.
1. 로컬한 특징 추출
2. 고정된 크기의 벡터로 결합
3. classifier 학습
이 섹션에서는 지금까지(2014년 기준) 딥러닝이 발전해 온 과정을 나열하고 있습니다. 그래서 다수 생략합니다.
본 논문에서 사용하는 모델은 end to end 지도 학습으로 훈련된다고 언급합니다.
3. Models
이미지와 달리 영상은 고정된 크기로 자르거나 rescale하기 쉽지 않습니다. 본 연구에서는 그래서, 모든 영상들을 짧은 클립들의 묶음으로 취급합니다.
클립도 짧은 영상입니다, 따라서 연속적인 프레임들을 포함하고 있으므로 신경망을 시간 차원에 연결시켜 시공간적 특징을 추출할 수 있습니다.
그래서 3가지 연결 패턴을 이어서 소개합니다.
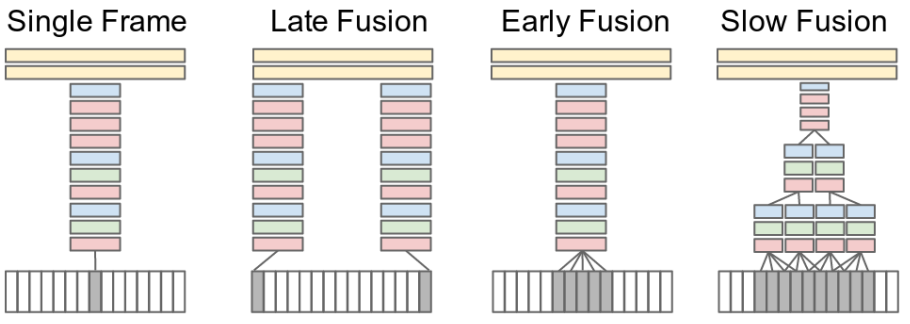
Early Fusion, Late Fusion, Slow Fusion입니다.
그 후, 계산 효율을 높이기 위해 다중 해상도 구조를 설명합니다.
3.1. Time Information Fusion in CNNs
이 섹션에서는 Single-frame, Early Fusion, Late Fusion, Slow Fusion을 설명하고 있습니다.
첨부된 그림을 보면서 설명해보겠습니다.
※ 파란색: pooling layer, 빨간색: convolutional layer, 녹색: normalization layer
Single-frame.
여러 Fusion 기법과의 비교를 위해 single-frame 베이스라인을 제시하고 있습니다. 이 신경망은 ImageNet challenge 우승 모델인 AlexNet과 유사합니다.
그러나, input이 기존의 224 x 224 x 3 이 아닌, 170 x 170 x 3 입니다.
그래서 input 크기의 차이를 제외한 AlexNet 전체 구조는 이렇습니다.
C(96, 11, 3)-N-P-C(256, 5, 1)-N-P-C(384, 3, 1)-
C(384, 3, 1)-C(256, 3, 1)-P-FC(4096)-FC(4096)
C는 convolutional layer이며 C(d, f, s)일 때,
d는 필터 개수, f는 필터 사이즈, s는 stride입니다.
N, P, FC는 각각 normalization layer, pooling layer, fully connected layer를 약칭합니다.
모든 pooling layer는 2 x 2 영역만큼 stride=2로 겹치지 않게 pooling합니다.
또, 모든 normalization layer는 Local Response Normalization을 수행합니다.
여기서 Local Response Normalization(LRN)은 AlexNet에서 사용한 정규화 기법입니다. 현재는 거의 사용되지 않고, Batch Normalization을 더 많이 사용하고 있죠. 그러나 CNN 구조 중간에 정규화를 수행한 시초가 되었다는 점은 중요하겠습니다.
Early Fusion.
Early Fusion은 전체 시간 창 사이의 정보를 먼저 결합합니다.
그림을 보면, 먼저 결합한 후 모델에 투입시키는 것을 볼 수 있죠.
이때 single-frame 모델에서 첫번째 convolutional layer의
필터를 11 x 11 x 3 x T 사이즈로 늘려서 실험합니다.
T는 시간적 범위를 뜻하며, T=10(약 1/3초, 10프레임)으로 설정했습니다.
즉, 몇 프레임을 한 번에 처리할 것인가를 T로 설정하는 것입니다.
이를 통해, 신경망으로 하여금 로컬한 모션의 방향과 속도를 감지할 수 있게 합니다.
Late Fusion.
Late Fusion은 2개의 single-frame 신경망을 배치합니다.
그림을 보면 쉽게 이해할 수 있습니다.
마지막 convolutional layer인 C(256, 3, 1)까지 15프레임만큼 떨어져 있는 파라미터들이 첫 fully connected layer에서 합쳐집니다.
그렇기 때문에, 두 개의 신경망 중 어느 하나라도 단독으로 모션을 감지할 수는 없습니다. 그러나, 두 개의 outputs을 비교하면서 첫 fully connected layer는 글로벌한 모션 특성을 계산할 수 있게 됩니다.
Slow Fusion.
Slow Fusion은 앞서 언급한 Early, Late Fusion의 균형있게 섞인 버전이라고 할 수 있습니다.
그래서 신경망 전반에 걸쳐 천천히 시간 정보를 융합시키며, 층이 깊어질수록 공간적, 시간적 차원에서 글로벌한 정보에 접근할 수 있습니다.
이는 기존 2D 합성곱을 3D 합성곱으로 확장시켜서 구현하는데 즉, 공간적 합성곱에 시간적 합성곱을 추가로 수행하는 것입니다.
"3D Convolutional Neural Networks for Human Action Recognition"에서 구현한 것을 착안했습니다.
이번엔 첫번째 convolutional layer의 필터를 T=4로 지정합니다. 4프레임을 한 번에 처리하겠다는 것이죠. stride=2로 하여 input을 10프레임 받게 됩니다.
그래서 그림처럼 4개의 응답을 얻게 되죠.
두번째, 세번째 층에서도 이를 반복합니다.
T=2, stride=2를 적용합니다.
그래서 세번째 convolutional layer는, input인 10프레임의 정보에 접근할 수 있게 됩니다.
3.2. Multiresolution CNNs
이 섹션에서는 학습 효율성에 집중합니다. CNN은 보통 큰 규모의 데이터 셋을 훈련하는데 많은 시간이 걸립니다.
그래서 본 연구에서는 모델의 성능을 유지한 채 속도를 향상시킬 수 있는 방법을 찾고자 합니다.
이때 신경망의 크기를 줄이는 대신, 저해상도의 이미지를 훈련하는 실험으로 진행했습니다. 그러나 이것이 모델 속도를 향상시키긴 했지만, 결국 이미지의 고주파 성분이 좋은 정확도를 기록하는 데 중요하다는 점이 드러났다고 합니다.
그 디테일들을 살펴보겠습니다.
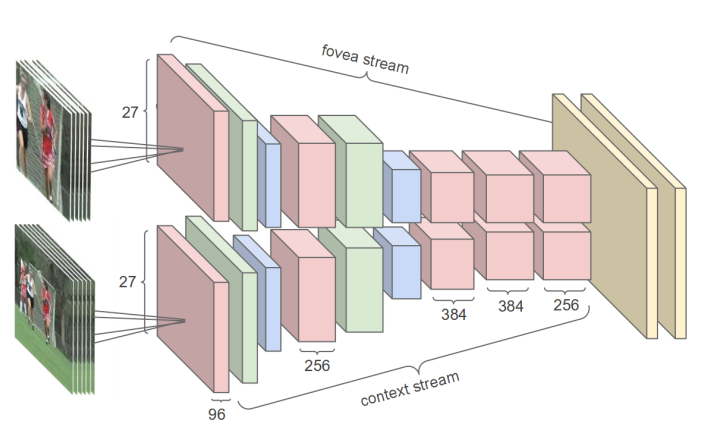
Fovea and context streams.
그림을 보면 알 수 있듯이 multiresolution 구조는 2가지의 다른 streams를 갖습니다. 저해상도와 고해상도가 바로 그것들의 입력이 되겠죠.
여기서는 178 x 178 프레임의 영상 클립이 신경망의 input입니다.
context stream은 원본의 해상도를 2배 줄인 89 x 89 를 받습니다.
fovea stream은 원본의 중앙 부분을 자른 89 x 89를 받습니다.
이렇게 하면, 전체 input 차원은 반으로 줄어듭니다.
추가 설명하자면, 현재의 많은 온라인 영상들은 중앙 지역에 중요 정보가 나타나는 경향이 있으므로, fovea stream이 강점을 갖는다고 합니다.
Architecture changes.
input이 반으로 줄어든 크기이므로, 마지막 pooling layer는 제거합니다. 왜 이렇게 할까요? 두 개의 streams가 7 x 7 x 256 크기로 유지되게끔 하기 위함입니다. pooling을 적용하면 크기가 더 줄어들테니까요.
두 개의 streams에서 활성값은 concat되어 첫 fully connected layer에 들어갑니다. 즉, 들어가는 값은 7 x 7 x 512 -> 25,088차원 벡터입니다.
3.3. Learning
Optimization.
경사하강법은 Downpour Stochastic Gradient Descent를 사용합니다.
간단하게, 여러 사람이 동시에 학습을 하고 결과를 중앙 서버에 모아 모델을 빠르게 업데이트하는 분산 학습 방식입니다.
그래서 복제 모델의 개수는 10~50개 범위이며, 각 모델은 다시 4~32개의 파티션으로 나뉩니다. 즉, 하나의 모델도 병렬, 복제도 병렬이라는 뜻입니다.
mini-batch: 32
momentum: 0.9
weigh decay: 0.0005
learning rate: 0.001
여기서 학습률은 validation error가 줄지 않으면 사람이 수동으로 낮추는 방식입니다.
Data augmentation and preprocessing.
데이터 전처리는 이렇게 진행됩니다.
중앙 영역을 자르고,
200 × 200 픽셀 크기로 리사이즈한 뒤,
무작위로 170 × 170 영역을 샘플링하고,
50% 확률로 수평으로 뒤집기.
이 전처리는 같은 클립의 모든 프레임에 적용됩니다.
마지막으로, 원본 픽셀 값에서 상수 117(전체 이미지 픽셀의 평균값)을 뺍니다.
4. Results
결과 섹션입니다. 여기서는 Sports-1M 데이터 셋에 대한 결과와 학습된 특징과 신경망 예측을 질적으로 분석합니다.
추가로, UCF-101에 대한 transfer learning, 전이 학습 실험을 설명합니다.
4.1. Experiments on Sports-1M
Dataset.
Sports-1M 데이터 셋은 487개의 클래스로 분류된 100만개의 유튜브 영상들로 구성되어 있습니다.
이 클래스들은 Aquatic Sports, Team Sports, Winter
Sports, Ball Sports, Combat Sports, Sports with Animals 등을 담고 있는 분류 체계이며, 수동으로(사람이) 정리한 체계입니다.
일반적으로 리프 노드로(아래로) 갈수록 점점 세분화됩니다.
예를 들어, 위 데이터 셋은 6개의 다른 종류의 볼링, 7개의 다른 종류의 미국 풋볼 그리고 23가지 종류의 당구를 포함하고 있습니다.
각 클래스마다 1000~3000개의 영상이 있으며, 대략 5%의 영상이 하나 이상의 클래스로 주석되어 있습니다. 이 주석(라벨)들은 영상 주변의 텍스트 메타데이터를 분석함으로써 자동으로 생성되었습니다. 즉, 영상 제목, 설명, 태그 등을 분석하여 자동 생성된 것입니다.
그래서 데이터는 2가지 경우로 약하게 주석되어 있는데요.
- 태그 예측 알고리즘이 틀리거나 제공된 설명이 실제 영상과 맞지 않다면, 영상의 라벨이 틀릴 수 있습니다.
- 영상이 맞게 주석되었어도, 프레임 수준에서는 여전히 상당한 변화를 보일 수 있습니다.
2번에 대해 더 자세히 설명해 보겠습니다. 예를 들어, 축구라고 태그된 영상은 축구 인터뷰, 축구 관중 등일 수도 있다는 것입니다.
데이터 셋 분할로 넘어갑니다.
데이터 셋은 training set: 70%, validation set: 10%, test set: 20%로 분할합니다.
유튜브가 중복 영상들을 포함할 수도 있으므로, 같은 영상이 training set과 test set에 동시에 나타날 수 있습니다.
이 문제가 얼마나 심각한지 알아보기 위해,
중복 프레임 탐지 알고리즘(near-duplicate finding algorithm)을 사용하여 모든 영상들을 처리했고, 전체 100만 개의 영상들 중 단 1755개만이 상당 부분의 중복 프레임을 포함하고 있음을 확인했습니다.
더 나아가서, 각 영상에서 최대 100개의 0.5초 길이의 클립을 무작위로 추출해서 사용하며 평균 영상 길이는 5분 36초이기 때문에, 동일한 프레임이 데이터 분할 간에 나타날 가능성은 낮다고 강조합니다.
즉, 데이터 중복은 큰 문제로 보지 않는다는 것이네요.
Training.
한 달 동안 모델을 학습시켰습니다.
단일 복제 모델 기준으로 속도를 비교해 보면, full-frame 신경망은 대략 초당 5개의 클립을 처리, multiresolution 신경망은 초당 20개의 클립을 처리했습니다.
초당 5개를 처리하는 속도는 최신 고성능 GPU(2014년 기준)가 낼 수 있는 속도의 20배 느린 수준입니다. 하지만 앞서 소개했듯이, 본 연구는 모델을 10~50개까지 복제해서 병렬적으로 사용하기 때문에 전체 처리 속도는 그에 필적할 것으로 예상합니다.
추가적으로, 샘플링된 프레임들로 구성된 데이터 셋은 약 5천만개일 것이며, 전체 신경망은 총 5억개의 예시를 봤을 것이라고 추정합니다.
Video-level predictions.
전체 영상에 대한 예측을 이끌어내기 위해, 랜덤하게 20개의 클립을 샘플링하고 개별적으로 신경망에 투입합니다.
모든 클립은 4번에 걸쳐 신경망을 통과하며(매번 다른 crop과 수평 반전을 적용한 상태로), 그때마다 나온 네트워크의 클래스 예측 결과를 평균하여, 보다 강건한 클래스 확률 추정값을 이끌어냅니다.
video-level 예측을 얻기 위해서, 각 영상에서 선택한 개별 클립의 예측값을 단순히 평균하는 가장 간단한 방법을 선택한 것입니다.
Feature histogram baselines.
CNN 구조들끼리 비교하는 것에 덧대어서, 특징 기반 접근으로도 정확도를 측정합니다.
표준적인 bag-of-words 파이프 라인을 따라서,
영상의 모든 프레임에서 여러 종류의 특징(feature)을 추출하고,
k-means 벡터 양자화를 이용해 이를 이산화한 뒤,
spatial pyramid encoding과 soft quantization 기법을 사용하여
히스토그램 형태로 단어를 누적합니다.
각 히스토그램은 합이 1이 되도록 정규화되며,
모든 히스토그램은 하나의 video-level 특징 벡터로 cancat되어 총 25,000차원을 갖습니다.
ReLU와 함께 다층 신경망을 사용하고 Softmax 분류기까지 사용합니다.
한 개의 층만 가지는 1층 신경망이 아닌 다층 신경망이 성능이 좋기 때문에 사용한 것입니다.
또한 cross-validation으로 하이퍼 파라미터 튜닝까지 실시했습니다.
Quantitative results.
20만개의 영상, 400만개의 클립들로 구성된 Sports-1M test set에 대한 결과입니다.
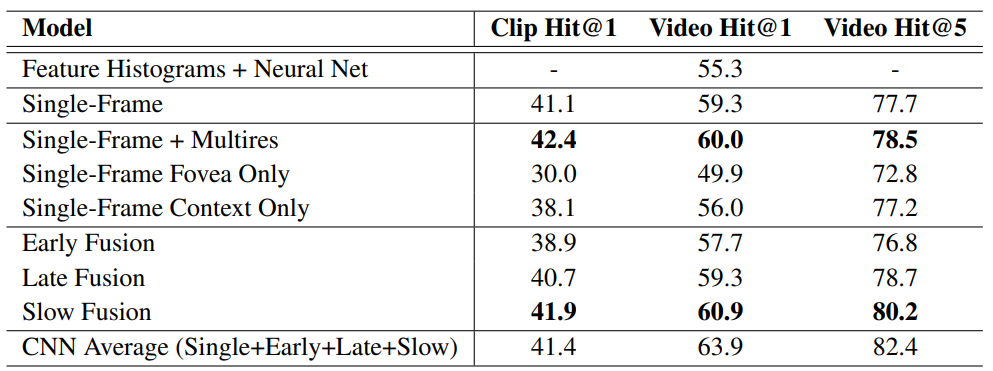
※ Hit@k 값은 예측한 상위 k개의 클래스 중 최소 하나라도 실제 정답 레이블이 포함되어 있는 경우의 비율을 나타냅니다.
테이블을 보면 알 수 있듯이, 본 논문의 신경망은 feature-based 베이스 라인을 아득히 능가하는 수준이라고 합니다.
feature-based 접근은 영상 전체 길이에 걸쳐 시각적 단어를 조밀하게 계산하고,
전체 video-level 특징 벡터에 기반하여 예측을 수행합니다.
반면, 본 논문의 신경망은 임의로 선택된 20개의 클립만을 개별적으로 입력받아 예측을 수행합니다.
게다가 앞서 언급했었던 라벨링 관련 노이즈가 있었음에도 불구하고 잘 학습한 것처럼 보입니다.
feature-based 방식과 관련하여 성능 차이가 크다는 점은 명확합니다.
그런데 다양하게 제시된 CNN 구조들 사이의 성능 차이는 놀랍도록 작았습니다.
single-frame 모델은 이미 좋은 성능을 보입니다.
추가로, foveated 구조는 input 차원을 줄였기 때문에 2~4배 학습 속도가 빨랐다고 합니다. 예상대로입니다.
정확한 속도 향상 비율은 모델 분할 방식과 구현 세부사항에 따라 달라질 수 있습니다. 하지만 본 실험에서는 다음과 같은 학습 속도 향상을 관찰했다고 합니다.
Single-frame 모델: 초당 6~21개 클립 처리 → 약 3.5배 속도 향상
Slow Fusion 모델: 초당 5~10개 클립 처리 → 약 2배 속도 향상
Contributions of motions.
추가적으로, single-frame 신경망과 motion 정보를 다루는 신경망 사이의 차이를 이해하기 위한 실험을 구현했습니다.
motion 정보를 다루는 신경망은 Slow Fusion 신경망을 선택했습니다.
(가장 성능이 좋았음)
그래서 모든 스포츠 클래스에 대해 클래스별 average precision(AP)를 계산 및 비교하고 가장 큰 차이를 보이는 것들을 강조합니다.
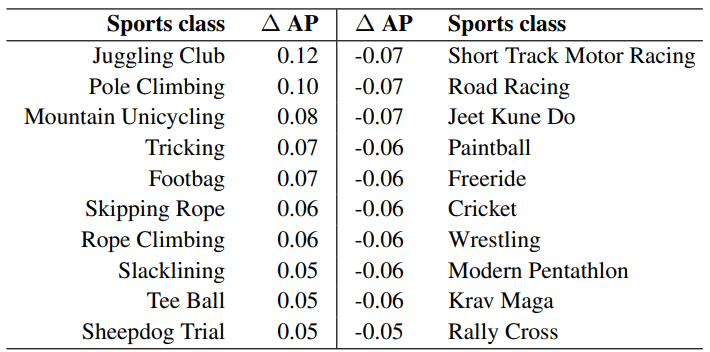
왼쪽은 Slow Fusion CNN이 single-frame CNN보다 더 잘 작동하는 클래스들,
오른쪽은 single-frame CNN이 Slow Fusion CNN보다 더 잘 작동하는 클래스들
직접 일부 관련 클립들을 조사해본 결과, motion-aware 신경망이 확실하게 이득을 본 몇몇 경우가 있긴 하지만 드물었습니다. 그림을 보겠습니다.

파란색: ground truth, 녹색: correct prediction, 빨간색: incorrect prediction
이 3가지 경우가 그 예시입니다, motion 정보와 함께 더 이득을 본 경우이죠. 이런 경우가 드물었다고 하는 겁니다.

대부분이 위 그림처럼 single-frame 만으로도 예측을 성공했다는 것이죠.
반면, 카메라 움직임이 존재하는 경우, motion-aware 신경망은 오히려 성능이 더 나빠질 가능성이 높다는 점도 관찰되었습니다.
논문은 이것을 CNN이 모든 카메라 변환(이동, 줌)의 각도와 속도에 대한 완전한 불변성(invariance)을 학습하는 데 어려움을 겪기 때문일 것이라고 가정합니다.
Qualitative analysis.
첫번째 convolutional layer의 학습된 특징들입니다.

자세하게는, multiresolution 신경망의 첫번째 층에서 학습된 필터들입니다.
왼쪽: context stream, 오른쪽: fovea stream
fovea stream은 회색조(grayscale)의 고주파(high-frequency) 특징들을,
context stream은 저주파(low-frequency) 정보와 색상(color)을 학습합니다.
추가로, 움직이는 영상 특징(GIF 형식)은 논문 첫 페이지에 링크된 웹사이트에서 볼 수 있습니다. -> 링크
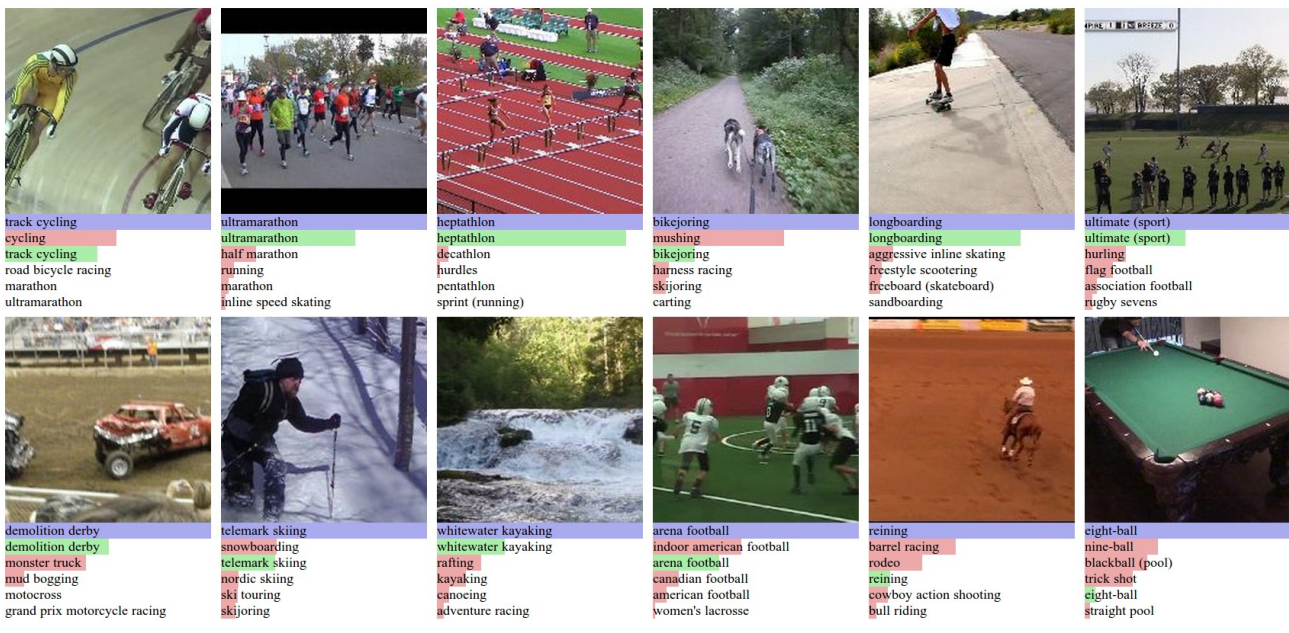
위 그림을 보겠습니다.
본 논문이 제시하는 신경망은 해석 가능한 예측을 하기도 하고 합리적인 오류를 범하기도 합니다.
추가로 confusion matrix 분석도 진행했으며,
대부분의 오류는 데이터 셋의 세분화된 클래스들 사이에서 발생했다는 점을 알 수 있습니다.
예를 들면, 모델이 가장 혼동한 top 5 클래스는 다음과 같습니다.
deer hunting vs hunting
hiking vs backpacking
powered paragliding vs paragliding
sledding vs toboggan
bujinkan vs ninjutsu
위에 첨부한 그림과 예시들을 놓고 보니 한 번에 이해가 됩니다.
4.2. Transfer Learning Experiments on UCF-101
Sports-1M 데이터 셋 분석 결과는 신경망이 강력한 motion 특징을 학습한다는 것을 보여줍니다.
그렇다면 이제 이러한 특징들이 다른 데이터 셋과 클래스에게도 일반화하여 적용시킬 수 있을지가 궁금한 것입니다.
그래서 UCF-101 Activity Recognition 데이터 셋에 transfer learning 을 수행하여 결과를 보려고 합니다.
이 UCF-101 데이터 셋은 5개의 큰 그룹으로 분리되어 101개의 카테고리를 가지는 데이터 셋입니다. 영상은 총 13,320개입니다.
- Human-Object interaction (Applying eye makeup, brushing teeth, hammering, etc.),
- Body-Motion (Baby crawling, push ups, blowing candles, etc.),
- Human-Human interaction (Head massage, salsa spin, haircut, etc.),
- Playing Instruments (flute, guitar, piano, etc.),
- Sports
이러한 분류 덕분에, 스포츠 클래스에서의 성능과 비스포츠 클래스들과 별도로 따로 분석할 수 있게 됩니다.
Transfer learning.
이제 전이 학습을 본격적으로 시작합니다.
이때 4가지 경우로 나눠서 실험을 진행합니다.
-
Fine-tune top layer.
4096차원인 fully connected layer를 지나서 마지막 분류기를 학습시킵니다.
이때 dropout 규제를 적용합니다.(p=0.9) -
Fine-tune top 3 layers.
2개의 fully connected layers까지 포함하여 마지막 3개 층을 학습시킵니다.
이때 dropout 규제를 적용합니다.(p=0.9) -
Fine-tune all layers.
기존에 학습된 모델의 가중치를 초기값으로 사용하여 신경망의 모든 층을 재학습시킵니다. -
Train from scratch.
베이스라인을 위해, UCF-101 데이터 셋으로 모델을 무작위로 초기화된 가중치로 학습시킵니다.
Results.
분류를 위한 UCF-101 데이터를 준비하기 위해, 각 모든 영상으로부터 50개의 클립을 샘플링하고 Sports-1M 데이터와 같은 evaluation 프로토콜을 따랐습니다.
본 논문은 UCF-101 영상들의 YouTube ID를 얻기 위해
"UCF101: A dataset of 101 human actions classes from videos in the wild."
논문의 저자들에게 연락했습니다.
그러나 안타깝게도 해당 ID들은 제공되지 않았으며, Sports-1M 데이터셋이 UCF-101 데이터 셋과 겹치지 않는다고 보장할 수 없다고 언급합니다.
하지만 이러한 우려는 어느 정도 완화되는 부분이 있습니다.
각 영상에서 일부 샘플 클립만 사용하기 때문입니다.
UCF-101 실험에 적용할 신경망은 Slow Fusion 신경망을 사용합니다.
이는 Sports-1M에 대해 가장 좋은 성능을 보였기 때문입니다.
결과 표를 첨부합니다.

흥미롭게도, softmax 층 혼자만 재학습한 경우, 성능이 좋지 못했습니다. 아마도 고수준 특징들이 너무 스포츠에 맞춰져 있기 때문에 그럴 것입니다.
그리고 모든 층을 전부 fine-tuning하는 극단적인 경우 또한 적절하지 못하다고 합니다, 이는 과대적합 때문입니다.
그래서 이것들의 균형잡힌 경우, 상위 몇개의 층만 fine-tuning한 경우가 제일 좋은 성능을 보였습니다.
마지막으로, 베이스라인으로 준비했던 Train from scratch 경우는 막대한 과대적합으로 인해 최악의 성능을 보였습니다.
Performance by group.
더 나아가서, UCF101 데이터셋에 포함된 5개의 큰 범주 그룹별로 성능을 더 세분화하여 분석해봅니다.
모든 클래스에 대해 average precision(AP)를 계산하고 각 그룹 내 클래스에 대해 mean average precision(mAP)을 계산합니다.
표를 보겠습니다.
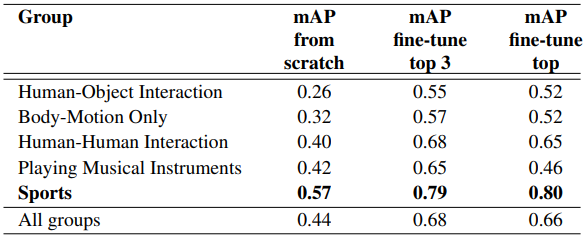
성능 중 많은 비율이 UCF-101 내의 스포츠 카테고리에서 기인합니다.
모델이 Sports-1M 데이터로 훈련되었지만, 노이즈 덕분에 비스포츠 클래스의 예제들도 일부 접할 수 있었고, 이 덕분에 다른 그룹들도 인상적인 성능을 보여주고 있습니다.
게다가, 최상위 계층 하나만 재학습하는 것에서 상위 3개 계층을 재학습할 때의 성능 향상은, 거의 전적으로 스포츠가 아닌 카테고리에서 기인합니다.
오직 스포츠 카테고리만이 0.80에서 0.79로 약간 감소했네요.
5. Conclusions
지금까지 large-scale 영상 분류에서의 CNN 성능에 대한 연구였습니다.
CNN구조가 약하게 라벨링된 데이터로부터도 강력한 특징을 학습할 수 있음을 발견했습니다. 이러한 특징은 기존의 특징 기반(feature-based) 방법들보다 훨씬 뛰어난 성능을 보여줍니다.
그리고 모델의 시간적 연결성에 크게 좌우되지 않고 놀라울 만큼 강건하다는 점 또한 알 수 있습니다.
위에서의 결과는 모델의 시간적 연결성에 성능이 크게 민감하지는 않지만,
Slow Fusion 모델이 Early Fusion과 Late Fusion 모델보다 지속적으로 더 좋은 성능을 낸다는 점을 보여줍니다.
놀랍게도, single-frame 모델도 이미 매우 강력한 성능을 보여준다는 것을 발견했고,
이는 스포츠처럼 다이나믹한 데이터셋에서도 local한 motion 정보가 무조건적으로 중요하지 않을 수 있음을 시사합니다.
그러나 카메라 움직임을 더 정밀하게 처리할 필요는 있을 것이라고 하는데요. 그러려면 CNN 구조를 크게 바꿔야하기 때문에 이는 향후 연구로 남겨두겠다고 언급합니다.
그리고 CNN 모델의 속도 향상을 위해 저해상도와 고해상도 stream으로 구성된 multiresolution 구조를 소개했습니다. 이는 정확도를 손해보지 않으면서 속도를 높이는 효율적인 방법이었습니다.
transfer learning을 통해, 학습된 특징들은 충분히 다른 영상 분류 작업에 대해서도 일반화하여 적용할 수 있다고 강조합니다.
앞으로의 연구에서는,
더 넓은 범주의 데이터를 포함시켜서 더욱 강력하고 일반화된 특징을 얻고,
카메라 움직임을 명시적으로 고려하는 방법을 탐구할 것입니다.
또한 클립 수준 예측을 글로벌한 영상 수준 예측으로 결합하기에 더 강력한 기법인 순환 신경망(RNN)을 활용하는 방향을 모색할 계획이라고 언급하며 논문이 마무리됩니다.
Opinion
이렇게 논문 리뷰가 끝났습니다.
마지막에 또 다시 RNN이 언급되네요. 2014년에 나온 논문이라 이미 RNN을 활용하여 연구한 논문이 나왔을 것이라고 예상합니다. 앞으로 읽을 논문은 모두 영상 관련 딥러닝 논문입니다. 타임라인을 따라가며 천천히 공부해 볼 생각입니다. 본 논문에서 제공하는 공식 코드가 없어서 조금 아쉽긴 합니다만, 직접 구현해서 실험해 볼 가치는 있다고 생각합니다.
이상으로 논문 리뷰 마칩니다.
감사합니다.
